5 Million Users a Day From Snowflake to Iterable

Team RudderStack
Posted on January 12, 2022

When you set up your data stack with a warehouse first approach, RudderStack's versatile nature allows you to overcome certain hurdles that were once too expensive or too difficult. This flexibility was on full display as we recently helped a customer solve one of these challenges.
The situation: bulk subscription enrollment
One of our customers has a business use-case for sending 5 million users from Snowflake to Iterable once a day for customer engagement campaigns. If you think this is an obvious case for reverse-ETL, you're correct. Using RudderStack's reverse-ETL tool, this customer can extract the 5 million users from the Snowflake table, and then activate them into Iterable so they can get triggered to receive emails. Simple as that!
The problem: rate limits and process time
The blog doesn't end here, so you can probably guess it was not as simple as that. There were a couple of road-blocks that made this seemingly simple integration difficult.
- The Iterable endpoint they were hitting via RudderStack was the events/track endpoint. This particular endpoint has a yearly rate limit that would be exhausted after a couple weeks at the ~5 million/day rate.
- A ~5 million row reverse-ETL job would take quite some time to process, perhaps 10-15 hours. To repeat this everyday would become quite consuming.
The solution: webhook, transformations, and reverse ETL
We started with hurdle #1. The events/track endpoint was not ideal to use. The customer found that Iterable has another endpoint lists/subscribe where you can subscribe multiple users at once to a list, which can trigger an email to be sent to them. This worked well for the customer's needs, and it had a much more lenient rate limit.
RudderStack doesn't support this endpoint in the Iterable destination. Fortunately, we can use the powerful custom webhook destination and point it to the lists/subscribe endpoint. And using a user transformation we can transform the payloads into the required format for Iterable. We were now over the first hurdle!
For hurdle #2, we still had to deal with the performance issue of running a ~5 million row reverse-ETL job everyday. Because this new endpoint can receive a list of users, rather than just a single user at a time, we shifted our focus to figuring out how to batch user lists in the warehouse to reduce reverse-ETL job sizes by 500x.
Technical deep dive: in the warehouse
This is where the magic started. Because RudderStack's reverse-ETL tool is able to extract from a Snowflake view, we wrote a query to make a view. The query takes the users from the 5 million row user table and creates a view where 500 users are batched into a single row. Now, instead of having 5 million rows to run the reverse-ETL job for, there are just 10 thousand. An example below shows how this query can take multiple rows of data and transform it into a single row.
create or replace view "DB_NAME"."SCHEMA_NAME"."VIEW_NAME" as (
select list_id
,'[' ||
listagg( distinct '{"email":"' || email
|| '", "userId": "' || ID
|| '", "dataFields": ' || content
|| '}', ',')
within group (order by 1)
|| ']'
as subscribers_list
,min(row_id) as first_row
,max(row_id) as last_row
,TO_CHAR(current_date, 'YYYYMMDD') ||
to_Char(current_time(), 'HHMI') ||
'_' || list_id ||
'_' || batch as row_id
from (
select ROW_NUMBER() OVER (order by list_id, 1) as row_id
,truncate ((row_id/500)) + 1 as batch
,email as email, list_id
,to_varchar(object_data) as content
from DB_NAME.SCHEMA_NAME.USER_TABLE_NAME
where list_id is not null
order by row_id
) b
Group by batch, list_id
order by 1, first_row
)
The Users Table
| id | object_data | list_id | |
|---|---|---|---|
| 1nkd9a3 | dummy@email.com | { "country": "USA", "sport": "basketball" } | 1 |
| 10fmvd7e | sample@email.com | { "country": "Japan", "sport": "baseball" } | 1 |
| 8dhcu6sk | not@email.com | { "country": "England", "sport": "soccer" } | 1 |
The New View (After using the query above)
| list_id | subscribers_list | first_row | last_row | row_id |
|---|---|---|---|---|
| 1 | "[ { "userId": "1nkd9a3", "email": "dummy@email.com", "dataFields": { "country": "USA", "sport": "basketball" } }, { "userId": "10fmvd7e", "email": "sample@email.com", "dataFields": { "country": "Japan", "sport": "baseball" } }, { "userId": "8dhcu6sk", "email": "not@email.com", "dataFields": { "country": "England", "sport": "soccer" } } ]" | 1 | 3 | 202112221242_1_1 |
Diving deeper into the view query, there are a couple things to point out.
- The part of this query doing the bulk of the work is the listagg() function. This compiles all of the necessary information for the Iterable API endpoint and stores it as a JSON array in a string format. When we run the reverse-ETL, we can use a user transformation in RudderStack to turn this back into a JSON array of objects (example towards the end of this blog).
-
truncate ((row_id/500)) + 1This line is responsible for creating the size limits of the batches. 500 here represents the largest number of users a single row can contain. Therefore, if you have a user list of 1300 users, this query will create a view with 2 rows that contains 500 users each and then a third row with only 300. - This query will also batch users based on their list_id. Only users with like list_id's will be compiled in a single row. This allows us to handle multiple lists per day for the
list/subscribe endpoint.
Technical deep dive: in RudderStack
With the heavy lifting done in the warehouse, we just needed to create a source and destination in RudderStack.
We created a Snowflake source, selected the permissions we wanted, and then chose the sync frequency. After the source was created, we navigated to the created Snowflake source and clicked on "Create New Destination".

We then created the Webhook Destination, filled out the correct endpoint, and included the proper authorization header.
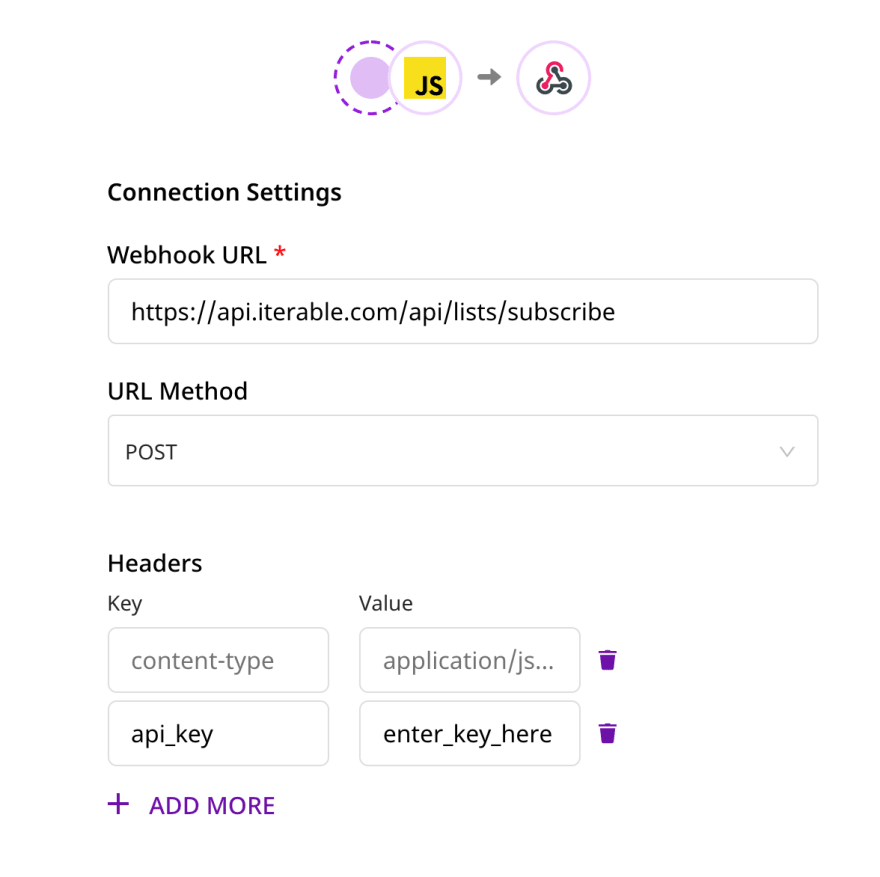
After clicking "Next", we chose which table we wanted to perform the reverse-ETL for by selecting the Schema and the Table. Then, we chose the unique ROW_ID to be the "user_id" and selected to bring in all the table columns.

Finally, we created a user transformation so these payloads can be formatted for Iterable.
Below, you can see how these payloads looked coming into RudderStack from the reverse-ETL.
{
"type": "identify",
"traits": {
"LIST_ID": 1,
"LAST_ROW": 3,
"FIRST_ROW": 1,
"SUBSCRIBERS_LIST": "[{ \"userId\":\"1nkd9a3\",\"email\":\"dummy@email.com\",\"dataFields\":{ \"country\":\"USA\",\"sport\":\"basketball\"}}, { \"userId\":\"10fmvd7e\",\"email\":\"sample@email.com\",\"dataFields\":{ \"country\":\"Japan\",\"sport\":\"baseball\"}}, { \"userId\":\"8dhcu6sk\",\"email\":\"not@email.com\",\"dataFields\":{ \"country\":\"England\",\"sport\":\"soccer\"}}]"
},
"userId": "202112221242_1_1",
"channel": "sources",
"context": {
"sources": {
"job_id": "21HbSd8lPbwhdakjfdhakjfhdakj/Syncher",
"task_id": "QRY_USER_LIST",
"version": "v1.7.2",
"batch_id": "2afdsa10f-a7d7-471f-96c8-68dsad291cc",
"job_run_id": "c6dtccxasadsadng",
"task_run_id": "c6defeafeaef3no0"
}
},
"recordId": "30",
"rudderId": "d47abfd7-37b3-43fa-81a7-bced4a91a2c3",
"messageId": "f80a4436-a6a5-4b46-9e8c-ac3a6edb67ff"
}
The user transformation below, transforms the payloads into the proper format for the lists/subscribe endpoint.
export function transformEvent(event, metadata) {
event.type = 'track'
event.listId = event.traits.LIST_ID
event.subscribers = JSON.parse (event.traits.SUBSCRIBERS_LIST)
event.preferUserId = true // Refer to Iterable Docs
delete event.traits
delete event.userId
delete event.channel
delete event.rudderId
delete event.messageId
delete event.context
delete event.recordId
return event;
}
Here is what the transformed payload looked like.
[
{
"type": "track",
"listId": 1,
"subscribers": [
{
"userId": "1nkd9a3",
"email": "dummy@email.com",
"dataFields": {
"country": "USA",
"sport": "basketball"
}
},
{
"userId": "10fmvd7e",
"email": "sample@email.com",
"dataFields": {
"country": "Japan",
"sport": "baseball"
}
},
{
"userId": "8dhcu6sk",
"email": "not@email.com",
"dataFields": {
"country": "England",
"sport": "soccer"
}
}
],
"preferUserId": true
}
]

Conclusion
Now the 5 million users from the warehouse table user-list are successfully being extracted from the warehouse, transformed through RudderStack, and then sent to Iterable, so all the users can receive the proper emails. This streamlined process can now be repeated day after day and will not take hours to complete.
Wins
- Minimized the amount of records in the reverse-ETL from 5 million to just 10 thousand
- The reduction in volume reduced the process time from several hours to 30 minutes
- The reduction in volume relieved the concern of maxing out the api limits set by the destination
- RudderStack's Webhook Destination enabled us to send events to a more opportune endpoint
- User Transformations made it easy to ensure that our payload matched exactly how Iterable needed the data
Posted on January 12, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related