ConvNext : A ConvNet for the 2020s (Part I)

Rohit Gupta
Posted on February 28, 2022

The goal of the paper is to modernize the ResNet and bring back the glory to CNNs ;)
In other words, they tried to apply the concepts of Transformers to ResNet like archtitecture and make them better. They individually applied ideas and showcased how much of an improvement it shows.
 .
.
They compared the impact on 2 things : Accuracy and Computation.
Finally they reached the conclusion that following Changes enhances the results :
-Large Kernel Size(7*7).
-Replace ReLu with GeLu
-Fewer Norm Layers
-Substitute BatchNorm with LayerNorm
-Inverted Block
-Grouped Convs reduces computation
-Add a "patchify layer"(to split an image into sequence of patches)
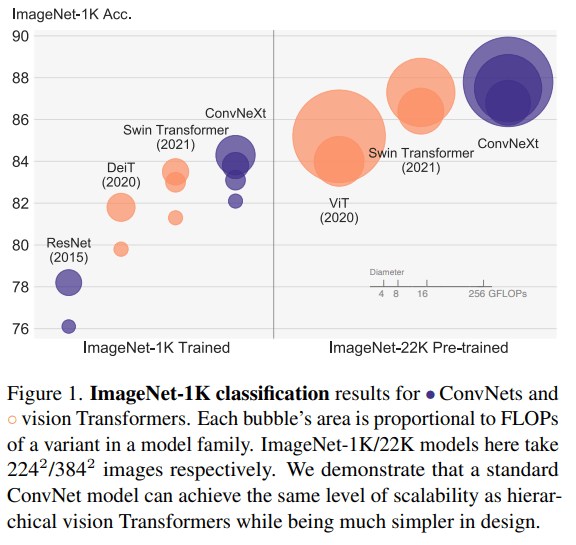
Below Image shows the comparison of ResNet, ViT with ConvNext. Diameter shows the Computation Power needed, hence more bigger the circle is, more computationally expensive model will be.
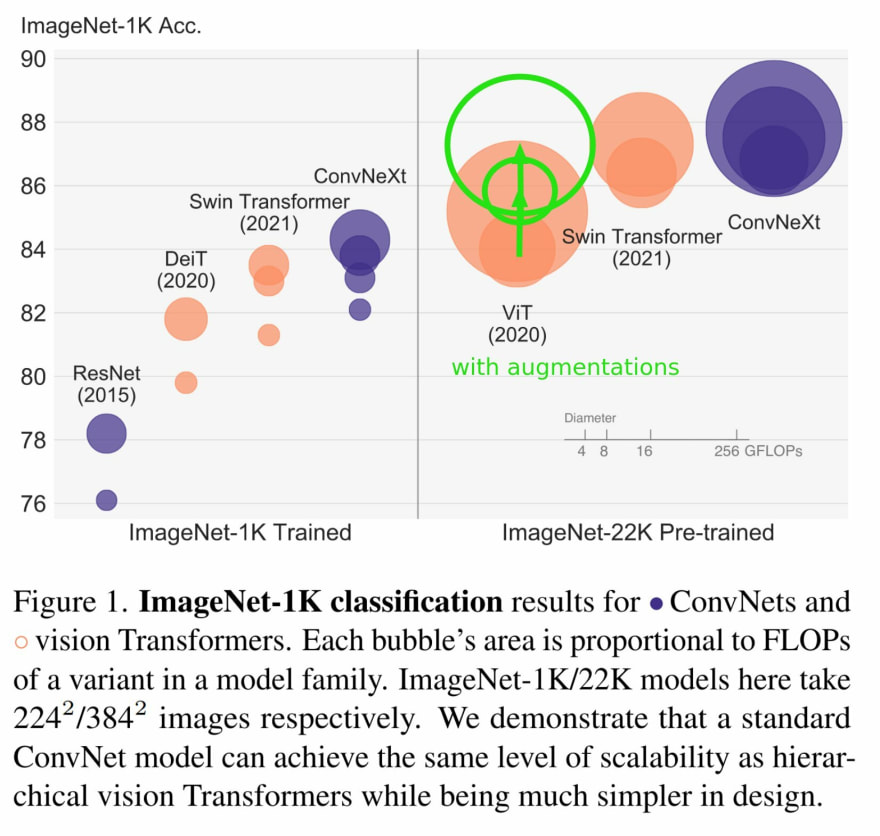
If augmentationare applied on ViT model, than comparison goes like this :
A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this
exploration is a family of pure ConvNet models dubbed ConvNeXt.
Also, another quote from paper is very good :
The full dominance of ConvNets in computer vision was
not a coincidence: in many application scenarios, a “sliding
window” strategy is intrinsic to visual processing, particularly when working with high-resolution images. ConvNets have several built-in inductive biases that make them well suited to a wide variety of computer vision applications. The most important one is translation equivariance, which is a desirable property for tasks like objection detection. ConvNets are also inherently efficient due to the fact that when used in a sliding-window manner, the computations are shared.
Translational Equivariance or just equivariance is a very important property of the convolutional neural networks where the position of the object in the image should not be fixed in order for it to be detected by the CNN. This simply means that if the input changes, the output also changes.
The property of translational equivariance is achieved in CNN’s by the concept of weight sharing. As the same weights are shared across the images, hence if an object occurs in any image it will be detected irrespective of its position in the image. This property is very useful for applications such as image classification, object detection, etc where there may be multiple occurrences of the object or the object might be in motion.
For more information on Translational Equivariance : Follow this Article
Details of Paper :
ResNet-50 is trained like Transformers but with 1.More Epochs,2.Image Augmentation,and 3.AdamW.
Researchers used a training recipe that is close to DeiT’s and
Swin Transformer’s. The training is extended to 300 epochs from the original 90 epochs for ResNets. We use the AdamW optimizer, data augmentation techniques such as Mixup, Cutmix, RandAugment, Random Erasing, and regularization schemes including Stochastic Depth and Label Smoothing.
Adding Patchify Layer : Researchers have replaced the ResNet-style stem cell with a patchify layer implemented using a 4×4, stride 4 convolutional layer. The accuracy has changed from 79.4% to 79.5%. This suggests that the stem cell in a ResNet may be substituted with a simpler “patchify” layer like ViT.
ResNeXt-ify : The use of depthwise convolution effectively reduces the network FLOPs and, as expected, the accuracy. Following the strategy proposed in ResNeXt, we increase the network width to the same number of channels as Swin-T’s (from 64 to 96).This brings the network performance to 80.5% with increased FLOPs.
More to come soon.
Official Paper Link
Awesome Video Explanation
That's all folks.
If you have any doubt ask me in the comments section and I'll try to answer as soon as possible.
If you love the article follow me on Twitter: [https://twitter.com/guptarohit_kota]
If you are the Linkedin type, let's connect: www.linkedin.com/in/rohitgupta24
Happy Coding and Have an awesome day ahead 😀!
Posted on February 28, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related