How AI Learns to Play Games

Rodolfo Mendes
Posted on June 3, 2019

Over the past few years, we've seen computer programs winning games which we believe humans were unbeatable. This belief held considering this games had so many possible moves for a given position that would be impossible to computer programs calculate all of then and choose the best ones. However, in 1997 the world witnessed what otherwise was considered impossible: the IBM Deep Blue supercomputer won a six game chess match against Gary Kasparov, the world champion of that time, by 3.5 - 2.5. Such victory would only be achieved again when DeepMind's AlphaGo won a five game Go match against Lee Sedol, 18 times world champion, by a 4-1 score.
Credit: Roger Celestin/Newscom

The IBM Deep Blue team relied mostly on brute force and computation power as their strategy to win the matches. Equipped with thousands of VLSI chips, specially designed to evaluate chess positions, the Deep Blue was capable to evaluate 200 millions of positions per second. Additionally, the Deep Blue software had a database of more than 4,000 openings and more than 700,000 games from grandmasters.

However, a brute-force strategy is not feasible to play Go, due to the much higher number of possible movies. Instead, the DeepMind had to make AlphaGo more intelligent in order to prevent all those calculations. The version that played against Lee Sedol combined machine learning and tree search techniques, as well as few heuristics to detect specific game patterns as the nakade, for example. Initially the algorithm was trained with games played by humans, and after reaching some proficiency, it started to learn by playing against other instances of itself. After winning the match against Sedol, the DeepMind team continued improving AlphaGo, and its latest version called AlphaZero was trained only by playing against itself.
After the success achieved with AlphaGo, DeepMind, OpenAI and other research companies started to work in even more complex games, like Starcraft2 and Dota2. So, how can computer programs can learn to play this games, with professional proficiency? These incredible achievements were possible applying a powerful artificial intelligence technique called reinforcement learning.
What is reinforcement learning?
Reinforcement learning is an artificial intelligence paradigm in which an intelligent agent learns to execute tasks by trial and error, interacting with the environment. Instead of learning from a labeled dataset, like in supervised learning, in reinforcement learning the agent obtain information about the environment, performs an action based on this information and then receives a reinforcement signal to indicate if the action was correct.
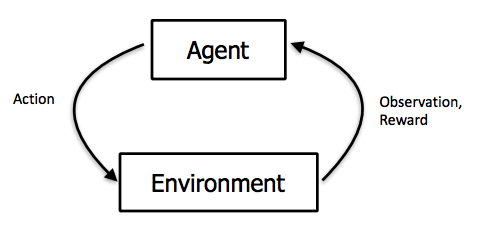
For example, suppose we want to teach a robot to walk in a room without hitting the walls. Using different types of sensors we can collect information about the environment, like the distance between the robot and the walls and the speed of the robot in different directions. In order to indicate to the agent that it is performing the task correctly, we must be able to encode reward signals to be read together with the states. We could do this by rewarding a step in any direction with a +1 signal and penalizing the agent with a -1 signal when a collision is detected. So, put in a very simple way, what a reinforcement learning agent does is to record the rewards received by the actions so it can learn which are the best ones to choose given its current state.
Conclusion
Along the decades, Reinforcement Learning has been shown a very powerful machine learning paradigm and has been applied to create intelligent robots, chatbots, trading bots, autonomous vehicles and other areas that require automation and optimization. Complex games like Chess, Go and more recently Starcraft2 and Dota2 have been used by researchers as benchmarks to establish the current state-of-the-art algorithms for Reinforcement Learning.
If you're interested in going deep in Reinforcement Learning, check our post Top 5 Courses in Reinforcement Learning, to have a list of 5 free courses offered by the top of mind companies and universities. In future posts, we're going to explore the elementary concepts of Reinforcement Learning through the Frozen Lake game example.
Original post: How AI Learns to Play Games
Posted on June 3, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
January 11, 2024
