
Shawn Adams
Posted on September 6, 2019
One of the main hindrances to getting value from our data is that we have to get data into a form that’s ready for analysis. It sounds simple, but it rarely is. Consider the hoops we have to jump through when working with semi-structured data, like JSON, in relational databases such as PostgreSQL and MySQL.
JSON in Relational Databases
In the past, when it came to working with JSON data, we’ve had to choose between tools and platforms that worked well with JSON or tools that provided good support for analytics. JSON is a good match for document databases, such as MongoDB. It’s not such a great match for relational databases (although a number have implemented JSON functions and types, which we will discuss below).
In software engineering terms, this is what’s known as a high impedance mismatch. Relational databases are well suited for consistently structured data with the same attributes appearing over and over again, row after row. JSON, on the other hand, is well suited for capturing data that varies content and structure, and has become an extremely common format for data exchange.
Now, consider what we have to do to load JSON data into a relational database. The first step is understanding the schema of the JSON data. This starts with identifying all attributes in the file and determining their data type. Some data types, like integers and strings, will map neatly from JSON to relational database data types.
Other data types require more thought. Dates, for example, may need to be reformatted or cast into a date or datetime data type.
Complex data types, like arrays and lists, do not map directly to native, relational data structures, so more effort is required to deal with this situation.
Method 1: Mapping JSON to a Table Structure
We could map JSON into a table structure, using the database's built-in JSON functions. For example, assume a table called company_regions maintains tuples including an id, a region, and a country. One could insert a JSON structure using the built-in json_populate_record function in PostgreSQL, as in the example:
INSERT INTO company_regions
SELECT *
FROM json_populate_record(NULL::company_regions,
'{"region_id":"10","company_regions":"British Columbia","country":"Canada"}')
The advantage of this approach is that we get the full benefits of relational databases, like the ability to query with SQL, with equivalent performance to querying structured data. The primary disadvantage is that we have to invest additional time to create extraction, transformation, and load (ETL) scripts to load this data—that’s time that we could be analyzing data, instead of transforming it. Also, complex data, like arrays and nesting, and unexpected data, such as a a mix of string and integer types for a particular attribute, will cause problems for the ETL pipeline and database.
Method 2: Storing JSON in a Table Column
Another option is to store the JSON in a table column. This feature is available in some relational database systems—PostgreSQL and MySQL support columns of JSON type.
In PostgreSQL for example, if a table called company_divisions has a column called division_info and stored JSON in the form of {"division_id": 10, "division_name":"Financial Management", "division_lead":"CFO"}, one could query the table using the ->> operator. For example:
SELECT
division_info->>'division_id' AS id,
division_info->>'division_name' AS name,
division_info->>'division_lead' AS lead
FROM
company_divisions
If needed, we can also create indexes on data in JSON columns to speed up queries within PostgreSQL.
This approach has the advantage of requiring less ETL code to transform and load the data, but we lose some of the advantages of a relational model. We can still use SQL, but querying and analyzing the data in the JSON column will be less performant, due to lack of statistics and less efficient indexing, than if we had transformed it into a table structure with native types.
A Better Alternative: Standard SQL on Fully Indexed JSON
There is a more natural way to achieve SQL analytics on JSON. Instead of trying to map data that naturally fits JSON into relational tables, we can use SQL to query JSON data directly.
Rockset indexes JSON data as is and provides end users with a SQL interface for querying data to power apps and dashboards.
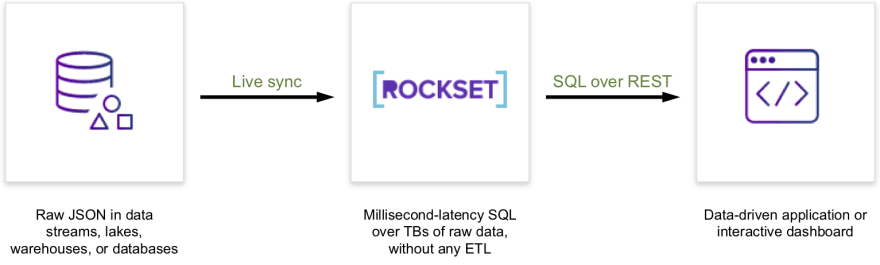
It continuously indexes new data as it arrives in data sources, so there are no extended periods of time where the data queried is out of sync with data sources. Another benefit is that since Rockset doesn’t need a fixed schema, users can continue to ingest and index from data sources even if their schemas change.
The efficiencies gained are evident: we get to leave behind cumbersome ETL code, minimize our data pipeline, and leverage automatically generated indexes over all our data for better query performance.
Posted on September 6, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



