
Ritikesh
Posted on December 13, 2019

Originally published on Freshworks’ official Blog on November 15, 2019
Freshworks’ IT service management tool Freshservice enables organizations to simplify IT operations. Freshservice provides ITIL-ready components that help administrators manage assets, incidents, problems, change, and releases, and theasset management component helps organizations exercise control over their IT assets.
Freshservice is powered by Ruby on Rails.
Nginx passenger-backed servers are hosted on the EC2 instances of AWS. The servers are hosted on four data centers — US East (US), Europe Central (EUC), India (IND), and Australia (AU).
UTF8 in MySQL
Our databases and the underlying tables were all created with utf8 encoding to ensure that a majority of characters are supported at the database level as well. However, MySQL’s “utf8” encoding only supports three bytes per character. The real UTF-8 encoding needs up to four bytes per character. This bug was never fixed. A workaround was released in 2010: a new character set called “utf8mb4”. For more on the MySQL and UTF8 story, you can read “In MySQL never use utf8” blog post.
Emojis in Freshservice — the Rails 3 way
Emojis are valid UTF8 characters and require 4 bytes to be stored and retrieved. However, with the above-specified limitation from MySQL’s native UTF8 encoding, we could not natively support all emojis. To process them, we were relying on an open-source gem called gemoji-parser. The gem allowed serialization of the emoji content by tokenizing emojis into an associated textual representation and de-tokenizing them later. To safely create tickets that contained emoji content, we parsed the email contents to detect emojis tokenized every ticket’s description and notes’ content before saving. We did not de-tokenize emojis when displaying ticket information (for performance reasons and because customers didn’t mind it); therefore, the tickets contained the emojis in their textual representation. For example, “😀” was rendered as “😀”.
While things worked with our set up on Rails 3, there were some known challenges:
- The gem was severely outdated. A lot of emojis didn’t work well with the gem and were saved in an unreadable format (such as, ‘\xF0\x9F\x98\x81…’), causing the ticket’s layout to be broken. This required us to fix it manually by going over the ticket’s description and cleaning up unreadable text/HTML parts. Patching or updating the gem regularly with new emojis wasn’t a feasible long term solution.
- There was a performance overhead to tokenize email content, ticket descriptions, and note content.
- There was a possible future performance overhead if we rendered emojis as-is by de-tokenizing the saved subject and description for every ticket in the ticket list and details page views.
Emojis in Rails 4
The Rails 4 framework had internally updated the MySQL session variables and enforced Rails-MySQL to run in strict mode. For information on why Rails enforced this, see “Use strict mode in mysql”. The tables were created with a utf8 charset and Unicode collation and MySQL raised errors (Incorrect string value: ‘\xF0\x9F\x98\x81…’ for column description at row 1) when any invalid content (in this case, an emoji) was inserted into the tables. This was an indispensable concern for the Freshservice team because any content containing emojis would be discarded by the system. We decided to explore the possible solutions to this problem.
There were a couple of ways to address this. The first option was to convert all the rich-text fields into “serializable fields” in Rails. Rails internally uses YAML for serializing data and the default YAML parsers were capable of serializing emojis as well. However, this had a few concerns. Changing the fields to “serialized” would require us to run a data correction script for all our existing records as they would not be parseable as YAML. Secondly, we were simply moving the serialisation-deserialisation overhead from database writes to database reads, which was much worse.
The other option was to make Rails and MySQL run completely with the utf8mb4 encoding set. However, we have hundreds of tables across shards on multiple data centers and migrating all the tables wasn’t feasible considering the scale at which Freshservice operates. Also, utf8mb4 (4 bytes) columns occupy more space than the traditional utf8 (3 bytes) columns, and database indexes have a length limit of 767 bytes. This meant that any table having indexes with varchar(255) columns would cause problems because the index that previously occupied 255*3 = 765 bytes would now occupy 255*4 = 1020 bytes. This implied that we would have to change the columns’ length in the index (not a feasible solution for all our use cases) or update the innodb large_prefix value and reindex all our data. Updating indexes, either way, would have taken far too much time and wasn’t worth the effort.
We decided to test a more reactive approach. We evaluated running Rails in utf8mb4 mode without migrating any database columns. This meant that we could set Rails level encoding to utf8mb4 and migrate only specific columns of some of our tables to accept utf8mb4 content and extend the behavior to other modules or tables in the future.
To set Rails to run in utf8mb4, we must update the encoding key in database.yml as follows:
Most of our apps’ emoji content comes from two sources: email and mobile. While mobile as a channel is still under utilised, the same cannot be said for email. The email channel is primarily used to create tickets and add notes to existing tickets. Emails are also used to create solution articles (as a draft) and add notes to other modules such as Change, Problem, and Release. For the first cut, we decided to support emojis for tickets and solution articles (higher chances of adding rich content). We ran a benchmarking exercise to check if there was any performance impact of this activity. The benchmarking results were as follows:
As one can see, there was very little difference in terms of performance (~ +0.5ms/ticket for a ~20KB string as the ticket’s description) between the various scenarios. Even though benchmarks are just a means of approximation, this approximation was good enough for us to continue.
The migration
We knew that the migration would take a while because it involved tickets and notes (some of our biggest tables in MySQL), and chose to do it during the holiday season.
On Christmas eve, we began altering the tables in the EUC data center first. We used LHM (Large Hadron Migration — a tool that allows us to perform database migrations online while the system is live, without locking the tables) because the production environment had significantly large data sizes. We also ensured that all our databases had significant space available as LHM duplicates entire tables during the migration and we were dealing with large tables. We finished EUC, IND, and AU data centers around Christmas eve and started planning for the US data center migration, which was the most complex one. Before beginning with the US data center migration, we enabled utf8mb4 on Rails in all the previously migrated data centers and tested to ensure that there were no production-only surprises(😉) in store for us. After this, we began running migrations in the US data center on the weekend before the new year (as traffic was at its lowest) and finished the entire process around midnight of Jan 02.
Considering the load and size of the data involved, we had to continuously monitor the migrations and handle scenarios that were expected to happen only in production. For instance, LHM usually does a full scan of data from min(PKEY) — max(PKEY). Our database is based on a sharded multitenant architecture where a tenant and all its data reside in a single database shard. Each tenant has unique IDs for all entities across all shards. Some of the new shards had some stale database entries with min(PKEY) as 1 and max(PKEY) in billions. When we began noticing that some of our shards were taking longer to process, we investigated the issue and found the stale entries causing unnecessary scans for millions of records that weren’t even present in the system. We did a full clean up of such stale entries and this helped to reduce the LHM scan durations significantly.
After a 10-day effort, emojis support was successfully rolled out on all data centers for tickets (subject and description), notes (body), and solution articles (title and description).
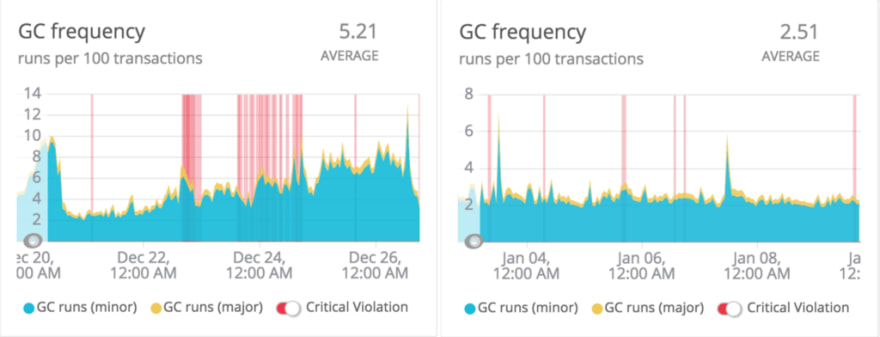
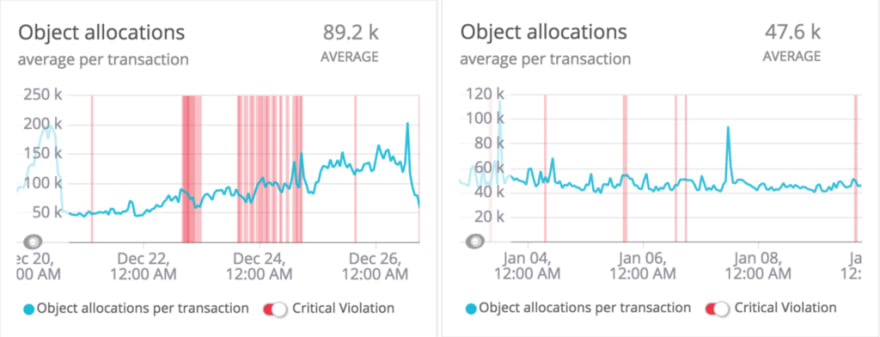
Post deployment, there was a visible impact on garbage collection (GC) and object allocations, as a result of removing the costly tokenizations for every save or update.
GC analysis
Object allocation analysis
Key takeaways
- Understanding benchmarks: benchmarks should just be used for references. We should not rely too much on them, especially when working with large scale migrations. Our benchmarking exercise indicated an increase in the processing time but ultimately it was not the case. There was a significant boost in performance due to the reduction in GC cycles and object allocations.
- Understanding production migrations: They are very complex and should be done with great care, especially when dealing with customer data. There is always that one surprise awaiting to show up only in production.
- Solving problems the hard (read clean) way comes with its own advantages.
PS:
Spread the love; start creating tickets on Freshservice with emojis.😎
Posted on December 13, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
