Re-Thinking Web APIs to be Dynamic and Run-Time Adaptable

Richard Schloss
Posted on April 2, 2020

Introduction
One of the most important aspects of all web applications is the Application Programming Interface (API), since it is the glue that allows the ends of a given communication channel to know exactly what to do. Because it is important for APIs to be robust, scalable and reliable, a lot of manual effort goes into maintaining static APIs. In fact, many tech companies set aside full-time roles just for designing and maintaining the APIs. There is only one problem that we clearly missed all these years: APIs were never supposed to be static.
It can be argued that a given web app is only as good as the data it is able to access and display. While we are fortunate to live in a world full of data sources, we only end up using the data sources we have access to (so, mathematically, probably works out to a very small percent of the world's data). Usually, each data source has its own unique API requirements, and this makes it a total drag whenever a new data source is to be used. Usually, it requires sufficient time allocation to read lengthy API docs, iterate over code that is only as robust as the API, and takes the developer away from other tasks on the backlog. This time and development cost can be incurred with every new incorporation of a data provider.
Even if an app only has to concentrate on a single source, such as it's own backend, existing API models can still make iterating unnecessarily time consuming. And I would argue, a web app that relies on only one data source can quickly become a very boring app, since more often than not, its users will require constant engagement and different kinds of stimuli.
Let's analyze what I perceive to be the most commonly used API model: (simplified greatly)

In this model, this is how I view it:
- The server owns the API, the client-side developer has to keep up to date with lengthy API docs
- The client makes requests, the server responds
- The client is expecting a single response, so if there is something that happens in the time that the server performs the requested service, it will not be communicated back to the client. No notifications in this model, just a response.
- The communication is uni-directional; requests go one way, responses go the other.
- When the server's API changes, all clients are blocked from communicating with the server until they update their request methods, unless the server provides access to previous versions. This is a terrible model because it's not reliable, or if it's reliable, it is costly because the server has to maintain all versions of code just so older clients can use it. Newer versions of code include bug fixes and other enhancements, so it may be counter-productive for a client to insist on using old buggy code anyway.
It may be much more beneficial to take a step back to really think about what our communication points on the web look like. This is illustrated in the next diagram. In the diagram, I still use the terms "server" and "client" because that's what everyone is still familiar with, but I would prefer the terms "IO node" for each point.

This picture zooms out of the previous model to think about many IO nodes on a given network. Here's how to view this model:
- Each line represents bi-directional IO
- Each client and server can be thought of as IO nodes
- Each IO node can emit or listen for events at any given time. Therefore, each node can have it's own API it wishes to expose at any given point in time. Yes, the client can have an API.
- Since those events are known at run-time, each side can communicate the events it can emit and listen for; i.e., each node can communicate its API. This means if a foreign IO node makes an appearance, indicated by "server 3", it can communicate its API to any or all nodes, and those nodes will know how to communicate with that new node, all without having prior knowledge of its API.
- More importantly though, each node can communicate its node type, so that if the two nodes are identical, they can be considered peers and it can be deduced that peers must already know each others APIs.
- This model is only as robust as the API format that all sides must have to agree on, but if the format is simple, it can work!
A small digression
I like to think of the client and server as being separated by great physical distances. Indeed this is already true as communication has to travel across long cables, bounce of satellites, etc. The response a client can get from a server should be expected to take some time. However, I like to take a bit more extreme view. I like to think of the client as someone traveling to a completely different planet, Mars or Pluto for example. That client will be even further away and for her to survive, she must constantly communicate back with IO servers back on Earth. In the years of her astronomic travels, more than likely both sides of this communication will morph in some way, and both sides will have to adapt to each others communication. Our beloved astronaut will not have the luxury of familiarizing herself with the latest API docs, she will simply have to make do with whatever the server sends her. What she observes as "latest API" will from Earth's perspective already be a few versions old (physics), so maybe if the server can maintain only a few prior versions, she'll have a chance at surviving.
This may be an extreme model, but one that can still apply to our web's constantly changing needs and APIs. And when the time comes to travel to distant planets, we'll be prepared.
The KISS Dynamic API Format
If I can reference an old, but worthy acronym from the 60s, "KISS", "The KISS principle states that most systems work best if they are kept simple rather than made complicated; therefore, simplicity should be a key goal in design, and unnecessary complexity should be avoided." -Wikipedia
This is the design goal for what I devised as the "KISS Dynamic API Format". If the high-level format description cannot fit onto a Post-it® note, it will have failed the KISS principle. At a high-level, the KISS format looks like this:
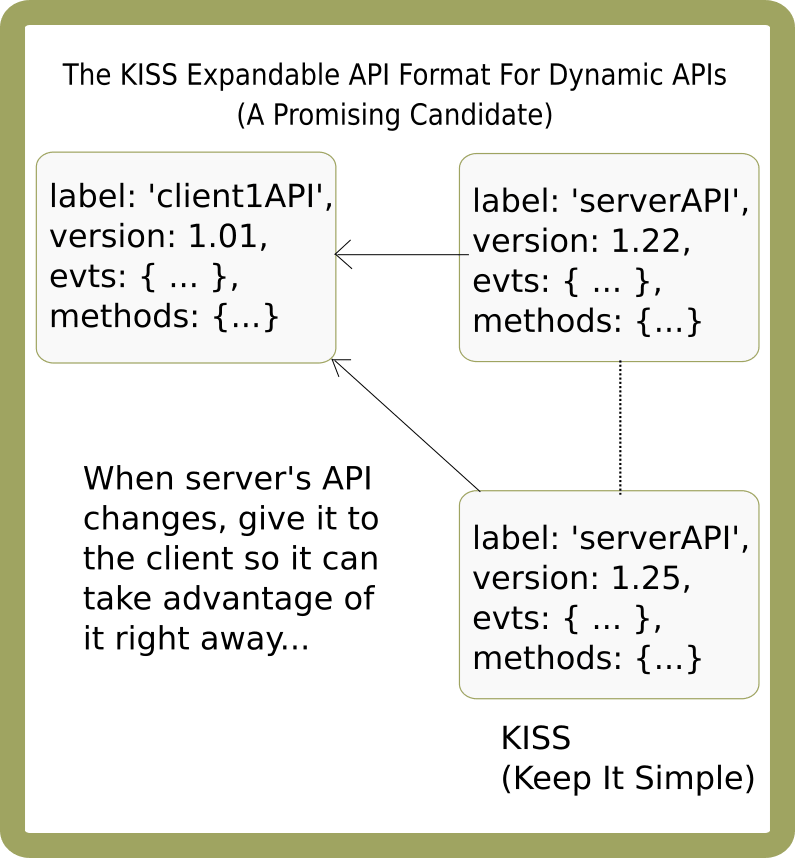
At the highest level, the format is simple: each IO node specifies it's label and version. If a given node communicating presents the same label and version as another node, it can be considered a peer, at which point, that node would not need any extra information. Peers already know each others abilities. Nodes that are not peers, however, would require more information: supported events and methods. (NOTE: the focus of this discussion is the IO model. A separate security model could possibly be implemented to help validate that IO nodes are who they say they are)
If any of the nodes evolve, they must update their API, and communicate this new API with an updated version. Then, an IO node receiving this information can choose to update its API cache if it detects a version mismatch.
If a label is not specified, the client will just have to rely on it's own alias to use for that API. Since the client already knows the domain, port, and namespace it is communicating with, it can be a straightforward manner for it to create whatever aliases it wants (e.g., apis['localhost:8080/chatRoom']). If a version is not specified, the client will always have to always assume a version mismatch and request the full API payload at the start of each new connection; i.e., the client won't be able to rely on or take advantage of an API cache. Therefore, while versioning is optional, it is highly recommended.
Each node can have its own set of events and methods. "evts" means the node will emit those events, while "methods" means the node will listen for those events (and run its own methods of the same names, respectively).
KISS: The "evts" format
Let's drill-down to the "evts" format, to see what it can look like: (again, must fit on a Post-it®)

Here, the "evts" will take the following form: A JSON object where the object properties are the event names, whose corresponding values are also optional JSON objects, but highly recommended. This makes it easy to write multiple events and keep things organized by event.
Each event name points to a JSON object containing the following optional, but highly recommended, properties:
- methods: an array of strings, each string represents the method name emitting that event. This makes it easy for the receiver to organize event data by method name, in case different methods emit the same event. If omitted, the receiver would have to cache the emitted data in a more general, less organized, way.
-
data: the schema that the client can expect to receive and use to validate incoming data. It is recommended that default values are used in the schema, since those values also indicate the data type (in Javascript,
typeof (variable)tells us the type for primitives). This makes for simpler and more readable code, in my opinion. - ack: a boolean indicating whether or not the emitted event expects to be acknowledged. (This may or may not be needed, to be explained in a follow up article. It may be useful to know however, if code is blocking while waiting for an ack, when an ack will never get sent).
KISS: An example using "evts" format

In this example, this API has label "mainServer" and is at version 1.02. It will emit the events "itemRxd" and "msgRxd". A client can expect that the methods emitting "itemRxd" will either be "getItems", "toBeAdded" or neither. It's up to the server to still specify the method that emitted that event so that the client can organize its data correctly. When the server emits "itemRxd", the client can expect the data JSON to contain "progress", which is specified as type Number (defaulted to 0), and the "item", which is specified as type Any (and defaulted to an empty object). In this way, both the type and the default value are represented in a simple and compact way. As time goes on, the server may wish to make "item" of type "Item", instead of "Any", to help the client validate each item (ex: Item schema = { name: '', description: '', unitCost: '' }).
Here is an example:
function getItems(msg){
socket.emit(
'itemRxd', // event: 'itemRxd'
{
method: 'getItems', // specify the method so the client can organize it.
data: {
progress: 0.25 // getItems method is 25% complete, notify the client...
item: { name: 'milk' }
}
}
}
The other event is "msgRxd". This entry doesn't specify any method, only the schema for the data. The client can expect to receive the "date" and the "msg". Since no methods are specified, the client can expect the event to come from any or all methods on the server.
KISS: The "methods" format
While the "evts" container describes the output of a given node, the "methods* describe the input to that node, and what the corresponding response can be. This is what the format can look like:

The format is a JSON object, where the properties represent the supported method names. Each method name points to a corresponding JSON object, which describes:
- msg: the message schema that the receiving node expects (a "msg" JSON object)
- resp: the response schema the node expects to respond with, if any. If the response specifies a schema surrounded by square brackets, that specifies an Array of that schema.
One potential benefit of providing these schemas in real-time could be automatic UI creation; that is, certain types could help determine what UI elements are best suited for those types, especially if the types are primitives. For example, if a given msg schema specifies String and Number types, the String types could translate to <input type="text" /> while Number types could translate to <input type="number" />. Entire form controls can probably be created on-the-fly in this manner. Likewise textual responses can probably be attached to <div class="resp"></div> elements. Styling could still largely be handled by CSS.
KISS: An example using "methods" format

In this example, the API specifies two methods, "getItems" and "getItem". The "getItems" does not specify a "msg" schema, so "msg" can be anything (or nothing) because it will be ignored. The method will only return an Array of type "Item". The Item schema is defined as a JSON object of "id", "name", and "desc", all empty strings (type String). The "getItem" method, however, specifies a "msg" schema, a JSON object with a property "id" and format String (defaults to an empty string). When the client calls this method, the server expects that the client will provide an id of the correct type (String). It will respond with type Item.
Conclusion
Presented here was a lengthy, but hopefully not too confusing, discussion of how APIs can be made dynamic, so that they can adapt to changes made by both sides of a communication channel. This will most likely be a very new concept for many people, so my next article will describe the exact implementation of this, which will release with nuxt-socket-io v1.0.22. That article will try to explicitly highlight the benefits using concrete examples. Expect pain points at first, because it is a learning curve, but I am hopeful we'll both glad after climbing the curve (yes, we're climbing the curve together).
Posted on April 2, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related