The Secret Life of Objects: Information Hiding

Riccardo Cardin
Posted on June 18, 2018

Originally posted on: Big ball of mud
I've been in the software development world for a while, and if I understood a single thing is that programming is not a simple affair. Also, object-oriented programming is even less accessible. The idea that I had of what an object is after I ended the University is very far from the idea I have now. Last week I came across a blog post Goodbye, Object Oriented Programming. After having read it, I fully understand how easily object-oriented programming can be misunderstood at many levels. I am not saying that I have the last answer to the million dollar question, but I will try to give a different perspective of my understanding of object-oriented programming.
Introduction
Probably, this will be the harder post I have ever written by now. It is not a simple affair to reason to the basis of object-oriented programming. I think that the first thing we should do is to define what an object is.
Once, I have tried to give a definition to objects:
The aim of Object-oriented #programming is not modeling reality using abstract representations of its component, accidentally called "objects". #OOP aims to organize behaviors and data together in structures, minimizing dependencies among them.
— Riccardo Cardin (@riccardo_cardin ) May 3, 2018
Messages are the core
In the beginning, there was procedural programming. Exponents of such programming paradigm are languages like COBOL, C, PASCAL, and more recently, Go. In procedural programming, the building block is represented by the procedure, which is a function (not mathematically speaking) that takes some input arguments and could return some output values. During its evaluation, a procedure can have side effects.
Data can have some primitive form, like int or double, or it can be structured into records. A record is a set of correlated data, like a Rectangle, which contains two primitive height and length of type double. Using C notation, the definition of a rectangle is the following.
struct Rectangle {
double height;
double length;
};
Despite inputs and outputs, there is no direct link between data (records) and behaviors (procedures). So, if we want to model all the operations available for a Rectangle, we have to create many procedures that take it as an input.
double area(Rectangle r)
{
// Code that computes the area of a rectangle
}
void scale(Rectangle r, double factor)
{
// Code that changes the rectangle r, mutating its components directly
}
As you can see, every procedure insists on the same type of structure, the Rectangle. Every procedure needs as input an instance of the structure on which executes. Moreover, every piece of code that owns an instance of the Rectangle structure can access its member values without control. There is no concept of restriction or authorization.
The above fact makes the procedures' definition very verbose and their maintenance very tricky. Tests become very hard to design and execute, because of the lack of information hiding: everything can modify everything.
The primary goal of object-oriented programming was that of binding the behavior (a.k.a. methods) with the data on which they operate (a.k.a., attributes). As Alan Kay once said:
[..] it is not even about classes. I'm sorry that I long ago coined the term "objects" for this topic because it gets many people to focus on the lesser idea. The big idea is "messaging" [..]
The concept of classes allows us to regain the focus on behavior, and not on methods inputs. You should not even know the internal representation of a class. You only need its interface. In object-oriented programming, the above example becomes the following class definition (I choose to use Scala because of its lack of ceremony).
trait Shape {
def area: Double
def scale(factor: Double): Shape
}
case class Rectangle(height: Double, length: Double) extends Shape {
// Definition of functions declared abstract in Shape trait
}
The example given is very trivial. Starting from elements height, length and procedures scale and area, it was very straight to derive an elegant object-oriented solution. However, is it possible to formalize (and, maybe to automate) the process we just did to define the class Rectangle? Let's try to answer this question.
Information hiding and class definition
We can begin with an unstructured set of procedures.
def scale(height: Double, length: Double, factor: Double): (Double, Double) = {
(height \* factor, length \* factor)
}
def area(height: Double, length: Double): Double = {
height * length
}
First of all, we notice that height and length parameters are present in both procedures. We might create a type for each parameter, like Height and Length. However, we immediately understand that the two parameters are always used together in our use cases. There are not procedures that use only one of the two.
So, we decided to create a structure to bind them together. We call such structure Rectangle.
type Rectangle = (Double, Double)
We also understand that a simple structure does not fit our needs. Rectangle internal should not be changed by anything else than the two procedures (forget for a moment that tuples are immutable in Scala). Telling the truth, we are interested only in the two procedures. So, we restrict the access to rectangle information only to the two procedures.
How can we do that? We should bind information of a rectangle with the behaviors associated with it. We need a class.
case class Rectangle(height: Double, length: Double) {
def scale(factor: Double): Rectangle = Rectangle(height * factor, length)
val area: Double = height * length
}
Well, taking into consideration only the use cases we have, we could stop here. The solution is already optimal. We hid the information of height and length behind our class; the behavior is the only thing client can access from the outside; clients that want to use a rectangle can interact only with the interface of the class Rectangle.
What if we want to support also shapes like squares and circles? Well, through the use of intefaces, that are types that are pure behavior, object-oriented programming allows our clients to abstract from the concrete implementation of a shape. Then, the above example becomes the following.
trait Shape {
def scale(factor: Double): Shape
def area: Double
}
case class Rectangle(height: Double, length: Double) extends Shape {
// Definition of functions declared abstract in Shape trait
}
case class Square(length: Double) extends Shape {
// Definition of functions declared abstract in Shape trait
}
case class Circle(ray: Double) extends Shape {
// Definition of functions declared abstract in Shape trait
}
As Wikipedia reminds us
Information hiding is the principle of segregation of the design decisions in a computer program that is most likely to change, thus protecting other parts of the program from extensive modification if the design decision is changed. The protection involves providing a stable interface which protects the remainder of the program from the implementation (the details that are most likely to change).
Information hiding and dependency degree
As anyone who follows me from some time knows, I am a big fan of dependency degree minimization between classes. I have developed a small theoretical framework that allows calculating the dependency degree of architecture. This framework is based on the number of dependencies a class has with other classes and on the scope of these dependencies, concerning a class life cycle.
I had already used my framework in other circumstances, like when I spoke about the Single-Responsibility Principle.
This time I will try to use it to sketch the process we just analyzed, whose goal is to aggregate information and related behaviors inside the same class, hiding the former to the clients of the class. I will try to answer the question _Why do height and length be collapsed inside one single type (which is incidentally called Rectangle)
Just as a recap, I defined in the post Dependency the degree of dependency between classes A and B as

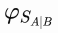 is the quantity of code (i.e., SLOC) that is shared between
is the quantity of code (i.e., SLOC) that is shared between
types A and B.  is the total number of code (i.e. SLOC) of
is the total number of code (i.e. SLOC) of
B class. Finally, 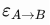 is a factor between 0 and 1 and the wider
is a factor between 0 and 1 and the wider
the scope between A and B, the greater the factor.
If Height and Lenght had been defined as dedicated types each, then a client C that needed to use a rectangle would always have to use both types. Moreover, the Rectangle type would still have been necessary, to put the methods area and scale. Using this configuration, Rectangle, Height and Length are said to be tightly coupled because they are always used together.
The degree of dependency of class C would be very high, using the above definition. Also, the degree of dependency of class Rectangle would be high too, due to references to Height and Lenght in the methods area and scale.
Probably, many class configurations can reduce the degree of dependency of the above example. However, the minimization of the value 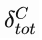 can be reached by the solution we gave in the previous paragraph.
can be reached by the solution we gave in the previous paragraph.
So, in some way, we started to trace a new way of design architecture, reducing in some way the art of design, to find an architecture that minimizes a mathematical function on the degree of dependency. Nice.
Conclusion
To sum up, using a toy example (I admit it) we tried to sketch the informal process that should be used to defined types and classes. We started from the lacks we find in procedural programming paradigm, and we ended up trying to give a mathematical formulation of this process. All the ideas we used are tightly related to the basic concept of information hiding, that we confirmed to be one of the most essential concepts in object-oriented programming.
This post is just my opinion. It was not my intention to belittle procedural programming, not to celebrate object-oriented programming.
References
Posted on June 18, 2018
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
