[pt-BR] Modelagem de um domínio OO: um estudo de caso sobre a criação de um modelo para um gateway de autenticação e autorização

Renato Santos
Posted on February 11, 2022
Desenvolver é difícil, em especial, acredito que desenvolver orientado a objetos é difícil. Nas fases iniciais de um serviço, não é incomum que eu divida meu tempo em duas tarefas importantes: olhar para o teto e olhar para a tela do computador. A proporção? Não que seja relevante, mas… dez minutos olhando para o teto e dois para a tela; assim o ciclo se repete por um bom tempo, quase que ad infinitum. Já o desenvolvimento passa longe.
Também não é incomum que eu reescreva uma mesma parte do serviço quatro ou cinco vezes antes de sequer ter uma POC ou MVP. De fato, acredito que dificilmente um design OO passa pelo desenvolvimento sem mudanças; para mim, o esboço inicial é muito importante, mas dificilmente é uma representação suficientemente adequada a nível de código no momento de sua criação. E o que acontece entre uma reescrita e outra? Teto, tela…
Para os que consideram a criação de um serviço OO tarefa simples, eu os felicito e os invejo. Sinceramente, não acho que algum dia chegarei a pensar da mesma forma. Não quero convencê-los do contrário, mas acho que convém uma explicação sobre o meu ponto de vista.
Para entendermos porque uma modelagem OO é difícil, ou melhor, porque eu assim acredito, primeiro precisamos entender o que é orientação a objetos. O problema é que definir o que é orientação a objetos não é tarefa simples, mais fácil dizer o que não é; isso tudo sob o meu ponto de vista, claro. Orientação a objetos não é sobre a organização do código, pelo menos não em seu sentido fundamental, e, talvez esta te surpreenda, mas também não é sobre polimorfismo e herança. Orientação a objetos é sobre encapsulamento, o problema é que encapsulamento não é sobre criar classes com atributos privados repletas de getters e setters.
Abordaremos, primeiramente, polimorfismo e herança. São, estes, mecanismos essenciais para a orientação a objetos? Possivelmente, mas são apenas meios pelos quais se atinge a orientação a objetos, seu uso por si só não configura a orientação a objetos. De fato, é mais simples de se chegar a um código estruturado utilizando os mecanismos citados acima do que a um código OO; se classes não criam um programa OO, tampouco polimorfismo e herança.
Refletindo sobre o assunto, penso que encapsulamento é o que melhor define a OO. Encapsular é sobre dar uma responsabilidade para alguma unidade de código (seja uma classe ou qualquer outro construto) sem a necessidade de questioná-la sobre seus dados ou como seu comportamento é executado. Também é sobre construir camadas de comportamento e indireção, sobre compor funcionalidades com combinações de comportamentos e sobre esconder a complexidade; não gosto do termo diminuir porque, no final das contas, toda a complexidade necessária para alcançar um objeto deve, invariavelmente, estar presente. Para mim, o que melhor resume é: OO é sobre abstração. Abstração não existe sem encapsulamento e dificilmente é bem representada sem herança ou polimorfismo, a diferença é que herança e polimorfismo podem, em seu conceito mais fundamental, ser utilizados em um código não OO, mas não existe um meio termo para encapsulamento: aquilo que pode vir a ser chamado de um encapsulamento inadequado, na verdade, não está encapsulado.
É provável que eu ainda não tenha conseguido me expressar corretamente e que o dito acima tenha soado um tanto quanto abstrato, mesmo porque tão difícil quanto praticar um código OO é explicar o que é OO; talvez parte da dificuldade do desenvolvimento seja advinda da dificuldade de entendimento, é algo a se pensar. De qualquer forma, tenha calma: talvez eu consiga compartilhar de forma mais clara meu ponto de vista quando, de fato, chegarmos ao estudo de caso. Mas antes, acredito ser importante ressaltar algo que vejo costumeiramente e que acredito ser um anti-padrão OO: Domínio Implícito.
Ao analisarmos o código de diversos serviços OO, é comum verificarmos classes que representam conceitos concretos do mundo real: automóvel, carro, pessoa, estudante; exemplos não faltam. Mas o que acontece quando a aplicação não trata nada disso? E se a aplicação recebe um conjunto de dados, realiza transformações e passa os dados para frente? Talvez o ímpeto de alguns seja tentar materializar o que os dados representam no mundo real; outros simplesmente não criarão aquilo que é rotineiramente chamado de modelo. E qual o domínio da aplicação no final das contas? É aquilo que os dados representam ou a minha aplicação não tem um domínio específico?
Toda aplicação tem um domínio e, no exemplo citado acima, ele certamente não é aquilo que os dados representam. A representação do domínio de forma adequada é essencial, pelo menos para os programas OO. Porque é tão difícil representar um domínio no caso citado? No meu ponto de vista é porque quando pensamos em domínio, pensamos em algo concreto. Ou melhor, é porque quando pensamos em domínio pensamos em dados, não em comportamento. Mas qual seria um domínio adequado para o exemplo acima? Obviamente podemos chegar a diversas soluções distintas, mas alguns pontapés para iniciar a discussão podem ser: pipeline, fluxo, transformação, etc. Sim, estes são (leia-se, podem ser) objetos de domínio; mas é importante ressaltar que o domínio de uma aplicação depende dos seus objetivos.
O dito acima exemplifica aquilo que chamei de domínio implícito. Por falta de informações que categorizem um domínio do mundo real, uma aplicação fica sem seu domínio explicitamente mapeado em código. Este é o primeiro passo para um código estruturado, o segundo é a utilização inadequada de polimorfismo e herança e a falta de encapsulamento. No final das contas, ambos conceitos se confundem, já que o domínio implícito deriva do nosso costume de associar domínio a dados que, por sua vez, é um sintoma da falta de encapsulamento.
Mas agora, sem mais delongas, vamos ao nosso estudo de caso. Recentemente, fui inserido em um projeto onde nosso papel é ser uma espécie de integrador: vamos intermediar a comunicação entre provedores de conteúdo, como, por exemplo, plataformas de streaming, e provedores de serviço. O escopo é, de certa forma, extenso, mas gostaria de focar num aspecto menor: parte dos provedores de conteúdo se integra através de SSO (single sign on). Isto quer dizer que um usuário desta plataforma, ao entrar na mesma, seleciona o provedor de serviços pelo qual deseja se autenticar e é o provedor de serviços o responsável por dizer se o usuário em questão é elegível para consumir o conteúdo, isto é, se ele tem direito ou não.
É esperado que os provedores de serviços (ou, ao menos, a maior parte) já possuam um mecanismo de single sign on próprio; nesse sentido, seremos apenas um gateway de autenticação e autorização, onde vamos intermediar, repassar e traduzir requisições; lembrando que estamos falando apenas da parte do escopo citada acima. A ideia é que qualquer provedor de conteúdo possa se conectar ao SSO de qualquer provedor de serviço; do ponto de vista comercial, certamente não é tão simples assim, mas o objetivo é que, tecnicamente, isto seja possível. O mecanismo de autorização inicialmente suportado seria OAuth 2.0.
Acredito que, e eu posso estar errado nessa suposição, é um pensamento natural entre os desenvolvedores Java que utilizam frameworks web traçar uma estrutura padrão MVC. Algo como AuthController, AuthService, AuthRepository e afins. Faz sentido, mas até então não estamos falando de domínio em si. É provável que para suprir essa demanda classes como OAuth, OAuthData e/ou afins surjam como o chamado modelo e junto com elas, uma diversidade de getters e setters; ou não, viva ao Lombok! Seja como for, o esquema é parecido: service com a lógica em si e o model trafegando as informações.
Não me entenda errado, eu acho que essas estruturas são válidas, eu também as utilizo, mas prefiro tentar limitar seu alcance para pontos de entrada e não deixar que esse tipo de conceito penetre dentro do domínio. Na minha opinião, o mais questionável é o modelo anêmico, mas eu certamente não estou aqui para criticar abordagens de desenvolvimento. Por sorte, estou aqui para compartilhar um ponto de vista um pouco diferente e você pode concordar ou discordar, ou até ambos, quem sabe?!! Seja como for, o objetivo será atingido: difusão de conhecimento para estimular o pensamento crítico de forma que você tenha argumentos para sustentar seu ponto de vista, independente de qual seja ele.
Com os objetivos gerais traçados, o ciclo TT (apenas um nome bonito para teto, tela) para essa aplicação se iniciou. O meu instinto inicial foi mapear um domínio com conceitos como provedor de conteúdo e provedor de identidade (content provider e identity provider):
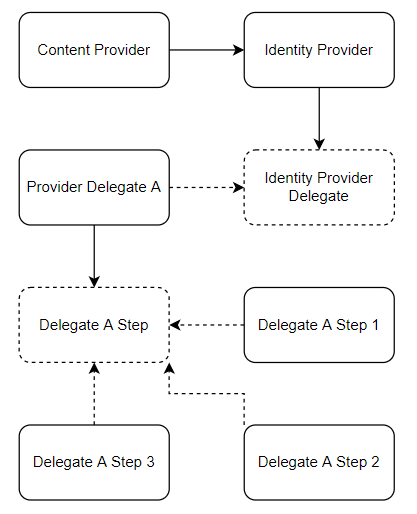
O provedor de conteúdo é uma classe simples, com dois métodos: um para autenticação e outro para autorização / elegibilidade. Em tese, seria o suficiente, já que são as duas ações necessárias para que os usuários desfrutem do conteúdo. O fato, porém, é que cada provedor de identidade pode ter sua lógica específica para realização dessas ações. Portanto, nada mais lógico que a implementação do provedor de conteúdo apenas chamar a implementação do provedor de identidade.
A questão é que autenticação e elegibilidade não podem ser encaradas como unidades do processo, isto é, podem ser compostos de diversos passos distintos; é este o caso do Authorization Code Flow, por exemplo. Sendo assim, no lugar de criar implementações específicas para os provedores de identidade, achei mais adequado criar um nível a mais de abstração, onde cada provedor de identidade delega, mais uma vez, a lógica para um outro componente.
A partir daí, cada delegate é livre para implementar seu funcionamento. A imagem demonstra a subdivisão das tarefas em passos nomeados, não de forma surpreendente, como steps. Mas essa é uma lógica específica de um delegate específico; cada delegate deve criar a estrutura que melhor se adequa ao seu algoritmo. A implementação base que faremos é feita de pequenos passos / estratégias.
Com o modelo inicial em mente, parti para o início do desenvolvimento; o problema é que o desenvolvimento não partiu junto comigo! Logo de início, o desenvolvimento não fluiu bem; avanços lentos com pausas para oxigenar a mente. Como dito, isto não é incomum quando eu inicio um novo serviço, o problema é que, desta vez, sequer consegui escrever uma regra de negócio na estrutura inicialmente proposta. Isso geralmente é um bom indicativo de problemas de domínio, mas, por vezes, é apenas falta de inspiração. Para a minha sorte, neste caso, o problema se enquadrou na primeira categoria. Questões começaram a surgir: o que acontece se o mecanismo não for OAuth x OAuth? E se o SSO do provedor de serviços for através da leitura de um QR code pela aplicação, proprietária, em um dispositivo móvel já autenticado? E se for necessário que os tokens não sejam repassados diretamente, sendo criados tokens correlatos para repasse aos provedores de conteúdo? E se os tokens correlatos tiverem um mecanismo de atualização distinto dos tokens gerados diretamente para o integrador e a validade do token correlato seja válida enquanto o token original tenha expirado? Todos esses questionamentos podem levar a uma série de condicionais problemáticas que tornariam o código complexo.
Neste ponto, um bom tempo já havia se passado e eu estava decidido que meu domínio não era semanticamente adequado para representar o meu problema. A representação de um domínio precisa ser capaz de resolver um problema, mas não pode ser amarrado em uma funcionalidade extremamente específica; a orientação a objetos é justamente entender o problema e criar um domínio suficientemente abstrato para compor a funcionalidade que resolverá a questão suportando a mudança gradual. Obviamente isto não quer dizer que o serviço não sofrerá alterações, inclusive, eu construo meus serviços de modo que eles geralmente sofrem pequenas adequações à medida que os requisitos ficam mais claros. A questão é que procuro fornecer ao serviço uma estrutura que permita seu fácil incremento e adaptação. Este é o ponto chave e parecia ser justamente aquilo que meu modelo não tinha; de volta ao desenho, saí com uma estrutura parecida com a seguinte (representação simplificada por mérito de brevidade):
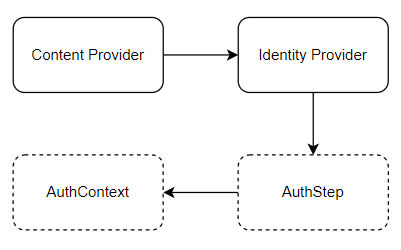
Neste momento, estava decidido que o delegate era um passo desnecessário, pois, na minha visão qualquer processo de autenticação vai, necessariamente, precisar passar por uma composição de comportamento, mesmo porque o que exatamente acontecerá depende de dois mecanismo de autenticação que podem ser completamente distintos: como é feita a autenticação do provedor de conteúdo com o integrador e como é feita a autenticação do integrador com o provedor de identidade.
E como o comportamento adequado é composto? A composição é feita através de uma análise do contexto de autenticação; esse contexto é rico o suficiente para fornecer informações sobre qual o mecanismo utilizado entre provedor de conteúdo e o integrador e qual o utilizado entre integrador e provedor de identidade. Além disso, também registra informações sobre o estado atual do processo, configurações de trocas de mensagens, tokens gerados e afins. Mediante estas informações, existe um componente responsável por criar a sequência de passos necessária para sua execução, num estilo chain of responsability.
Agora, de volta ao desenvolvimento, certo? Errado! Uma coisa me incomodava: o contexto necessário para cada passo pode variar de forma extrema, como representar a chamada? Um problema de padrões como o strategy, por exemplo, é que, necessariamente, o input de dados precisa ser o mesmo e, neste caso, cada passo teria um input bem diverso. Isso pode ser mitigado simplesmente não passando quaisquer valores como parâmetros para a chamada da estratégia em si, mas sim injetando a dependência na criação do passo. Isso nem sempre é possível e ainda que fosse, neste caso, o problema permanecia: o que seria injetado? Eu deveria utilizar um simples mapa como input das chamadas e cada passo recuperaria as informações necessárias? A ideia não me agradava muito e, pela terceira e última vez no quadro de desenhos, pensei na seguinte estrutura:
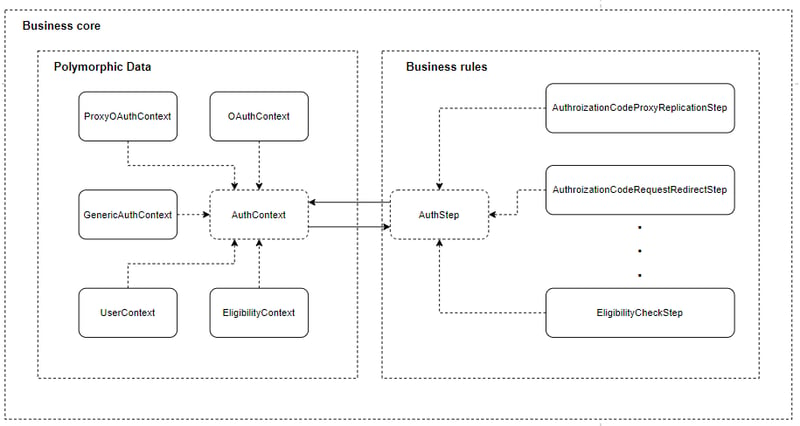
Em primeiro lugar, é necessário dizer que esta é a última versão até o momento. Como ponto positivo, porém, ressalto que o MVP está basicamente concluído e isto quer dizer que, a menos que o objetivo geral da aplicação mude, dificilmente o domínio passará por mudanças gigantes; incremento e adaptação, sempre existirão. Outra hipótese para mudanças significativas seria um terceiro design inadequado, claro; no momento, prefiro me confortar no pensamento de que este não é o caso.
O primeiro ponto é o sumiço do provedor de conteúdo e do provedor de identidade. Essa remoção foi fruto da percepção de que estes conceitos pouco importam sobre como a autenticação acontecerá; por mais que, logicamente faz toda diferença, no final das contas se resume a quais protocolos serão utilizados com quais configurações. A representação dos provedores é desnecessária porque são apenas armazéns de dados. Sendo assim, meu domínio se resume a dois conceitos básicos: AuthStep e AuthContext.
Tenho uma aplicação que precisa se preocupar apenas com o seu contexto de autenticação e quais os passos serão necessários para atingir o objetivo. E quais objetivos são esses? Com o sumiço do provedor de conteúdo e de identidade, os métodos de autenticação e elegibilidade não faziam mais sentido; cabe ressaltar, também, que eles nunca foram ações satisfatórias para este contexto. Achei mais adequado tornar as ações mais granulares, agora existem ações específicas para o fluxo de autenticação iniciado pelo provedor de conteúdo (que não faz mais parte do domínio): geração do authorization code, geração do access token, refresh dos tokens, revoke e por aí vai. O meu contexto tem o registro de qual ação foi requisitada e é capaz de validar se a mesma pode ser realizada.
Mas e o contexto? Ele é variável e cada passo ainda vai precisar de seus dados específicos, certo? Certo, um contexto OAuth entre o provedor de conteúdo e o integrador pode ser transformar num contexto SAML, ou algum procotolo custom, entre o integrador e o provedor de identidade. A forma continua a mesma, cada passo trabalha em cima de um AuthContext e passa este mesmo AuthContext para frente para ser trabalhado pelo próximo passo. Então, é razoável que, a este momento, você se questione sobre como essa situação teve seu aspecto geral melhorado.
Para a situação descrita acima, eu criei uma estrutura que chamei de Polymorphic Data (ou dados polimórficos, só que bonitinho); talvez eu tente a vender como um possível padrão de projeto em um novo artigo, afinal, vai que cola. A passagem de um mapa é uma questão delicada, é uma estrutura de dados base que pode ser modificada como bem entender, seriam necessários representar os campos com constantes e os problemas não param por aí. Ao mesmo tempo, o contexto que está sendo executado na cadeia não pode mudar; quer dizer, ele pode e deve mudar, mas o contexto antigo não pode ser invalidado e assim que ele assumir novamente o formato antigo, os dados que já foram trabalhados anteriormente devem estar preservados.
No final das contas, o AuthContext utiliza sim um mapa como estrutura de dados, mas isso é uma estrutura encapsulada, sem visibilidade externa, assim como o seu acesso aos dados é encapsulado, sem precisar dizer ao cliente que o acesso é feito através de uma SQL ou chamada Rest. O ponto chave é que todas as informações se encontram numa mesma estrutura, sem visibilidade externa. O segredo da estrutura está em um um método chave do AuthContext, chamado as. Este método recebe, como parâmetro, uma classe que herda de AuthContext, ? extends AuthContext, e retorna uma implementação concreta do contexto desejado. Esta implementação concreta trabalha sobre o mesmo mapa utilizado na anterior, mas possui o conjunto de comportamentos necessários para atuar e expor somente os dados pertinentes para aquele contexto:
OAuthContext oauthContext = authContext.as(OAuthContext.class);
if (!oauthContext.isGrantValid()) { throw new InvalidAuthRequestException(“invalid_grant”); }
return oauthContext; //ou authContext, é irrelevante
Dessa forma, cada passo realiza a transformação para trabalhar com o contexto que precisa e a transformação em si não altera os dados de outro contexto, que pode ser novamente obtido em passo posterior.
Pensei nos dados polimórficos para situações quando precisamos integrar diversos domínios e contextos diferentes e quando as ações executadas neste domínio são muito granulares, de forma que a maioria não se enquadre na declaração do contexto pela alta versatilidade e variabilidade.
Uma questão que talvez você esteja pensado é: cada passo deve precisar extrair informações do contexto para realizar sua lógica e, portanto, isto não seria separar dados de comportamento? Sim e sim, mas neste caso, eu não considero uma quebra de encapsulamento. Cada contexto tem o comportamento mais pertinente embutido em si: verificação da validade do access token, validação da utilização do authorization code e por aí vai. Porém, a obtenção de um access token não está intimamente ligada ao access token em si, bem como o consumo de APIs protegidas. Nesse sentido, é necessário que o contexto exponha informações pois existe um conjunto de dados onde as operações realizadas por eles são tão granulares que não me parece adequado juntar as coisas, bem como a sequência de operações pode necessitar de uma parte da informação completamente diversa para cada passo.
O resultado final é que a lógica da domínio está, praticamente em sua totalidade, concentrada no AuthStep e AuthContext e não em services e afins. A estes, prefiro deixar a lógica estrutural da aplicação. Se eu troco meu framework, minha lógica de negócio está intacta, apesar de, logicamente, eu precisar reestruturar as necessidades da aplicação em si.
Na minha opinião, é tão difícil criar um modelo semanticamente rico porque não é sobre saber desenvolver, ou pelo menos não apenas sobre isso; é sobre conhecer o negócio. Além disso, a dificuldade de OO está em favorecer soluções que buscam estruturar comportamentos que acomodam o requisito e, ao mesmo tempo, atingem determinados objetivos (técnicos e não técnicos), em detrimento de soluções que se preocupam, fundamentalmente, com a necessidade mais clara representada pelo aspecto direto do requisito.
Conseguir imaginar e traçar os objetivos por trás de um domínio é essencial. Para mim, neste caso, desde o início estava claro que seríamos uma ponte e que possivelmente precisaríamos executar diferentes processamentos sobre diferentes conjuntos de dados. Existem outros modelos possíveis para representar esta aplicação e para disponibilizar a funcionalidade no pé da letra? Sim, existem, mas acredito que o modelo cumpre com os objetivos mais gerais. É claro que nada disso descarta a possibilidade de problemas posteriores, tanto o domínio quanto os objetivos podem ter sido mapeados de forma inadequada; ainda assim este tipo de composição tem, historicamente, facilitado minhas refatorações.
E, pra mim, é interessante que algo tão essencial seja tão difícil. No final das contas, é difícil porque não existe um conjunto de passos que te ajudarão a criar um domínio adequado, é necessário entender o problema, avaliar toda a questão num grau de profundidade maior do aparente e… imaginação? Em um projeto anterior, fiquei diversos meses para criar um modelo de domínio adequado aos serviços já existentes. Mas isso é história para outro momento.
Posted on February 11, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.