[en-US] Modeling an OO domain: a case study about the creation of a model for an authentication and authorization gateway.

Renato Santos
Posted on February 11, 2022
Developing is hard, in particular, I believe developing object-oriented code is hard. In the initial stages of developing a new service, it's not uncommon for me to divide my time into two important tasks: to look at my office's ceiling and my computer's screen. Chances are you've heard of the PDCA cycle or OODA loop. Well, OCCS (office's ceiling - computer's screen) is kinda my tool for continuous improvement as well. The proportion of each task, you ask me? I don't think that's relevant, but… ten minutes looking to the ceiling for every 2 minutes looking at the computer's screen. This way the cycle goes on, almost ad infinitum, while the actual development is nowhere to be seen.
It's also not uncommon for me to rewrite and redesign the same part of a service four or five times before I even have a proof of concept or minimum viable product and I believe it's almost impossible for an OO design to go under development without changes. For me, the initial draft is really important but it's hardly an adequate representation of the actual code when it's first created. And what happens between one rewrite and another? Ceiling, screen…
For those of you who consider creating object-oriented code a simple task, I both congratulate and envy you. To be honest, I don't think I'll ever come to a point where I'll think alike. I don't wish to convince you otherwise but a better explanation than "it's hard" is needed.
To understand why I believe OO modeling is hard, we must first understand what object orientation is and what it is not about. Object orientation is not about code organization, at least not in its fundamental sense and, maybe this surprises you, but it's not about polymorphism and inheritance either. Object orientation is about encapsulation, the thing is that encapsulation is not about creating classes full of private attributes with getters and setters.
First, let's approach the polymorphism and inheritance issue. Are those essential mechanisms for object orientation? Possibly, but they also are nothing more than means by which object orientation is achieved, and solely its use does not configure OO. It’s easier to develop structural code using the mechanisms above than a true OO code. If classes do not create an OO program, neither do polymorphism and inheritance.
I believe encapsulation is what best defines OO. To encapsulate is to give responsibility to some unity of code (be it a class or any other type of construct) without questioning it about its data or how its behavior is executed. It's about creating layers of behavior and indirection, composing features with a combination of behaviors, and hiding the complexity. In short: OO is about abstraction. There can not be abstraction without encapsulation and abstraction is hardly well represented without inheritance or polymorphism. The difference is that inheritance and polymorphism can produce structural code while there is no middle ground for encapsulation: that which may be called inadequate encapsulation is, in fact, not encapsulated.
It's likely that I still haven't been able to express myself correctly and that all that was said above may have sounded abstract - no pun intended - after all, explaining what is OO might just be as hard as creating OO code - those might be connected and part of the difficulty in developing is the result of the lacking of understanding. Bear with me and keep calm: maybe I can share my point of view in a clearer way when we get to the case study. But before, I believe it's important to highlight an issue I often see and believe it's an OO anti-pattern: Implicit Domain.
Analyzing OO code, it's common to see classes that represent concrete concepts of the real world: person, student, order, etc. But what if our application has nothing to do with those things? What if our application receives some data, transforms it, and produces modified data? Some will try to materialize what the data represents in the real world while others will simply not create what is routinely called a model. And what is the application domain after all? Is it what the data represents or doesn't my application have a specific domain?
Every application or service has a domain and in the above example, it's certainly not what the data represents. A correct design of the domain is crucial, at least for OO code. Why is it so hard to create a domain model for the given example? I believe it's because when we think about the domain we think about data, not about behavior. An adequate design does not mean a single solution, but for starters, we could use a few concepts to create our domain: pipeline, flow, transformation, etc. Yes, those are - or rather, can be - domain objects, but it's important to notice that the domain of an application depends on its goals.
The above is an example of what I called implicit domain. For lack of data that configures a real-world domain, an application is left without its domain explicitly mapped in code. This is the first step to creating procedural code - the second is the inadequate use of polymorphism and inheritance and the lack of encapsulation. At the end of the day, both concepts are intertwined since the implicit domain comes from our habit of associating domain to data which, in turn, is a symptom of the lack of encapsulation.
But now, with no further ado, let's explore our case study. Recently I was introduced to a project in which our role was to be a kind of integrator: we should intermediate the communication between content providers, e.g. streaming platforms, and service providers. The scope is extensive but I'd like to focus on a particular feature: part of the content providers integrate themselves through SSO - the user has access to the content signing into the service provider which is responsible for determining the user's eligibility to the content. Each service provider had a proprietary SSO solution and we were to act only as an authentication and authorization gateway where we should intercept and translate requests.
The idea behind the feature was that any content provider may be integrated into the SSO mechanism of any service provider. Although it's not so simple commercially speaking, technically it should be possible. The initially supported standard would be Oauth 2.0.
I believe that - and I may be wrong supposing this - it's natural thinking between Web Java developers to create a default MVC structure - something like AuthController, AuthService, AuthRepository, and the likes of it. While it makes sense, we are not talking about the application domain - for that, it's likely that classes such as OAuth and OAuthData be created as the application domain and, with them, a diversity of getters and setters - or not, praised be Lombok! Either way, the picture is the same: a service class with business rules and the model storing information.
Don't get me wrong, those are valid structures and I use them as well, but I'd rather limit its reach to entry points and not let this type of concept penetrate the domain. I believe an anemic domain is rather questionable, but I'm certainly not here to criticize development approaches. With a little bit of luck, I might be able to share a different point of view and you may agree or not - or even both, who knows?!! In any case, I'll achieve my goal: knowledge sharing to stimulate critical thinking so that you have arguments to support your point of view, whatever it may be.
With the main goals outlined, the OCCS cycle (ha!) for the application began. My initial instinct was to map concepts like identity and content provider:
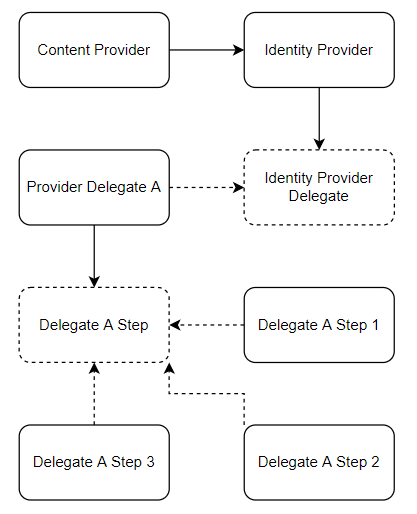
The content provider is a simple class with two methods: one for authentication and another for authorization. It should be enough since those are the two actions needed for the user to enjoy the content. Each identity/service provider can have its logic/standard to authenticate/authorize a user and, as such, It seems logical that the content provider implementation should merely call the identity provider implementation.
The issue is that authentication and eligibility should not be seen as whole units of the process, that is, they can be composed of several different steps - that is the case with OAuth's Authorization Code Flow. So, instead of creating specific implementations for the identity providers, it seemed better to create one more level of abstraction in which each identity provider delegates, once more, the processing to another component.
From there, each delegate is free to implement their inner workings. The initial design represents a subdivision of the tasks in steps but that's the implementation of the base delegate and each delegate should create the structure that is better for their algorithm.
With the initial concept on my mind, I decided to start coding - sadly, no code was written that day! From the very beginning, the development was not flowing very well - slow advances with pauses to take a breath. As I said, that's not uncommon when I first start a new service, the thing is that this time I still hadn't written a single business rule with the proposed design. This is usually a sign of domain problems but, sometimes, it's just a lack of inspiration. Well, just my luck - this time, it was the former!
Some doubts started appearing: What happens when the standards used are not OAuth x OAuth? What if the service provider's SSO is a proprietary solution with the usage of QR Codes in a mobile device previously authenticated? What if the service provider tokens should not be shared directly and instead correlation tokens should be used? What if the correlation tokens had different refresh policies than their original counterparts? All these possibilities led to several conditionals that would make the code overly complex.
By this time, a good amount of time had passed and I was certain my domain design was not semantically adequate to represent my problem. The design of a domain must be able to solve a problem but can't be based on a very specific feature - object orientation is to understand a problem and create a domain abstract enough to compose functionality that will solve the issue while supporting gradual change. This does not mean that the service won't change, I build services in a way that they often undergo minor adjustments as the requirements become more clear - what is important is to create a structure that enables the service increment and easy adaptation. This is key and was precisely what my domain was lacking. Back to the drawing board and I got a design that looked like the following (simplified for brevity):
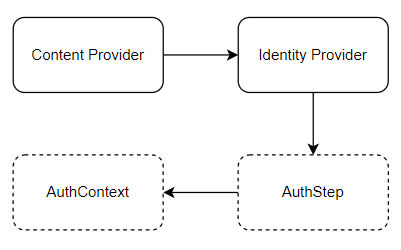
At this moment, I was sure the delegate was unnecessary for any authentication process will need a composition of behaviors, even more so because the exact needed steps on two authentication mechanisms may be completely distinct - the way the content provider authenticates to us and the way we authenticate to the identity provider. In other words, there would be no single step to achieve authentication/authorization from a content provider to an identity provider.
And how is adequate behavior achieved? The composition of steps is done through an analysis of the authentication context - this context has enough data to provide information on which mechanism is used between the content provider and us and which is used between us and the identity provider. Besides, it also records information about the process state, message exchange configurations, generated tokens, and related data. Through this information, there is a component responsible for creating the sequence of steps necessary for behavior execution, in a chain of responsibility style.
Back to development, right? Well, not really. One thing still bothered me: the context needed for each step may vary greatly, how to create a common interface? An issue with patterns such as strategy is that the input needs to be the same and in this case, each step would probably need a different set of data. This could be mitigated by not passing parameters to the strategy call and using dependency injection, instead. This isn't always possible and even if it was in this specific case, the core issue still existed: what would be injected? Should I use a simple hashtable as input for method calls and each step read the needed data? The idea didn't sound correct and, for the third and last time, I went back to the drawing board arriving at the following structure:
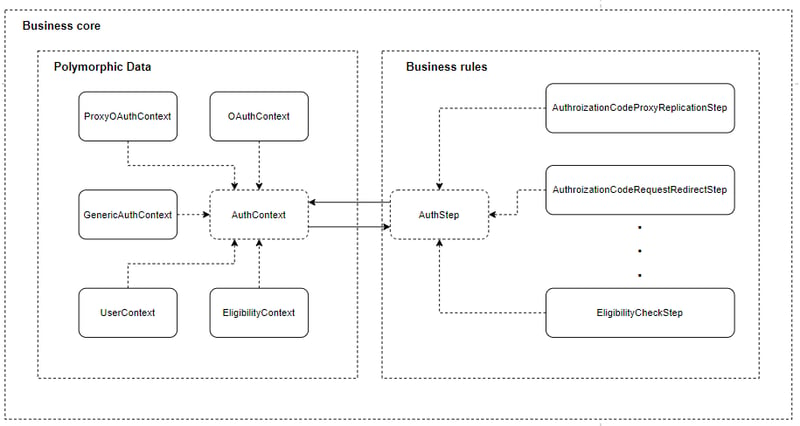
For starters, I should say this is the last version up to now. Change is an undeniable reality in software development and the only way to cope with this reality is to design an abstract enough domain focused on goals and functionality by composition.
The first thing to notice is that the content provider and identity provider were scraped out. Their removal is the result of the perception that these concepts do not matter to how the authentication will take place - while the actual authentication process depends on these real-world entities, their domain model counterparts would be nothing more than data storage classes. And so, my domain comes down to two basic concepts: AuthStep and AuthContext.
My domain model now only needs to worry about its authentication context and what steps will be needed to reach the goal. There were no more fixed set of actions that should be taken to achieve a goal - I found it more appropriate to make the actions more granular, now there are specific actions for the authentication flow initiated by the content provider: authorization code generation, access token generation, token refresh, token revocation, etc. The authentication context holds information on what action was requested and can verify if the action can and should be performed.
You might be wondering about the context - it still needs to be variable and each step still needs a specific set of data, right? Right, an OAuth context between the content provider and us might turn into a SAML - or any other protocol, for that matter - between us and the identity provider. So, as of now, it doesn't look like the input issue has been solved.
For this issue, I created a structure that I've called Polymorphic Data - maybe I'll try to sell it as a design pattern in a new article; you can never be too sure on what sticks these days. Using a map as a parameter is a delicate issue as it can be handled in ways not intended and it imposes knowledge of data structure to calling code - besides, it is a data storage without any domain behavior. At the same time, the context is being incremented and used on a chain of actions so its internal state can and should change, but the old context can't be invalidated as the data might be needed again for a different step.
In the end, AuthContext does use a map/hashtable as its internal data structure, only it is encapsulated, without external visibility, just like the data access is - the calling code does not know from where the data is fetched. The key point is that all information is stored in the same structure but hidden from external code - the secret to making this work is in AuthContext's key method AuthContext::as. This method receives as a parameter a class that inherits from AuthContext and returns the desired context implementation. Each implementation works on the hashtable but exposes behavior to work only on the pertinent data for the current context:
OAuthContext oauthContext = authContext.as(OAuthContext.class);
if (!oauthContext.isGrantValid()) { throw new InvalidAuthRequestException(“invalid_grant”); }
return oauthContext; //or authContext, it does not matter
This way, each step executes the context transformation it needs and the transformation does not change the pertinent data to a different context, which can be obtained on a later step. I came up with polymorphic data for situations when we need to integrate several different domains and contexts and when the behavior is too granular given the versatility of the scenario.
You might be wondering - each step must extract information from the context to execute its behavior and, if this is the case, isn't the data segregated from the behavior. Indeed it is, but I reckon this is not a break of encapsulation. Each context has the most pertinent behavior inside itself - validate the access token, verify the authorization code, etc. So it happens that behavior like obtaining an access token and consuming protected APIs isn't the responsibility of the context.
The resulting structure is that domain behavior is almost entirely concentrated on AuthStep and AuthContext - not inside service classes. To these, I'd rather leave code controlling application logic. If I change my framework, my business rules are intact, although the application code will need to be restructured.
I believe it's so hard to create a semantically rich model because it's not about knowing how to code - or at least not only about it - it's about knowing the business. In addition, object orientation difficulty is in favoring solutions that structure the behavior in a way that the requirement is satisfied and, yet, reaches a set of goals - both technical and otherwise - instead of solutions that, fundamentally, seek only to achieve the most superficial need of the requirement. After all, it's much easier to develop a service that takes care of OAuth processing than to create an internal structure that enables seamless authentication context migration - both would comply with the initial business rules, but it's clear which would accommodate better gradual change.
Being able to imagine and trace goals behind a domain is essential. From the start, it was clear to me that we would act as a gateway and that we possibly would need to execute different behaviors on different sets of data. Are there other adequate domain models to build this application and provide the current behavior? Sure, but I'd like to think that our goals have been achieved. Future problems can occur, even if care on the design was taken - the domain or the goals could turn out to be incorrect or inadequate. Still, historically, this way of thinking has facilitated my refactorings and application growth.
For me, it's interesting that something so essential is so hard. In the end, it's hard because there is no set of steps that will guide you to create an adequate domain - you need to understand the problem, deeply analyze it and its context, and… imagination? In a previous project, I needed several months to create an adequate domain for a set of existing services. While this is subject for another time, know this: abstract thinking is hard - most probably because we are not used to it. Abstract thinking has been part of our lives for a rather short time. We tend to think that computers are somewhat intelligent because they excel in areas that seem hard to us - this is due to the exposure time. After all, walking and dancing is a pretty basic task for most people - ok, dancing not so much - but it's rather hard to build a robot with fluid motion. Again, exposure time.
Posted on February 11, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.