13 AWS Lambda design considerations you need to know about – Part 1

Rehan van der Merwe
Posted on October 14, 2019

When you hear the word ‘serverless’, AWS Lambda is most likely the first thing you think about. That’s no surprise; the tech hit our industry by storm and brings with it a whole new paradigm of solutions. AWS Lambda was the first Function as a Service (FaaS) technology I was exposed to, and like others, I was highly critical at first. There are no servers to manage, it auto-scales, has fault tolerance built-in, and is pay per usage —all of which sounds like a dream.
With great power comes great responsibility. Serverless design requires knowledge of different services and how they interact with each other. Just like any other technology, there are some tricky waters to navigate, but they are far outweighed by the power of what serverless has to offer. To stop this dream from turning into a nightmare, here are a few things to keep in mind when designing with AWS Lambda.
In this two-part series, we’ll be diving into the technical details, like configuration options and any limitations you need to know about. The second part will focus on how to use the technical considerations we cover in part one to effectively design serverless and Lambda systems. At the end of it all, you should have a clearer understanding of the key considerations you need to bear in mind when designing around AWS Lambda.
This is an article written for Jefferson Frank, it can be found here or on my blog.
Technical considerations
1) Function Memory
The memory setting of your Lambda determines both the amount of power and unit of billing. There are 44 options to choose from between the slowest or lowest 128 MB, and the largest, 3,008 MB. This gives you quite a variety to choose from! If you allocate too little memory, your program might take longer to execute and might even exceed the time limit, which stands at 15 minutes. On the other hand, if you assign too much memory, your function might not even use a quarter of all that power and end up costing you a fortune.
It’s crucial to find your function’s sweet spot. AWS states that if you assign 1,792 MB, you get the equivalent of 1 vCPU, which is a thread of either an Intel Xeon core or an AMD EPYC core. That’s about as much as they say about the relationship between the memory setting and CPU power. There are a few people who’ve experimented and come to the conclusion that after 1,792 MB of memory, you do indeed get a second CPU core and so on, however the utilization of these cores can’t be determined.
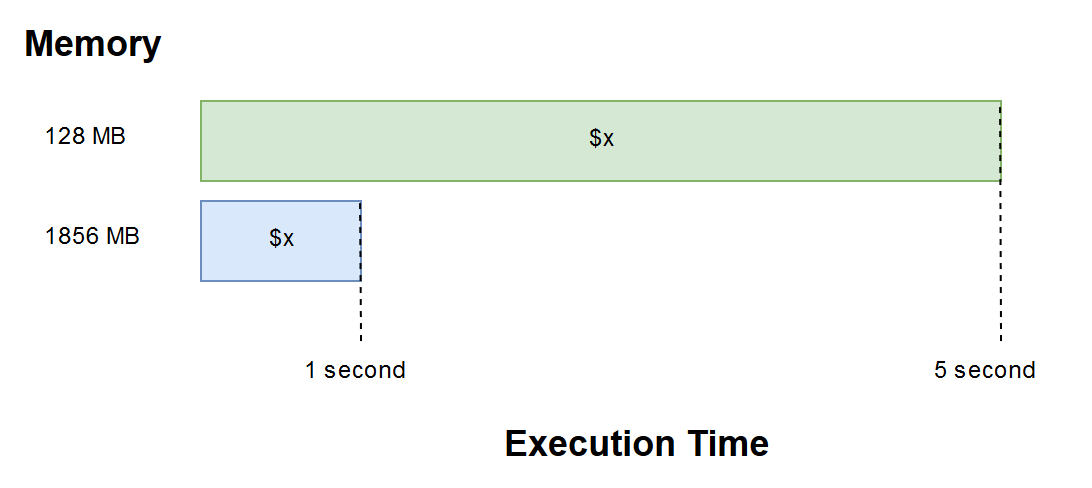
Cheaper isn’t always better —sometimes choosing a higher memory option that is more expensive upfront can reduce the overall execution time. This means that the same amount of work can be done within a smaller time period, so by fine-tuning the memory settings and finding the optimal point, you can make your functions execute faster as opposed to the same low memory setting. You may end up paying the same—or even less—for your function than with the lower alternative.
The bottom line is that CPU and memory should not be high on your design consideration list. AWS Lambda, just like other serverless technologies, is meant to scale horizontally. Breaking the problem into smaller, more manageable pieces and processing them in parallel is faster than many vertically scaled applications. Design the function and then fine-tune the memory setting later as needed.
Breaking the problem into smaller manageable piecesand processing them in parallel is faster than many vertically scaled applications.
2) Invocation
AWS Lambda has two invocation models and three invocation types. What this means is that there are two methods of acquiring the data and three methods through which the data is sent to the Lambda function. The invocation model and type determine the characteristics behind how the function responds to things like failures, retries and scaling that we’ll use later on.
Invocation models:
- Push: when another service sends information to Lambda.
- Pull: an AWS managed Lambda polls data from another service and sends the information to Lambda.
The sending part can then be done in one of three ways, and is known as the invocation type :
- Request Response: this is a synchronous action; meaning that the request will be sent and the response will be waited on. This way, the caller can receive the status for the processing of the data.
- Event: this an asynchronous action; the request data will be sent and the Lambda only acknowledges that it received the event. In this case, the caller doesn’t care about the success of processing that particular event. Its only job was to deliver the data.
- Dry Run: this is just a testing function to check that the caller is permitted to invoke the function.
Below are a few examples that showcase the different models and invocation types available:
- API Gateway Request is a Push model and by default has a Request Response invocation The HTTP request is sent through to the Lambda function, the API gateway then waits for the Lambda function to return the response.
- S3 Events notifications, SNS Message, Cloudwatch Events is a Push model and Event invocation
- SQS Message is a Pull model and a Request Response invocation AWS has a Lambda function that pulls data from the Queue and then send it to your Lambda function. If it returns successfully, the AWS-managed polling Lambda will remove it from the queue.
- DynamoDB Streams and Kinesis Streams are Pull models and have a Request Response invocation. This one is particularly interesting as it pulls data from the stream and then invokes our Lambda synchronously. Later, you’ll be see that if the Lambda fails it will try and process that message indefinitely (or until it expires), keeping other messages from being processed as a result.
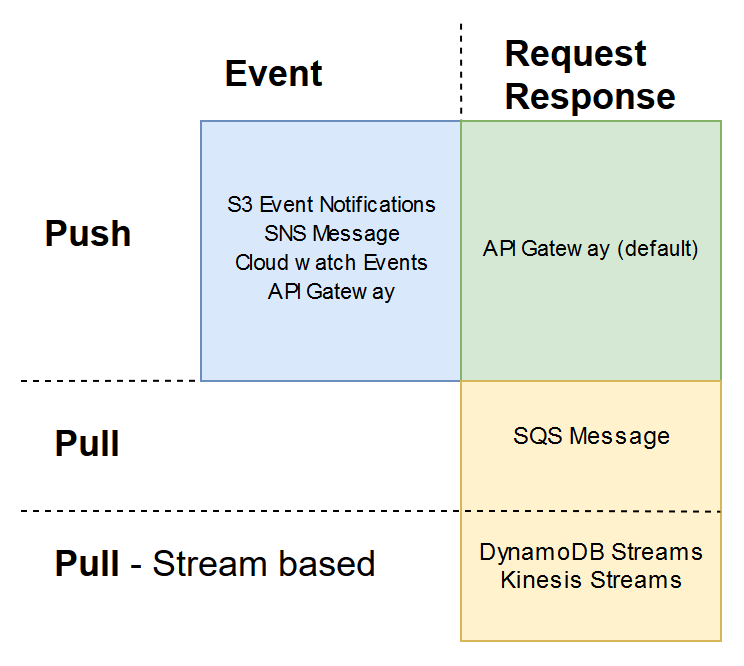
To my knowledge, there are no Pull models that do Event type invocations. Pull models are further divided into two sections, stream-based and non-stream based. Also, note that the API Gateway invocation type can be changed to Event (async) by adding a header before sending the data to the Lambda.
3) Failure and retry behavior
This is most probably one of the most important considerations: how a Lambda fails and retries is based on the invocation type. For all Event -based invocations, if Lambda throws an error it will be invoked two more times—so three times in total, separated by a delay. If a Dead Letter Queue (DLQ) is configured, the message will be sent to the configured SQS or SNS topic, or the error will just be sent to CloudWatch.
With the RequestResponse invocation type, the caller needs to act on the error returned. For API Gateway (Push + Request Response) the caller can maybe log the failure, then retry again. When it comes to Kinesis Streams (Pull stream-based + Request Response) it acts as a FIFO queue/stream. Which means if the first message is processed in error by the Lambda, it will block the whole stream from being processed until that message either expires or is processed successfully.
Idempotent system: A system will always output the same result given the same input.
It’s important to understand the failure and retry behavior of each invocation type , as a general rule of thumb, design all your functions to be idempotent. This basically just means that if the function is invoked multiple times with the same input data then the output will/must always be the same. When you design like this, the retry behavior will not be a problem in your system.
4) Versions and Aliases
AWS provides Versions and Aliases out of the box for your Lambda code. This might not be as straightforward and useful as you would think. A few things to keep in mind:
- Versioning only applies to the Lambda code, not to the Infrastructure that it uses and depends on.
- Once a version is published, it basically becomes read-only.
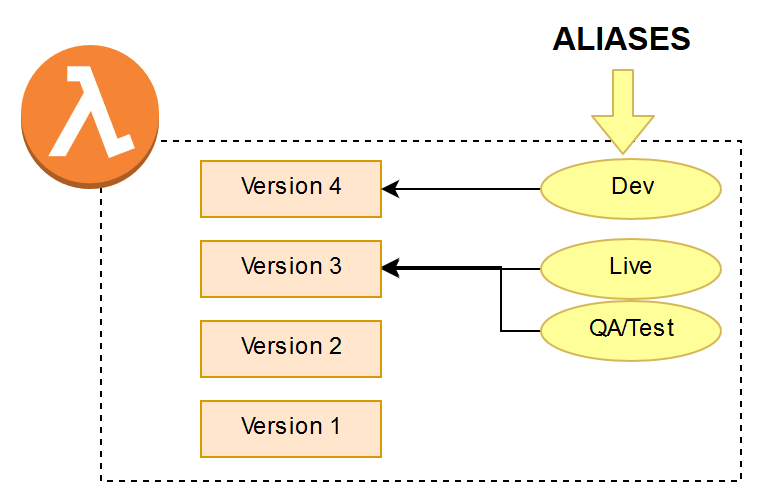
There are three ways in which you can use versioning and aliases. A single Lambda function that gets a new version number whenever there is a change to code or configuration. The alias will be used as the stage and pointed to the correct version of the Lambda function.
Again, it’s imperative to note that if something for the older versions, for example, version 3 (now the Live alias/stage) needs to change it cannot, so you can’t even quickly increase the timeout setting. In order to change it, you would need to redeploy version 3 as version 5 with the new setting and then point the Live alias to version 5. Then keeping in mind that Version 5 is actually older than version 4, this gets unnecessarily complex very quickly.
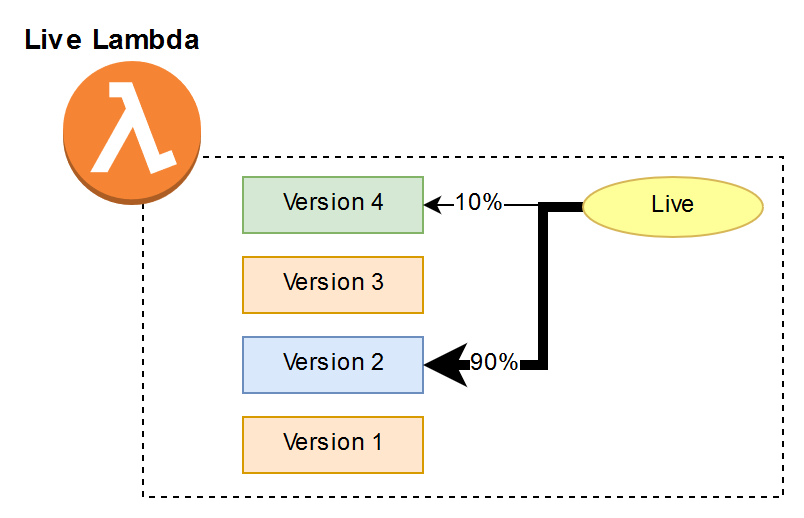
The second method that comes to mind is a blue green deployment. Which is a little less complex where you would have three different Lambdas, one for each stage—blue being the old version and green being the new version. Just like before each new deployment of a Lambda is versioned. Then when you are ready to make the new code changes live, you create an alias that specifies, for example, 90% of traffic uses the old version and then 10% of the requests go to the new version. This is called Canary Deployments, although AWS doesn’t label it as such, it allows you to gradually shift traffic to the new version.
The third method is the simplest and plays nicely with IaC (Infrastructure as Code) tools like CloudFormation, SAM and CICD (Continuous Integration Continuous Deployment) pipelines. It’s based on the principle that each Lambda is “tightly” coupled with its environment/infrastructure. The whole environment and Lambda are deployed together, any rollback will mean that a previous version of the infrastructure and Lambda needs to be deployed again. This offloads the responsibility of versioning to the IaC tool being used. Each Lambda function name includes the stage and is deployed as a whole, with the infrastructure.
5) VPC
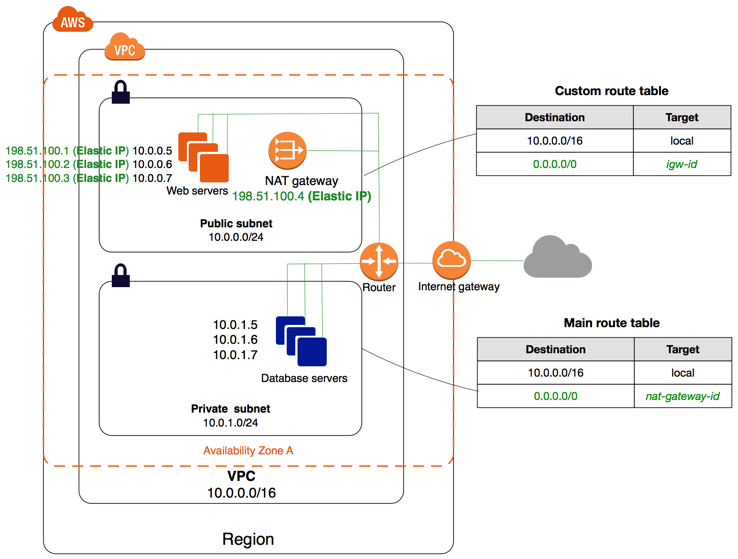
The main reason to place a Lambda inside a VPC is so that it can access other AWS resources inside the VPC on their internal IP addresses/endpoints. If the function does not need to access any resources inside the VPC, it is strongly advised to leave it outside the VPC. The reason being that inside the VPC each Lambda container will create a new Elastic Network Interface (ENI) and IP address. Your Lambda will be constrained by how fast this can scale and the amount of IP addresses and ENIs you have. [UPDATE: See end for: Improved VPC networking]
As soon as you place the Lambda inside the VPC, it loses all connectivity to the public internet. This is because the ENIs attached to the Lambdas only have private IP addresses. So it is best practice to assign the Lambda to three private subnets inside the VPC, then connect the private subnets to go through a NAT in one of the public subnets. The NAT will then have a public IP and send all traffic to the Internet Gateway. This also has a benefit that the egress traffic from all Lambdas will come from a single IP address, but it introduces a single point of failure, this is of course mitigated by using the NAT Gateway over the NAT instance.
6) Security
As with all AWS services, the principle of least privilege should be applied to the IAM Roles of Lambda functions. When creating IAM Roles, don’t set the Resource to all (*), set the specific resource. Setting and assigning IAM roles this way can be annoying, but is worth the effort in the end. By glancing at the IAM Role you will then be able to know what resources are being accessed by the Lambda and then also how they are being used (from the Action attribute). It can also be used for discovering service dependencies at a glance.
7) Concurrency and scaling
If your function is inside a VPC, there must be enough IP addresses and ENIs for scaling. A Lambda can potentially scale to such an extent that it depletes all the IPs and/or ENIs for the subnets/VPC it is placed in. [UPDATE: See end for: Improved VPC networking]
To prevent this, set the concurrency of the Lambda to something reasonable. By default, AWS sets a limit of 1000 concurrent executions for all the Lambdas combined in your account, of which you can assign 900 and the other 100 is reserved for functions with no limits.
For Push model invocations (ex: S3 Events), Lambda scales with the number of incoming requests until concurrency or account limit is reached. For all Pull model invocation types, scaling is not instant. For the stream-based Pull model with Request Response invocation types (ex: DynamoDB Streams and Kinesis) the amount of concurrent Lambdas running will be the same as the amount of shards for the stream.
As opposed to the non-stream based Pull model with Request Response invocation types (ex: SQS), Lambdas will be gradually spun up to clear the Queue as quick as possible. Starting with five concurrent Lambdas, then increasing with 60 per minute up to 1000 in total, or until the limits are reached again.
8) Cold starts
Each Lambda is an actual container on a server. When your Lambda is invoked it will try to send the data to a warm Lambda, a Lambda container that is already started and just sitting there waiting for event data. If it does not find any warm Lambda containers, it will start/launch a new Lambda container, wait for it to be ready and then send the event data. This wait time can be significant in certain cases.
Take note that if a container does not receive event data for a certain period it will be destroyed, reducing the number of warm Lambdas for your function. Certain compiled type languages like Java can take many seconds for a cold start, whereas interpreted languages like JavaScript and Python usually takes milliseconds. When your Lambda is inside a VPC, the cold start time increases even more as it needs to wait for an ENI (private IP address) before being ready.
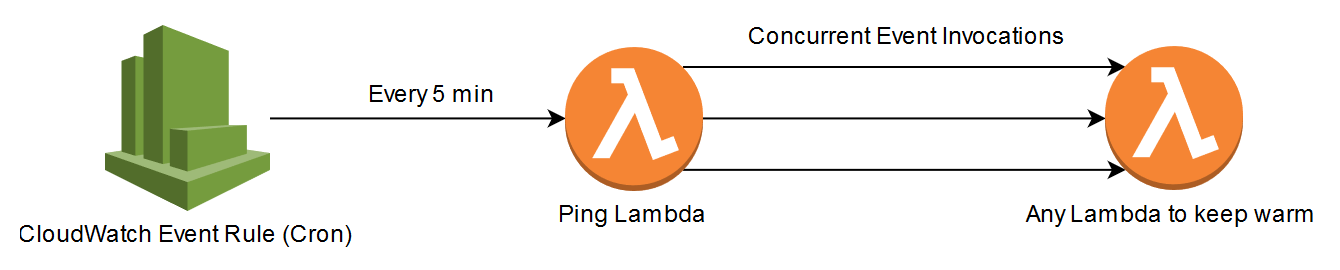
Even milliseconds can be significant in certain environments. The only method to keep a container warm is to manually ping it. This is usually done with a Cloudwatch Event Rule (cron) and another Lambda, the cron can be set for five minutes. The CloudWatch rule will invoke the Lambda that will ping the function that you want to keep warm, keep in mind that one ping will only keep one warm Lambda container alive. If you want to keep three Lambda containers warm, then the ping Lambda must concurrently invoke the function three times in parallel.
[UPDATE: Improved VPC networking]
- The Hyperplane now creates a shared network interface when your Lambda function is first created or when its VPC settings are updated, improving function setup performance and scalability. This one-time setup can take up to 90 seconds to complete.
- Functions in the same account that share the same security group:subnet pairing use the same network interfaces. This means that there is not longer a direct correlation between Concurrent Lambdas and ENIs.
Posted on October 14, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
