Purpose of Indexing in Database

Pranati
Posted on November 28, 2019
The flat file consisting of rows (records) and columns and it takes a lot of blocks to store those records
The records of the file must be allocated to disk blocks as block is the unit of data that transfers between disk and memory.
To store files in a block is termed as File Organisation.
Ordered Organisation: We store the file in sequential order. If the ordering key is also a key field then the field is called ordering key for the file. Binary Search is used to search a record.
Unordered Organisation : In this records are added as they’re inserted so new records are at the end of file. It uses heap data structure.
Below is the records divided into blocks there are total 1000 blocks. In normal sequential file where we use Binary search to search an record we go to the middle element and check it value which also consumes a lot of time.
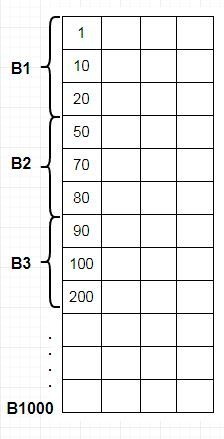
In Indexing it’s like a book index which will directly take you the page number in our case the block number to which a record belongs or present in it.
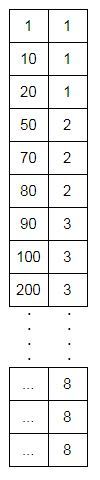
The index table consists of the key and a pointer to the location of record in the block.
Suppose we want to find record 10 we will direct locate it’s respective pointer in this case it is 10 then using the pointer value.
• Index record contains two fields (structure of the index file)-
• The key of the original file
• Pointer to the block where the key is available in the original data records
• Binary search is used to search through the indices.
To access a record using indexed enteritis number of block accesses required-
log2Bi+1 , where Bi is the number of blocks in the indexed records
Without Indexing Time Complexity
• Ordered file of r=50000 records
• Block size B =1024 bytes
• Records Fixed sized and unspanned with record length R=100 bytes
• (a) Blocking Factor Bfr = B/R = 1024/200 = 5 records per block
• (b)Numberofblocksneededforfileis
• b= r/bfr = 50000/5 = 10000 blocks
• (c)Abinarysearchonthedatafilewouldneed approx
• log2b = log210000 = 13 block accesses
Indexing values and searching records using Binary Time Complexity
•ordering key V=15bytes long and block pointer P=5bytes long
•Size of each index entry Ri = 20 bytes
•(a) Blocking factor bfri = 1024/20 = 51 entries per block
•(b) Number of entries ri = number of blocks in data file Number of blocks needed for index is
• bi= ri/bfri = 10000/51 = 196 blocks
•(c) A binary search of index file would need
• log2bi = log2196 = 8 block accesses
•PLUS one block access into the data file itself using the pointer
(d) Therefore 9 block accesses needed.
Indexing values using linear Search and searching records using Binary Time Complexity
(a) Linear search requires b/2=10000/2=5000 block accesses Suppose a secondary index on a field of V=9bytes
Thus Ri = 9+6 = 15bytes
(b) bfri = B/Ri = 1024/15 = 68 entries per block
Number of index entries ri = number of records = 50,000
Number of blocks need is bi= ri/bfri = 50000/68 = 735 blocks
(c) A binary search of index file would need
log2bi = log2735 = 10 block accesses
PLUS one block access into the data file itself using the pointer
(d) Therefore 11 block accesses
As from the above calculations the binary search optimisation wins in both the cases to search the indices and average record lookup in the index tables.
There are different types of Indexes which uses different strategies to find the record we will see that in the next post.
Resources:
https://www.datacamp.com/community/tutorials/introduction-indexing-sql
https://gradeup.co/file-organization-i-5282706f-c5a6-11e5-b9cf-3799afe3355e
Posted on November 28, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.