Scraping Google Scholar with Perl and Mojo

Gaurav Rai
Posted on January 18, 2021

Today we will learn about web scraping in which Perl excels.
Again there are various tools and modules available in Perl which can perform this task.
- LWP::UserAgent with XML::LibXML or HTML::TreeBuilder
- WWW::Mechanize with XML::LibXML or HTML::TreeBuilder
- Mojo::UserAgent with Mojo::DOM
All 3 are powerful and recommended. Its up to user preference and what he want to do.
In this article we will take a look at 2 items of Mojo stack - Mojo::UserAgent and Mojo::DOM
So what is Google Scholar. According to there about page -
Google Scholar provides a simple way to broadly search for scholarly literature. From one place, you can search across many disciplines and sources: articles, theses, books, abstracts and court opinions, from academic publishers, professional societies, online repositories, universities and other web sites. Google Scholar helps you find relevant work across the world of scholarly research.
For our demo we will be scraping the google scholar for the article of a particular author.
Lets get started with the basic code of fetching the data.
#!/usr/bin/env perl
use strict;
use warnings;
use Mojo::UserAgent;
sub crawl_results {
my ($ua, $url) = @_;
my $response = $ua->get($url)->result;
if ($response->is_success) {
# We are able to get the results
}
}
else {
croak $response->message;
}
}
sub main {
my $base_url = "https://scholar.google.com/scholar";
my $url = Mojo::URL->new($base_url);
# Getting all the article for a paricular author
$url = $url->query({"as_q" => "author:\"kshama Rai\"", "hl" => "en"});
my $ua = Mojo::UserAgent->new;
$ua->transactor->name('Mozilla/5.0');
crawl_results($ua, $url);
}
main();
- Here we are building the url with the help of Mojo::URL
- Next we are adding the
query parametersas hashref by using query function. There are various query parameters available. For simplicity purpose I have used onlyas_qbut you can add more based upon your requirement. These are -
{
"as_ylo" => <Lowest year in year range>,
"as_yhi" => <Highest year in year range>,
"as_vis" => <Include citations(0|1) (Doesn't include citation is 1)>,
"as_sdt" => <Include Patent(0|1) (Doesn't include patent is 1)>,
"scisbd" => <Sort by date(0|1)>
"as_publication" => <Journal/Source name>
"hl" => <Language of the result/output, "en" means english>,
"as_q" => "<Title of the article to search> author:<name>"
}
- Next we are creating object of Mojo::Useragent for doing the request work. We are updating the user-agent string to look like we are coming from browser. More info - Mojo::UserAgent::Transactor
- After that we are doing the
getrequest on the url and checking whether it get succeed or not.
Now lets go to google scholar page and search for the author article and see what is the result.
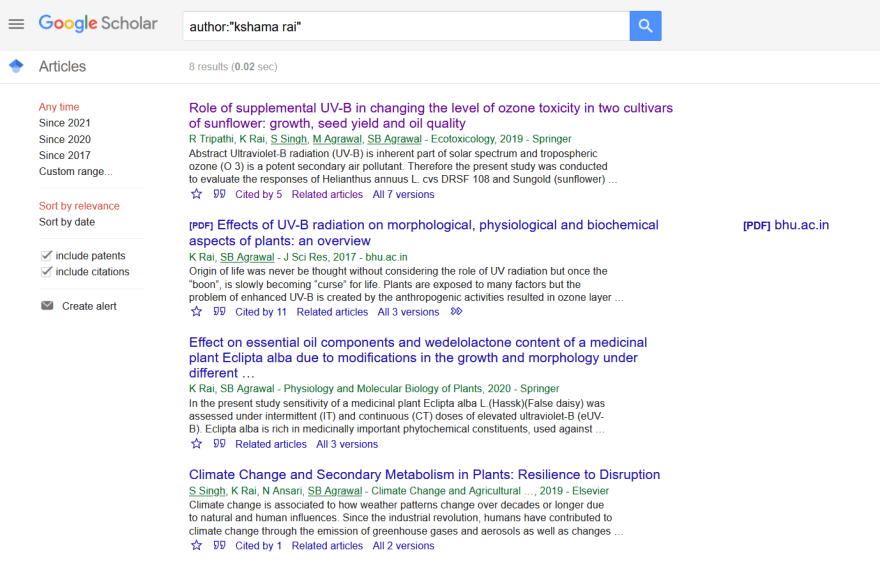
If we inspect element we can find more detail about the HTML tag and class.
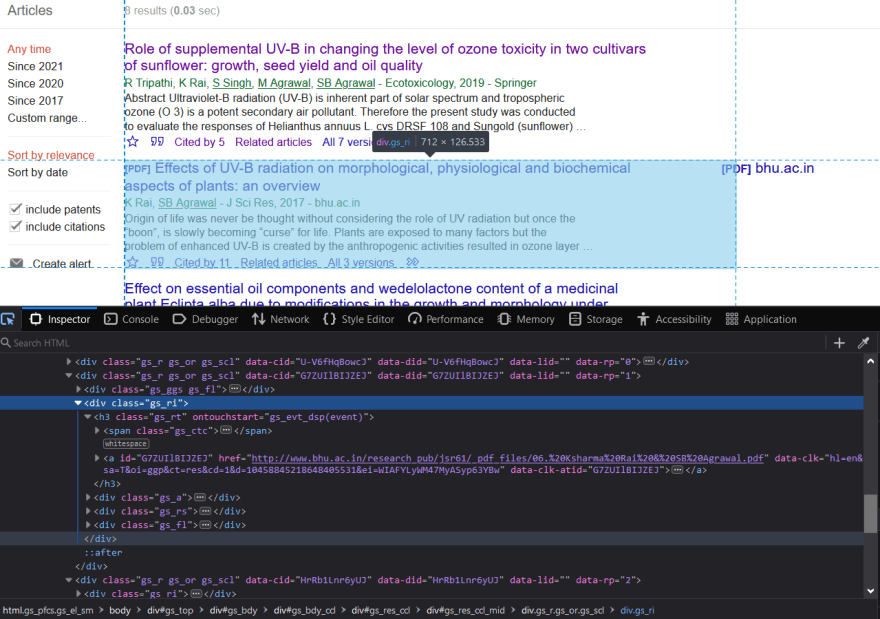
If we look in the inspector we can see -
- Each result is in the
divhaving class namegs_ri. All the other element are embedded inside it. All the other results have there owndivwith the same class name i.e.gs_ri. -
Title and Link of the research paper is an
anchorinsideh3having class namegs_rt. -
Author and Journal name are inside
divwith class namegs_a. -
Abstract is inside
divwith class namegs_rshaving line breaks. -
Citation is inside
divwith class namegs_fl
Lets try to translate our finding into code.
#!/usr/bin/env perl
use strict;
use warnings;
use Mojo::UserAgent;
use Data::Dumper;
use open ':std', ':encoding(UTF-8)';
sub crawl_results {
my ($ua, $url) = @_;
my $response = $ua->get($url)->result;
if ($response->is_success) {
# https://docs.mojolicious.org/Mojo/DOM#find
my $divs = $response->dom->find('div.gs_ri');
my @publications;
for my $div ($divs->each) {
# For getting the title
# https://docs.mojolicious.org/Mojo/Collection#map
# https://docs.mojolicious.org/Mojo/Collection#join
my $title = $div->find('h3.gs_rt a')->map('text')->join("\n");
if (defined $title && $title ne "") {
my $article = {};
$article->{"Title"} = "$title";
my $anchor_link = $div->find('h3.gs_rt a')->map(attr => 'href')->join("\n");
if (defined $anchor_link && $anchor_link ne "") {
$article->{"Link"} = "$anchor_link";
}
# For getting the abstract
my $abstract = $div->find('div.gs_rs')->map('text')->join("\n");
if (defined $abstract && $abstract ne "") {
$article->{"Abstract"} = "$abstract";
}
# For getting the journal name
my $journal = $div->find('div.gs_a')->map('text')->map(
# Remove the '-' and extra space from start
sub {
my ($aut_name, $journal) = split(/-/, $_, 2);
$journal =~ s/^\s?//;
return $journal;
}
)->join("\n");
if (defined $journal && $journal ne "") {
$article->{"Journal"} = "$journal";
}
# For getting the citation
# https://docs.mojolicious.org/Mojo/Collection#grep
my $citation = $div->find('div.gs_fl a')->grep(
# It contain the string like 'Cited by 5'.
sub { $_->text =~ /Cited by/ }
)
->map('text')
->join("\n");
if (defined $citation && $citation ne "") {
$article->{"Citation"} = "$citation";
}
push(@publications, $article);
}
}
return \@publications;
}
else {
croak $response->message;
}
}
sub main {
my $base_url = "https://scholar.google.com/scholar";
my $url = Mojo::URL->new($base_url);
# Getting all the article for a particular author
$url = $url->query({"as_q" => "author:\"kshama Rai\"", "hl" => "en"});
my $ua = Mojo::UserAgent->new;
$ua->transactor->name('Mozilla/5.0');
my $output = crawl_results($ua, $url);
print Dumper($output);
}
main();
I have added the comments for clarity. Have a look at those links for more info.
I have pushed the parsed data into array for dumping it on screen.
The output sometimes contains Unicode character. Hence, We are telling the Perl parser to allow UTF-8 in the program text in use open.
Save the file and run it.
You will get below output -
[
{
'Link' => 'https://link.springer.com/article/10.1007/s10646-019-02020-6',
'Citation' => 'Cited by 5',
'Title' => 'Role of supplemental UV-B in changing the level of ozone toxicity in two cultivars of sunflower: growth, seed yield and oil quality',
'Journal' => 'Ecotoxicology, 2019 - Springer',
'Abstract' => "Abstract Ultraviolet-B radiation (UV-B) is inherent part of solar spectrum and tropospheric ozone (O 3) is a potent secondary air pollutant. Therefore the present study was conducted to evaluate the responses of Helianthus annuus L. cvs DRSF 108 and Sungold (sunflower)\x{a0}\x{2026}"
},
{
'Link' => 'http://www.bhu.ac.in/research_pub/jsr61/_pdf_files/06.%20Ksharma%20Rai%20&%20SB%20Agrawal.pdf',
'Title' => 'Effects of UV-B radiation on morphological, physiological and biochemical aspects of plants: an overview',
'Citation' => 'Cited by 11',
'Abstract' => "Origin of life was never be thought without considering the role of UV radiation but once the \x{201c}boon\x{201d}, is slowly becoming \x{201c}curse\x{201d} for life. Plants are exposed to many factors but the problem of enhanced UV-B is created by the anthropogenic activities resulted in ozone layer\x{a0}\x{2026}",
'Journal' => 'J Sci Res, 2017 - bhu.ac.in'
},
{
'Journal' => 'Physiology and Molecular Biology of Plants, 2020 - Springer',
'Abstract' => "In the present study sensitivity of a medicinal plant Eclipta alba L.(Hassk)(False daisy) was assessed under intermittent (IT) and continuous (CT) doses of elevated ultraviolet-B (eUV-B). Eclipta alba is rich in medicinally important phytochemical constituents, used against\x{a0}\x{2026}",
'Title' => "Effect on essential oil components and wedelolactone content of a medicinal plant Eclipta alba due to modifications in the growth and morphology under different\x{a0}\x{2026}",
'Link' => 'https://link.springer.com/content/pdf/10.1007/s12298-020-00780-8.pdf'
},
{
'Link' => 'https://www.sciencedirect.com/science/article/pii/B9780128164839000050',
'Abstract' => "Climate change is associated to how weather patterns change over decades or longer due to natural and human influences. Since the industrial revolution, humans have contributed to climate change through the emission of greenhouse gases and aerosols as well as changes\x{a0}\x{2026}",
'Journal' => "Climate Change and Agricultural\x{a0}\x{2026}, 2019 - Elsevier",
'Citation' => 'Cited by 1',
'Title' => 'Climate Change and Secondary Metabolism in Plants: Resilience to Disruption'
},
{
'Title' => 'HOST PATHOGEN INTERACTIONS BETWEEN DROSOPHILA MELANOGASTER AND BEAUVERIA BASSIANA _ A Thesis Presented to the',
'Journal' => '2019 - search.proquest.com',
'Abstract' => "Drosophila melanogaster is an established model organism for immunity as their immune system is similar to insect disease vectors and pests and also shares similarities with that of the mammalian innate immune system. Our study uses the entomopathogenic fungus\x{a0}\x{2026}",
'Link' => 'http://search.proquest.com/openview/868d2826bca7969ea2c29d15273af87b/1.pdf?pq-origsite=gscholar&cbl=18750&diss=y'
},
{
'Title' => 'Low weight gain as a predictor for development of retinopathy of prematurity',
'Abstract' => "Page 1. i \x{201c}LOW WEIGHT GAIN AS A PREDICTOR FOR DEVELOPMENT OF RETINOPATHY OF PREMATURITY\x{201d} By Dr. KSHAMA RAI MBBS Dissertation Submitted to the Rajiv Gandhi University of Health Sciences, Karnataka, Bangalore In partial fulfilment of the requirements\x{a0}\x{2026}",
'Journal' => '2018 - 112.133.228.240',
'Link' => 'http://112.133.228.240/xmlui/bitstream/handle/123456789/1156/Synopsis.pdf?sequence=1'
},
{
'Title' => 'Use of High Resolution Remote Sensing Data and GIS Techniques for Monitoring Of \'U\'Shaped Wetland At GB Nagar District, Uttar Pradesh',
'Journal' => 'gyanvihar.org',
'Abstract' => "In developing countries of the world, the ever increasing population and to fulfill its need for housing and other economic activities almost urban fringe are getting encroached and our surrounding environment and natural wetlands, water bodies and other biological cycles are\x{a0}\x{2026}",
'Link' => 'https://www.gyanvihar.org/researchjournals/c3w/Chapter-2%20Use%20Of%20High%20Resolution%20Remote%20Sensing%20Data%20And%20GIS%20Techniques%20For%20Monitoring%20Of%20_U_%20Shaped%20Wetland%20At%20G.B.%20Nagar%20District,%20Uttar%20Pradesh.pdf'
}
];
Perl onion logo taken from here
Mojolicious logo taken from here
Google scholar logo taken from here
{kind=link}
{kind=link}
Posted on January 18, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related