How Autotracking Works

Kristen
Posted on February 28, 2020
This blog post is the third in a series on autotracking, the new reactivity system in Ember.js. I also discuss the concept of reactivity in general, and how it manifests in JavaScript.
- What Is Reactivity?
- What Makes a Good Reactive System?
- How Autotracking Works ← This post
- Autotracking Case Study - TrackedMap
- Autotracking Case Study - @localCopy
- Autotracking Case Study - RemoteData
- Autotracking Case Study - effect()
In the previous blog post, we discussed a number of reactivity models and extracted a few principles for designing reactive systems:
- For a given state, no matter how you arrived at that state, the output of the system is always the same
- Usage of state within the system results in reactive derived state
- The system minimizes excess work by default
- The system prevents inconsistent derived state
In this post, we'll dive into autotracking to see how it works, and how it fulfills these design principles.
Memoization
Last time, we ended on Elm's reactivity model and how (I thought) it used memoization as a method for minimizing excess work. Memoization is a technique where we cache the previous arguments that a function was called with along with the result they produced. If we receive the same arguments again, then we return the previous result.
But it turns out I was wrong about about Elm using it by default. An Elm user helpfully pointed out to me after reading that post that Elm does not memoize by default, but does provide a way to add memoization to components easily when you want to add it. I made my mistake here by taking the original Elm whitepaper for granted, without digging too deeply into the actual state of the framework today.

However, I still think memoization is the best way to understand what autotracking is doing. And it actually turns out that the reason Elm doesn't use it by default relates to the types of problems that autotracking solves quite a lot!
The issue comes down to equality in JavaScript. In JS, objects and arrays are not equal to one another even if they contain exactly the same values.
let object1 = { foo: 'bar' };
let object2 = { foo: 'bar' };
object1 === object2; // false
When memoizing, this presents us with a dilemma - if one of the arguments to your function is an object, how can you tell if any of its values have changed. Recall this example from the last post:
// Basic memoization in JS
let lastArgs;
let lastResult;
function memoizedRender(...args) {
if (deepEqual(lastArgs, args)) {
// Args
return lastResult;
}
lastResult = render(...args);
lastArgs = args;
return lastResult;
}
In this example, I used a deepEqual function to check the equality of lastArgs and args. This function isn't defined (for brevity) but it would check the equality of every value in the object/array, recursively. This works, but this strategy leads to its own performance issues over time, especially in an Elm-like app where all state is externalized. The arguments to the top level component will get bigger and bigger, and that function will take longer and longer to run.
So, lets assume that's off the table! Are there any other options? Well, if we aren't memoizing based on deep-equality, then the only other option is to memoize based on referential equality. If we're passed the same object as before, then we assume nothing has changed. Let's try this on a simplified example and see what happens.
let state = {
items: [
{ name: 'Banana' },
{ name: 'Orange' },
],
};
const ItemComponent = memoize((itemState) => {
return `<li>${itemState.name}</li>`;
});
const ListComponent = memoize((state) => {
let items = state.items.map(item =>
ItemComponent(item)
);
return `<ul>${items.join('')}</ul>`;
});
let output = ListComponent(state);
In this example all we're trying to create is a string of HTML (much simpler than actually updating and maintaining real DOM, but that's a topic for another post). Does memoization based on referential equality help us if all we want to do is change the name of the first item in the list?
For starters, it depends on how we perform this update. We could either:
- Create an entirely new
stateobject, or... - Update the part of the
stateobject that changed
Let's try strategy 1. If we blow away the state for every render, and start fresh, then memoization for any object will always fail. So, our ListComponent and ItemComponent functions will both always run again. So clearly, this doesn't work.
What if we try strategy 2? We update only the name property of the first item in the list.
state.items[0].name = 'Strawberry';
let output = ListComponent(state);
This won't work because the state object hasn't changed now, so the ListComponent function will return the same output as last time.
In order for this to work, we would have to update every object and array in the state tree that is a parent of the final, rendered state that has changed, and keep every other node in that tree the same. In a large application, which could have many state changes occur in a single update, this would be incredibly difficult to keep straight, and would almost definitely be as expensive (if not more expensive) than our deepEqual from before.
// This only gets worse in the general case
let [firstItem, restItems] = state.items;
state = {
...state,
items: [
{ ...firstItem, name: 'Strawberry' },
...restItems
]
};
So that strategy doesn't work either. Even with all of our state externalized, we can't memoize by default - we have to opt-in every time and design a very particular part of the tree to be memoized.
This problem may be solved for Elm-like applications in the future, if TC39 ends up moving forward with Records and Tuples. This would allow value equality to work with object-like and array-like data structures, making this a non-issue for them. But the future there is uncertain (it's only stage 1 at the moment), and it only works for apps that follow the externalized state pattern to the extreme. Otherwise, all we have is referential equality.
But what if we could know which properties were used on that state object when rendering was happening? And what if we could know if one of them changed with very low cost? Would that open up some possibilities?
Enter Autotracking
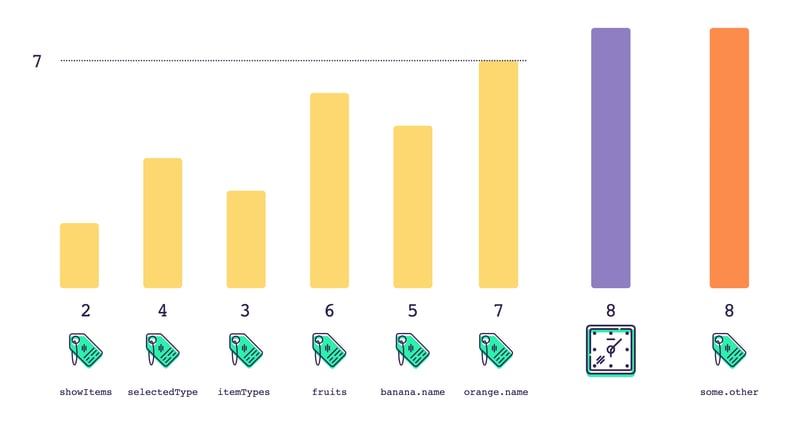
Autotracking, at its core, is about tracking the values that are used during a computation so we can memoize that computation. We can imagine a world where our memoize function is aware of autotracking. Here's an inventory component that is slightly more complex than the previous example, with autotracking integrated:
class Item {
@tracked name;
constructor(name) {
this.name = name;
}
}
class State {
@tracked showItems = true;
@tracked selectedType = 'Fruits';
@tracked itemTypes = [
'Fruits',
'Vegetables',
]
@tracked fruits = [
new Item('Banana'),
new Item('Orange'),
];
@tracked vegetables = [
new Item('Celery'),
new Item('Broccoli'),
];
}
const OptionComponent = memoize((name) => {
return `<option>${name}</option>`;
});
const ListItemComponent = memoize((text) => {
return `<li>${text}</li>`;
});
const InventoryComponent = memoize((state) => {
if (!state.showItems) return '';
let { selectedType } = state;
let typeOptions = state.itemTypes.map(type =>
OptionComponent(type)
);
let items = state[selectedType.toLowerCase()];
let listItems = items.map(item =>
ListItemComponent(item.name)
);
return `
<select>${typeOptions.join('')}</select>
<ul>${listItems.join('')}</ul>
`;
});
let state = new State();
let output = InventoryComponent(state);
In this world, memoize will track accesses to any tracked properties passed to the function. In addition to comparing the arguments that were passed to it, it will also check to see if any of the tracked properties have changed. This way, when we update the name of an item, each memoized function will know whether or not to rerender.
state.fruits[0].name = 'Strawberry';
// The outer InventoryComponent reruns, and the
// first ListItemComponent reruns, but none of the
// other components rerun.
let output = InventoryComponent(state);
Awesome! We now have a way to memoize deeply by default without doing a deep-equality check. And for the functional programmers out there, this mutation could be handled as part of a reconciliation step (I imagine Elm could compile down to something like this for state changes, under the hood).
But is it performant? To answer that, we need to dig into the guts of autotracking.
Revisions and Tags
The core of autotracking revolves around a single number. This number is the global revision counter.
let CURRENT_REVISION: number = 0;
Another way to think of this is as a global "clock". Except rather than counting time, it counts changes. Whenever something changes in the application, the we increase the clock's value by 1.

So, each value of the clock represents a version of state that the application was in. We were in version 0 at one point, the initial state of the app. Then we changed something, creating version 1 of the state. By incrementing the clock, we are tracking the current version of state.
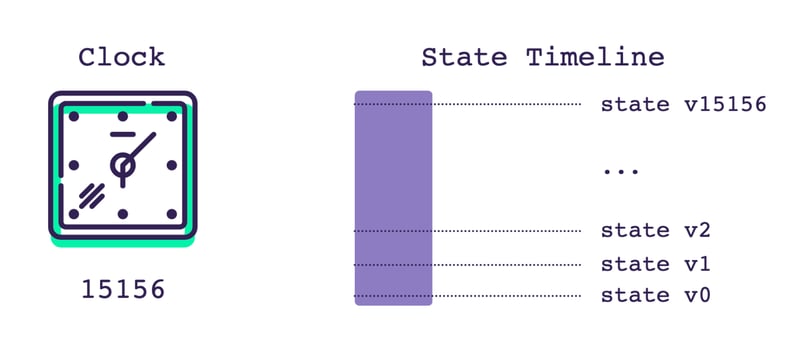
We can use a clock like this to check for very simple changes. Is the number greater than it was last time we looked? Yes? Alright, something is different, we need to update! But this doesn't help us with our memoization problem. We don't want our memoized functions to rerun whenever the clock changes, because it could have changed for completely unrelated state. We only want to rerun whenever tracked state within the function has changed. For that, we need tags.
Tags represent state within the application. For each unique piece of updatable state that is added to the system, we create a tag and assign it to that state.
Tags take their name from HTTP ETags, which were an optional part of the HTTP spec. ETags were essentially a way for browsers to check if anything had changed on a page before reloading it, and conceptually are very similar.
Tags have a single value, which is a version from the clock. Whenenever we modify the state that tag represents, we dirty the tag. To do this, we increase the value of the clock, and then we assign its new value to the tag.
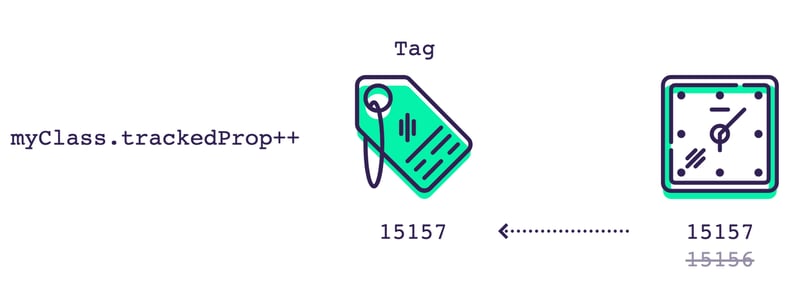
So the tag essentially stores the last version that this state was updated at. Following the clock metaphor, this was the last point in time the state was updated.
Now for the memoization. As we run our program the first time, and we use every piece of state, we we collect these tags, and save them along with the result of the computation. This is called tag consumption.

We also save the current maximum version of all of the tags we've collected. This represents the most recent version for all of the state we accessed. Nothing has been modified within this computation since that version.
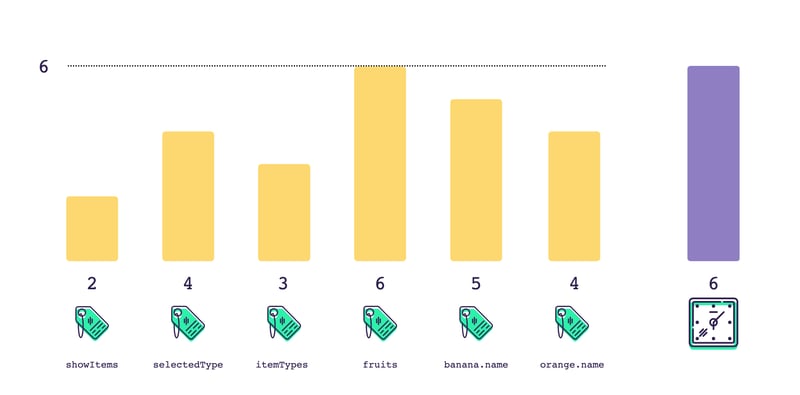
The next time we come back to this computation, we get the maximum version of all the tags again. If any one of them has been dirtied, it will be the most recent version of state. And that version will necessarily be higher than the maximum possible value last time we checked.
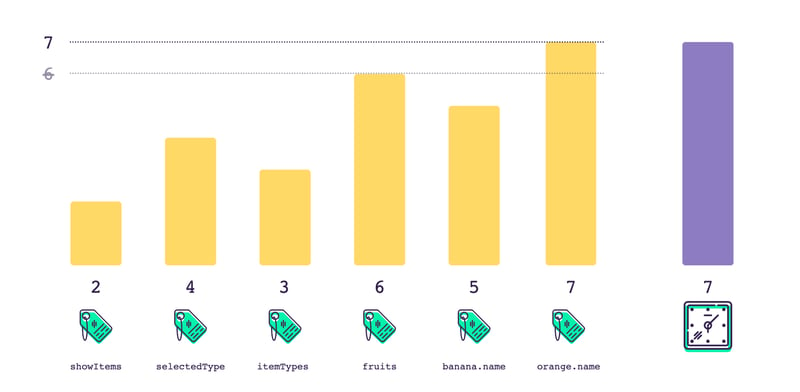
So, if the value is higher, then we know that something has changed! We rerun the computation and get the new result.
We can also look at the opposite case - what happens when we update state elsewhere in the application. Like before, we bump the global clock and assign its value to the tag that was updated.
But when we go to check if our memoized function needs to rerun, since we are only checking the values of the tags that were used within it, they will return the same maximum as last time. So our function only reruns when it should, unrelated changes will not affect it.
Fulfilling the Principles
The overhead of this form of memoization is, on its own, pretty low. Listing out the different actions involved:
- Tag creation. We create an object with a single property for each piece of mutable root state, the first time that state is created and used.
-
Consumption. As the function is running, we keep a
Setof values and push tags into it. -
Dirtying. When we update state, we increase a number (
++) and we assign its value once. -
Validating. When we finish a computation, we take all of the revisions (
Array.mapto get them) and then get the maximum value from them (Math.max). When revalidating, we do this again.
Each of these operations is very cheap. They do scale as we add state to the system, but minimally so. In most cases, as long as we aren't adding excessive amounts of state, it will likely be very fast - much faster than rerunning the computations we want to memoize.
So, this system absolutely fulfills principle number 3:
3. The system minimizes excess work by default
But what about the remaining principles? Let's go through them one by one.
Principle 1: Predictable Output
1. For a given state, no matter how you arrived at that state, the output of the system is always the same
To answer this, let's start out with the original ListComponent from the beginning of this post, converted to use @tracked.
class Item {
@tracked name;
constructor(name) {
this.name = name;
}
}
class State {
@tracked items = [
new Item('Banana'),
new Item('Orange'),
];
}
const ItemComponent = memoize((itemState) => {
return `<li>${itemState.name}</li>`;
});
const ListComponent = memoize((state) => {
let items = state.items.map(item =>
ItemComponent(item)
);
return `<ul>${items.join('')}</ul>`;
});
let state = new State()
let output = ListComponent(state);
ListComponent is a pure function. It does not modify the state as it is running, so we don't have to worry about unpredictability caused by that. We know that if we don't memoize at all, and we pass a given state object to it, it will always return the same output. So, the question for this example is whether or not the memoization works correctly. Based on the way autotracking works, as long as all properties and values that are mutated are marked with @tracked or have a tag associated with them, it should.
So it works for simple functions that only use arguments and don't mutate any state. What about something a little bit more complex? What if the function had an if statement in it, for instance?
class Item {
@tracked name;
constructor(name) {
this.name = name;
}
}
class State {
@tracked showItems = false;
@tracked items = [
new Item('Banana'),
new Item('Orange'),
];
}
const ItemComponent = memoize((itemState) => {
return `<li>${itemState.name}</li>`;
});
const ListComponent = memoize((state) => {
if (state.showItems) {
let items = state.items.map(item =>
ItemComponent(item)
);
return `<ul>${items.join('')}</ul>`;
}
return '';
});
let state = new State();
let output = ListComponent(state);
In this example we would expect the output to be empty on initial render, since showItems is false. But that also means we never accessed the items array, or the names of the items in it. So if we update one of them, will our output still be consistent?
It turns out it will, since those values didn't affect the result in the first place. If showItems is false, then changes to the rest of the list items shouldn't affect the output - it should always still be an empty string. If showItems changes, however, then it will change the output - and it will consume all of the other tags at that point. The system works out correctly in this case.
So, complex functions with branching and loops work correctly. What about functions that don't just use the arguments passed to them? Many applications also end up using external state in their functions - JavaScript certainly allows that. Does autotracking still ensure predictable output if our function does this? Let's consider another example:
class Locale {
@tracked currentLocale;
constructor(locale) {
this.currentLocale = locale;
}
get(message) {
return this.locales[this.currentLocale][message];
}
locales = {
en: {
greeting: 'Hello',
},
sp: {
greeting: 'Hola'
}
};
}
class Person {
@tracked firstName;
@tracked lastName;
constructor(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}
let locale = new Locale('en');
let liz = new Person('Liz', 'Hewell');
const WelcomeComponent = memoize((person) => {
return `${locale.get('greeting')}, ${person.firstName}!`;
});
let output = WelcomeComponent(liz);
In this example, we pass a person to the WelcomeComponent to render a greeting. But we also reach out to the local locale variable, which is an instance of the Locale class, used for translating.
What if we changed that language in the future? Would our WelcomeComponent's output properly update, the next time we called it?
The answer is once again yes - the tag associated with currentLocale was properly consumed when we ran it the first time, it doesn't matter that it was external. So, updating it to 'sp' will cause WelcomeComponent to rerender in Spanish, just like if that was the original state. As long as all mutable values that are used within the function are properly tracked, the function will update consistently, no matter where they come from.
Finally, what if the function mutates state as it's running? This one is trickier, and it's really one of the roots of many issues within reactive systems. For instance, let's consider a different version of a ListComponent:
class State {
@tracked items = [];
}
const ListComponent = memoize((state) => {
state.items = [...state.items, Math.random()];
let items = state.items.map(item => `<li>${item}</li>`);
return `<ul>${items}</ul>`;
});
let state = new State();
let output = ListComponent(state);
It seems like this component undermines our system! Every time this list re-renders, it'll add a new value, incrementing value. And since we memoize at the end of the function, it also means that we'll lock in that value until something else changes the items array. This is very different semantically than what would happen if we hadn't memoized the component.
This is a case where autotracking has a weakness - it is possible to write code that abuses its semantics like this. We could potentially lock down all tracked state and prevent it from changing at all during computation. But there are lots of valuable patterns where updating state - and even more often, creating new state_ - does make sense, so we unfortunately cannot prevent changes altogether. I'll be exploring some of these patterns in future case studies to show exactly what I mean there.
However, most real world use cases don't involve a constantly growing list of items. Let's look at something a bit more realistic.
class State {
@tracked items = [];
}
const ListComponent = memoize((state) => {
if (state.items.length === 0) {
state.items = ['Empty List'];
}
let items = state.items.map(item => `<li>${item}</li>`);
return `<ul>${items}</ul>`;
});
let output = ListComponent(new State());
In this case, we're only pushing into the array if we detect that it is empty. This seems more like something someone would actually write, but definitely has a codesmell. This type of mutation could cause quite a bit of unpredictability, since we won't know the final state of the program until after we run it.
However, in this case autotracking knows this, and prevents us from following this pattern. Autotracking has a rule, meant to help guide users toward more declarative and predictable code - if state has already been read during a computation, it can no longer be mutated. So, this series of statements:
if (state.items.length === 0) {
state.items = ['Empty List'];
}
Would throw an error! We've just read state.items to get the current state, we can no longer update it during the same computation.
So, autotracking results in predictable output for most reasonable uses, and guides users towards predictable output. We had to go out of our way to get something quirky, and usually autotracking will throw errors if we're doing something bad (though there are still some failure cases).
I think this is pretty good personally! Computed properties in Ember Classic had the same quirks and edge cases along with others (such as depending on values you didn't use in the computation), but with significantly more overhead, both for the computer and for the programmer. And most other reactive systems, such as Rx.js or MobX, can also be abused in similar ways. Even Elm would have it, if it allowed mutations like JavaScript does (just part of the reason they invented a new language).
Principle 2: Entanglement
2. Usage of state within the system results in reactive derived state
Autotracking is entirely consumption based. Tags are added when tracked properties (and other reactive state) are accessed, and only when they are accessed. There is no way to accidentally access a value without adding its tag, so we can't end up in the types of situations that event listeners can cause, where we forgot to register something that should update.
In addition, state dirties its tag when updated, so there's no way we could accidentally forget to notify the system when something has changed. However, we probably want to also do something when we detect a change. Autotracking has this covered as well, via the setOnTagDirtied API:
let currentRender = false;
setOnTagDirtied(() => {
if (currentRender) return;
currentRender = setTimeout(() => {
render();
currentRender = false;
});
});
This callback will be called whenever any tracked property is dirtied, and allows us to schedule an update in frameworks. It also does not receive any information about the tag that was dirtied, so it cannot be abused to add event-based patterns back into the system. It is a one way notification that allows us to schedule a revalidation, so our output will always be in sync with the input, and will always update based on usage.
Note: This API is currently called the
setPropertyDidChangeAPI in the Glimmer codebase, for historical reasons. I updated the name in this post to make it clearer what it does - it runs for any tag being dirtied, not just properties changing.
Principle 4: Consistent State
4. The system prevents inconsistent derived state
We already discussed how autotracking does allow for updates during computation, and how this can result in some edge cases that are problematic. The biggest issue that can arise is one that we discussed last time - inconsistent output during render. If we update our state halfway through, half of our output could contain the old version, while the other half contains the new version.
We saw how React handled this problem:
class Example extends React.Component {
state = {
value: 123;
};
render() {
let part1 = <div>{this.state.value}</div>
this.setState({ value: 456 });
let part2 = <div>{this.state.value}</div>
return (
<div>
{part1}
{part2}
</div>
);
}
}
In this example, setState wouldn't update the state until the next render pass. So, the value would still be 123 in part 2, and everything would be consistent. However, developers always need to keep this in mind when running code - any setState they do won't be applied immediately, so they can't use it to setup initial state, for instance.
Autotracking prevents this inconsistency differently. Like I mentioned before, it knows when you first use a value, and it prevents you from changing it after that first usage.
class Example extends Component {
@tracked value;
get derivedProp() {
let part1 = this.doSomethingWithValue();
// This will throw an error!
this.value = 123;
let part2 = this.doSomethingElseWithValue();
return [part1, part2];
}
// ...
}
If any state has been used during a computation, it can no longer be updated - it is effectively locked in. This guides users to write better, more predictable code, and it also prevents any inconsistency from entering the output of memoized functions. This is a core part of the autotracking design, and one of the main helpers for writing declarative, predictable code within this system.
So, autotracking does fulfill all of the principles! And it does so with an incredibly minimal, low-overhead approach.
An Implementation is Worth a Thousand Words
Autotracking is, in many ways, the core that powers Ember.js and the Glimmer VM. Reactivity is one of the first things a framework has to decide on, because it permeates every decision the framework makes after that. A good reactivity model pays dividends for the entire lifetime of the framework, while a bad one adds debt, bugs, and bloat left and right.
I think I have a bit of a unique perspective on reactivity, since I got to see a framework fundamentally change its model (and even helped to lift the finishing pieces into place). I saw how much complexity and bloat the event-based chains model added under the hood. I've seen many, many bugs resulting from the most subtle tweaks to parts of the codebase. I've fixed a few of those bugs myself. And as an Ember user for the past 7+ years, I also dealt with the knock-on effects of that complexity in my own applications.
By contrast, autotracking is like a breath of fresh air. In part, because it's much more efficient. In part, because its pull-based nature makes it much easier to reason about code. And in part, because the new patterns and restrictions it adds encourage leaner, more consistent code.
But I think more than anything, I love it for its simplicity. And to demonstrate just how simple it is, here is the most minimal implementation of autotracking I could think of:
type Revision = number;
let CURRENT_REVISION: Revision = 0;
//////////
const REVISION = Symbol('REVISION');
class Tag {
[REVISION] = CURRENT_REVISION;
}
export function createTag() {
return new Tag();
}
//////////
let onTagDirtied = () => {};
export function setOnTagDirtied(callback: () => void) {
onTagDirtied = callback;
}
export function dirtyTag(tag: Tag) {
if (currentComputation.has(tag)) {
throw new Error('Cannot dirty tag that has been used during a computation');
}
tag[REVISION] = ++CURRENT_REVISION;
onTagDirtied();
}
//////////
let currentComputation: null | Set<Tag> = null;
export function consumeTag(tag: Tag) {
if (currentComputation !== null) {
currentComputation.add(tag);
}
}
function getMax(tags: Tag[]) {
return Math.max(tags.map(t => t[REVISION]));
}
export function memoizeFunction<T>(fn: () => T): () => T {
let lastValue: T | undefined;
let lastRevision: Revision | undefined;
let lastTags: Tag[] | undefined;
return () => {
if (lastTags && getMax(lastTags) === lastRevision) {
if (currentComputation && lastTags.length > 0) {
currentComputation.add(...lastTags);
}
return lastValue;
}
let previousComputation = currentComputation;
currentComputation = new Set();
try {
lastValue = fn();
} finally {
lastTags = Array.from(currentComputation);
lastRevision = getMax(lastTags);
if (previousComputation && lastTags.length > 0) {
previousComputation.add(...lastTags)
}
currentComputation = previousComputation;
}
return lastValue;
};
}
Just 80 lines of TypeScript, with a few comments for spacing. These are the low level tracking APIs, and are fairly similar to what Ember uses internally today, with a few refinements (and without a few optimizations and legacy features).
We create tags with createTag(), dirty them with dirtyTag(tag), consume them when autotracking with consumeTag(tag), and we create memoized functions with memoizeFunction(). Any memoized function will automatically consume any tags that are consumed with consumeTag() while running.
let tag = createTag();
let memoizedLog = memoizeFunction(() => {
console.log('ran!');
consumeTag(tag);
});
memoizedLog(); // logs 'ran!'
memoizedLog(); // nothing is logged
dirtyTag(tag);
memoizedLog(); // logs 'ran!'
The @tracked decorator would be implemented with these APIs like so:
export function tracked(prototype, key, desc) {
let { initializer } = desc;
let tags = new WeakMap();
let values = new WeakMap();
return {
get() {
if (!values.has(this)) {
values.set(this, initializer.call(this));
tags.set(this, createTag());
}
consumeTag(tags.get(this));
return values.get(this);
},
set(value) {
values.set(this, value);
if (!tags.has(this)) {
tags.set(this, createTag());
}
dirtyTag(tags.get(this));
}
}
}
And there are many other ways that they can be used to instrument state. We'll see one of these next time, when we dig into creating a TrackedMap class like the one provided by tracked-built-ins.
The core team expects to make these APIs publicly available in the near future, and while they may end up being a little different, this is the rough shape of what they'll look like. As such, I'll be using these APIs for future posts and examples. Don't worry about remembering them though, I'll re-explain them when I do!
Some notes on this implementation:
We use a symbol here to store the revision on
Tagbecause it should be an opaque detail, not accessible to users normally. It's only for the autotracking system. Same reason for thecreateTagfunction - right now we return an instance of theTagclass, but that could be optimized in the future.memoizeFunctiondoes not take a function that receives arguments, unlike thememoizeI used in earlier examples. Instead, it only focuses on memoizing based on autotracking/tags. This is because memoizing based on arguments actually becomes problematic at scale - you may end up holding onto cached values for quite a long time, bloating memory usage. Thememoizeshown in the code samples above could be implemented using this lower level API.
A Note on Vector Clocks
There's another reason why I called the global counter a "clock". In concurrent programming, there is a concept known as a vector clock, which is used for keeping track of changes to state. Vector clocks are usually used in distributed systems - on multiple machines that need to constantly synchronize their state.
Like our clock, vector clocks constantly "tick" forward as state changes, and check current values against previous values to see if things are in sync. Unlike our clock, there are more than one in a given system!
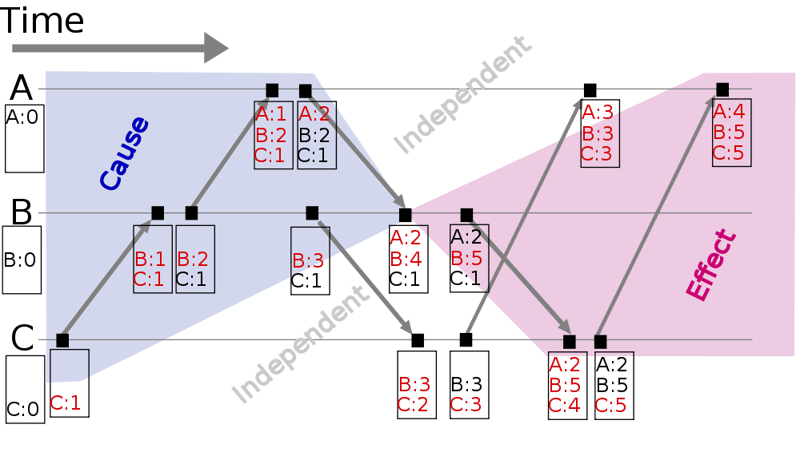
Currently we don't have to deal with this, which is nice, but in the future we actually might need to - with web workers and service workers for instance. Once you have more than one process, a single global clock no longer works on its own.
That's a ways out at the moment, but I'm excited to start exploring it when things calm down a bit. I had my start with distributed programming when I worked at Ticketfly, building a peer-to-peer ticket scanning system and it was some the most fun work I ever did.
Conclusion
As I've said before, autotracking is, to me, the most exciting feature that shipped in Ember Octane. It's not every day that a framework completely rethinks it reactivity model, and I can't think of one that did and was able to do so seamlessly, without any breaking changes.
Personally, I think that the next wave of Ember applications are going to be faster, less error prone, and easier to understand thanks to autotracking. I also think that Ember app's are just going to be a lot more fun to write 😄
I hope you enjoyed this deep dive, and I can't wait to see what the Ember community builds with this new reactive core. In the coming weeks, I'll start working through various use cases, and how to solve them with autotracking techniques, in a case studies series. If you have something you'd like to see solved, let me know!
(This blog post was originally published on pzuraq.com)
Posted on February 28, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.