Hachage cohérent dans les systèmes distribués

PubNub Developer Relations
Posted on February 8, 2024

Comment savoir où vos données doivent être stockées ? Et, tout aussi important, que se passe-t-il lorsqu'un nœud de stockage tombe en panne ou que vous ajoutez un nouveau nœud de stockage pour faire évoluer votre système ? Un hachage est un moyen courant et efficace de déterminer où vos données doivent être stockées dans ce scénario et il est particulièrement important de le comprendre si vous mettez en œuvre un type quelconque d'application de diffusion de données en continu.
Qu'est-ce que le hachage ?
Le hachage utilise des "tables de hachage" et des "fonctions de hachage" ou des algorithmes pour convertir des données de taille variable, telles qu'un fichier ou une chaîne arbitraire, en un résultat cohérent de taille fixe.
La fonction de hachage (ou algorithme de hachage cohérent) est une opération mathématique qui prend vos données et produit un nombre représentant ces données, dont la valeur est bien inférieure à la taille originale des données fournies. Le nombre produit par la fonction de hachage est appelé "hachage", et la valeur sera cohérente chaque fois que la fonction de hachage sera appelée avec les mêmes données. Vous pouvez ensuite consulter les données dans la table de hachage
Pour un exemple TRES simple, considérons l'opérateur modulo (%) comme une fonction de hachage. Quelle que soit la taille du nombre fourni à l'opérateur modulo, il renverra un nombre cohérent dans un intervalle n spécifié, pour [données] mod n :
69855 MOD 10 = 5
63 MOD 10 = 3
916 MOD 10 = 6
26666 MOD 10 = 6
Le dernier exemple illustre une "collision", où différentes entrées produisent la même valeur de hachage, 6. Vous pouvez également voir comment vous pouvez modifier la plage de sortie en ajustant la fonction de hachage, par exemple, x MOD 20 ou x MOD 30.
Dans les implémentations réelles de hachage, des fonctions de hachage plus complexes sont utilisées pour gérer les collisions et utiliser au mieux la mémoire, en fonction des données d'entrée attendues.
Pourquoi utiliser le hachage ?
Un exemple courant de hachage est le stockage et la récupération de données. Supposons que vous ayez une collection de 15 milliards d'éléments et que vous ayez besoin de récupérer un élément spécifique ; comment feriez-vous ? Un mécanisme consisterait à itérer sur votre ensemble de données, mais cette méthode est inefficace à mesure que le nombre de clés dans le magasin clé-valeur augmente ; il est préférable d'utiliser une fonction de hachage.
Il est préférable d'utiliser un hachage :
Lors du stockage des données, passez d'abord une clé associée à vos données par une fonction de hachage. En fonction du hachage obtenu, stockez vos données dans la table de hachage à l'emplacement haché. En cas de collision, vous devrez prendre des mesures pour vous assurer qu'aucune donnée n'est perdue ; par exemple, la table de hachage peut stocker une liste liée de données au lieu des données elles-mêmes (hachage en chaîne), ou votre fonction de hachage peut continuer à chercher un emplacement vide jusqu'à ce qu'elle en trouve un (les techniques comprennent l'exploration ou le double hachage).
Lorsque vous récupérez des éléments de données, vous devez à nouveau faire passer la clé associée à vos données par la fonction de hachage, puis consulter le code de hachage résultant dans votre table de hachage.
Si j'ai déjà une clé pour mes données, pourquoi ne pas utiliser cette clé directement pour stocker mes données ? Par exemple, comme index dans un tableau. Vous pouvez le faire (cela équivaut à utiliser une fonction de hachage qui ne fait rien), mais c'est très inefficace. Que se passe-t-il si vos clés sont très grandes et non contiguës ?
Le hachage dans un système distribué
L'exemple précédent traitait de l'utilisation d'une table de hachage pour stocker et récupérer une grande liste d'éléments de données, mais qu'en est-il si cette liste est physiquement répartie sur plusieurs serveurs ?
Au lieu que la fonction de hachage pointe vers un emplacement dans une table de hachage, comme dans l'exemple précédent, un système distribué peut utiliser une fonction de hachage différente dont la sortie est un identifiant de serveur, qui peut être mis en correspondance avec une adresse IP.
Par exemple : Lorsque vous stockez des données dans un système distribué, commencez par hacher une clé associée à vos données pour produire l'ID du serveur où vos données doivent être stockées, puis stockez les données sur ce serveur. Si vous avez choisi une fonction de hachage dont le résultat est uniformément réparti sur tous les serveurs disponibles, aucun de vos serveurs ne sera surchargé et vos données pourront être rapidement récupérées. Vous pouvez également envisager l'équilibrage de la charge de la même manière, c'est-à-dire en augmentant le nombre de serveurs pour équilibrer la charge des serveurs.
Supposons que vous disposiez d'une liste de cinq serveurs pouvant contenir vos données et que vous ayez attribué à chacun d'eux une identité unique, de 1 à 5. Dans cet exemple, vous décidez du serveur sur lequel stocker les données en fonction d'un hachage de la clé de ces données :
Produisez un code de hachage pour représenter la clé des données que vous stockez ; le code de hachage résultant doit être compris entre 1 et 5 (puisque nous avons 5 serveurs).
L'exemple précédent utilisait un modulo très simple pour la fonction de hachage ; l'équivalent ici serait de considérer que notre fonction de hachage est "
[clé] MOD 5".Stockez le fichier sur le serveur dont l'ID a été calculé.
Cela fonctionne, mais que se passe-t-il lorsqu'un serveur tombe en panne ? Que se passe-t-il lorsqu'un nouveau serveur est ajouté ? Dans les deux cas, toutes les données doivent être recalculées et déplacées sur la base du résultat de leur nouveau hachage - connu sous le nom de "rehashing", ce qui est inefficace et explique pourquoi l'approche ci-dessus est trop simpliste pour être utilisée dans le cadre d'une production.
Qu'est-ce que le hachage cohérent ?
Le hachage cohérent détermine où les données doivent être stockées dans un système distribué tout en tolérant l'ajout ou la suppression de serveurs, ce qui minimise la quantité de données qui doivent être déplacées ou remises en mémoire lorsque des changements d'infrastructure se produisent.
Différence entre le hachage cohérent et le hachage
Le hachage est une technique générale qui consiste à prendre une quantité variable de données et à la réduire de manière à ce qu'elle soit stockée dans une structure de stockage cohérente et de taille fixe, appelée table de hachage, pour une récupération rapide et efficace. La taille de la table de hachage choisie dépendra de la quantité de données stockées et d'autres considérations plus pratiques, telles que la mémoire système disponible. Lorsque la table de hachage est redimensionnée, la fonction de hachage change généralement aussi pour garantir que les données sont réparties uniformément dans la table nouvellement redimensionnée, ce qui signifie que toutes les données doivent être remises en mémoire et déplacées.
Le hachage cohérent est un type particulier de hachage dans lequel, lorsque la table de hachage est redimensionnée, seule une petite partie des données doit être déplacée. Plus précisément, le nombre d'éléments de données qui doivent être déplacés est n/m, où n est le nombre d'éléments de données et m le nombre de lignes dans la table de hachage (ou de serveurs, dans notre exemple précédent de système distribué).
Comment fonctionne le hachage cohérent ?
Pour rendre les choses plus intuitives, la plupart des illustrations numérotent les nœuds de 1 à 360 (degrés), mais les nombres réels choisis et le fait qu'ils soient contigus ou non n'ont pas d'importance ; ce qui compte, c'est que les ID de serveur attribués augmentent au fur et à mesure que vous tracez un itinéraire autour du cercle dans le sens des aiguilles d'une montre, d'un serveur à l'autre. L'ID du nœud suivant sera toujours supérieur au précédent, jusqu'à ce qu'il soit contourné.
Pour déterminer le serveur sur lequel les données doivent être stockées, on calcule le hachage des données, puis on prend le module de ce hachage avec 360 ; le nombre obtenu ne coïncidera probablement pas exactement avec un numéro de serveur valide, de sorte que l'ID de serveur le plus proche et le plus grand est sélectionné. S'il n'y a pas de serveur dont l'ID est plus grand que le nombre obtenu, on revient à 0 et on continue à chercher un ID de serveur.
Voici un exemple :
Il existe une clé de données à laquelle est appliquée une fonction de hachage dont le résultat est 5562.
5562 MOD 360 est égal à 162
Nous trouvons le serveur de notre déploiement dont l'ID est supérieur à 162 mais le plus proche, par exemple l'ID 175 dans le diagramme ci-dessous.

Que se passe-t-il si je n'ai pas 360 serveurs ? Ou plus de 360 serveurs ? Les chiffres n'ont pas d'importance, seul le principe compte. Tant que les ID des serveurs sélectionnés sont numérotés dans l'ordre croissant, raisonnablement espacés et disposés conceptuellement dans un anneau (connu sous le nom d'anneau de hachage).
Pourquoi utiliser un hachage cohérent ?
Nos données étant réparties sur plusieurs nœuds (ou serveurs), il devient beaucoup plus efficace d'ajouter ou de supprimer un nœud de notre système. Prenons un exemple où nous avons trois nœuds, A, B et C, avec des ID de 90, 180 et 270. Chaque nœud de notre configuration contient un tiers des données.
Si nous voulons ajouter un nouveau nœud, D, nous lui attribuons un nouvel identifiant, disons 360.
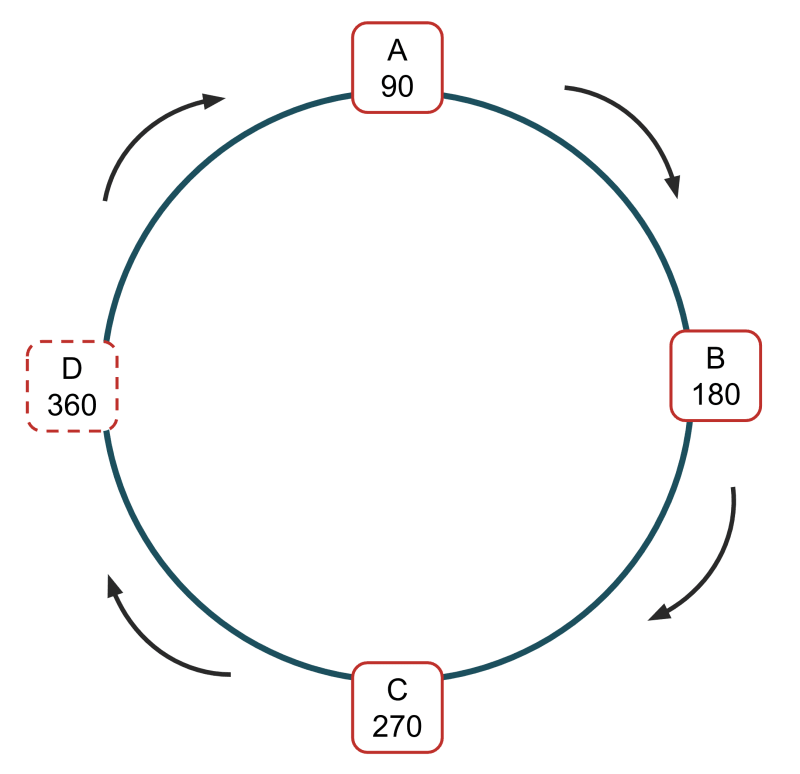
Nous avons maintenant le choix entre laisser D vide et le laisser se remplir lentement au fur et à mesure que les données sont stockées ou redistribuer les données des autres nœuds dans D. Le choix que nous faisons dépend de la solution mise en œuvre ; les implémentations de cache web et de serveur de cache feront le premier choix et laisseront les manques de cache remplir lentement D. D'autres solutions prendront la moitié des données de A et les transféreront dans D (sans entrer trop profondément dans les mathématiques, les données transférées doivent avoir un hachage dont la valeur entraînerait leur stockage dans D s'il s'agissait de nouvelles données).
Qu'est-ce qu'un service de dénomination cohérent basé sur le hachage ?
Les exemples précédents de ce billet concernaient le stockage de données ou de fichiers sur des serveurs, mais le principe peut être étendu au stockage de n'importe quelle donnée de manière distribuée. Les services de nommage font partie des systèmes les plus vastes et les plus distribués créés et se prêtent bien à une mise en œuvre par hachage cohérent. En mettant de côté le DNS pour le moment, qui a une mise en œuvre spécifique et différente, nous pourrions mettre en œuvre un service de nommage plus générique en utilisant le hachage cohérent de la manière suivante :
Les enregistrements de noms sont stockés sur plusieurs serveurs.
Les serveurs doivent se voir attribuer un identifiant et être classés par ordre croissant dans un anneau conceptuel.
Pour résoudre un nom, nous devons localiser le serveur sur lequel l'enregistrement du nom est stocké.
Il faut hacher le nom, puis prendre le module du résultat avec 360 (en supposant que nous ayons moins de 360 serveurs).
Trouver l'ID du serveur dont le nom est le plus proche mais supérieur au résultat trouvé à l'étape précédente. Si ce serveur n'existe pas, remonter jusqu'au premier serveur de l'anneau dont l'ID est le plus bas.
L'enregistrement de nom sera trouvé sur le serveur identifié.
Vous pouvez également envisager des réseaux de diffusion de contenu qui fonctionnent de manière similaire, en répartissant les demandes entre différents nœuds pour éviter les points chauds.
Mise en œuvre cohérente du hachage
Il existe de nombreuses implémentations disponibles sur Github, allant de Java à Python, où un certain nombre de nœuds sont disposés dans un anneau de hachage cohérent contenant une table de hachage distribuée.
Il existe des systèmes de stockage de production qui utilisent le hachage cohérent, tels que Redis, Akamai ou Amazon's dynamo, dont beaucoup utilisent des structures de données plus complexes, telles que memcache, la recherche binaire ou les arbres aléatoires pour l'étape finale de la recherche de données.
Étapes de mise en œuvre du hachage cohérent
Après avoir expliqué la technique sous-jacente, vous pouvez commencer à mettre en œuvre une solution de hachage cohérent, mais vous devez tenir compte des éléments suivants :
Combien de serveurs votre solution comportera-t-elle ? Ce nombre est-il appelé à croître ?
Comment allez-vous attribuer les identifiants des serveurs ?
Quelle fonction de hachage allez-vous utiliser pour créer le hachage de vos données ? Vous voudrez choisir une fonction qui produit un résultat uniforme afin que vos données ne soient pas regroupées sur un seul serveur et qu'elles soient réparties uniformément sur l'ensemble de vos serveurs.
Pensez à ce qui se passe lorsque vous ajoutez ou supprimez un serveur de votre solution. Vous devez essayer de maintenir un espacement aussi régulier que possible entre les identifiants des serveurs afin d'éviter que vos données ne soient regroupées.
Exemple de mise en œuvre du hachage cohérent
Prenons un exemple où les fichiers sont stockés sur l'un des cinq serveurs, auxquels nous attribuerons des ID de serveur compris entre 1 et 360.
Les serveurs sont disposés dans un anneau conceptuel et les ID 74, 139, 220, 310 et 340 leur sont attribués.
Nous devons stocker un nouveau fichier, nous hachons la clé de ce fichier et le résultat est 1551.
Nous effectuons 1551 MOD 360, ce qui nous donne 111
Le fichier de données sera donc stocké sur le serveur avec l'ID 139

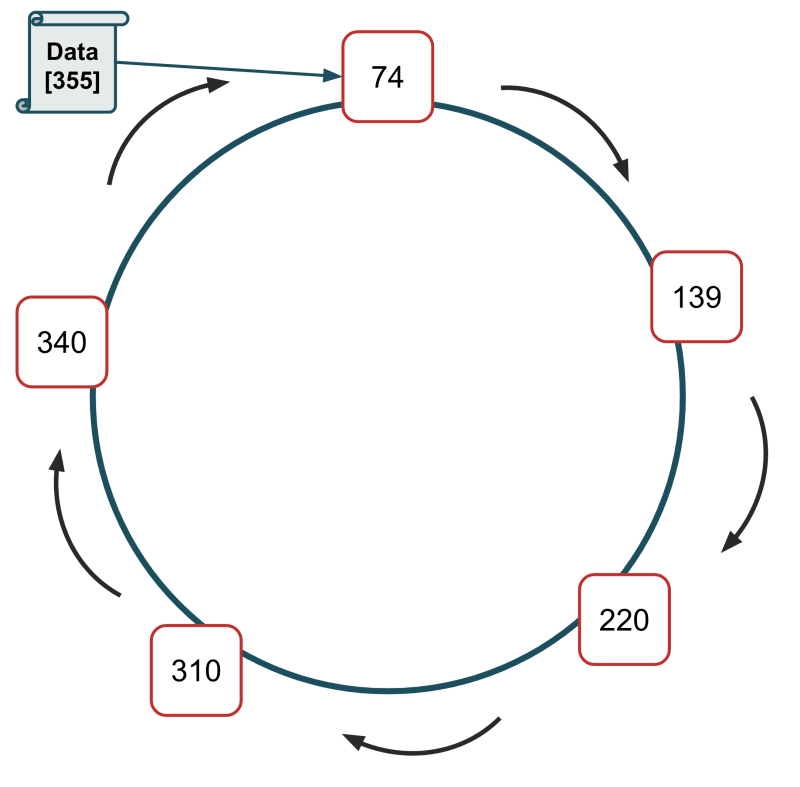
Prenons un autre exemple :
Les serveurs sont disposés dans un anneau conceptuel et les ID 74, 139, 220, 310 et 340 leur sont attribués.
Nous devons stocker un nouveau fichier, nous hachons la clé de ce fichier et le résultat est 1075.
Nous effectuons 1075 MOD 360, ce qui nous donne 355
Aucun ID de serveur ne dépasse 355 ; par conséquent, le fichier de données sera stocké sur le serveur avec l'ID 74.
Optimisation cohérente du hachage
Si un nœud (serveur) tombe en panne dans un système utilisant le hachage cohérent, toutes les données seront réaffectées au serveur suivant dans l'anneau. Cela signifie qu'un serveur défaillant doublera la charge du serveur suivant, ce qui, au mieux, gaspillera des ressources sur le serveur surchargé et, au pire, pourrait provoquer une défaillance en cascade.Une redistribution plus homogène en cas de défaillance d'un serveur peut être obtenue en faisant en sorte que chaque serveur ait un hachage à plusieurs endroits ou répliques de l'anneau. Par exemple, un serveur a 4 hachages possibles et existe donc à 4 endroits de l'anneau ; lorsque ce serveur tombe en panne, les données stockées sur ce serveur sont redistribuées à 4 endroits différents, de sorte que la charge sur tout autre serveur n'excède pas un quart supplémentaire, ce qui est plus gérable.
Mise en œuvre cohérente du hachage avec PubNub
PubNub est une plateforme API pour développeurs qui permet aux applications de délivrer des messages à grande échelle. PubNub a de multiples points de présence, ce qui lui permet de délivrer des messages de manière sûre, fiable et rapide.
Pour offrir à nos clients l'échelle et la fiabilité qu'ils attendent, nous utilisons plusieurs techniques sur notre backend, y compris le hachage cohérent.
Si vous créez une application qui a besoin d'échanger des données entre des clients ou entre un client et un serveur à l'échelle, alors vous avez probablement beaucoup plus à penser que le simple mécanisme de hachage à utiliser. Laissez PubNub gérer tous vos besoins de communication afin que vous puissiez vous concentrer sur votre logique commerciale et ne pas vous soucier de la transmission de données de bas niveau de votre application au fur et à mesure qu'elle évolue.
Si vous êtes intéressé par l'informatique de périphérie, découvrez notre solution de bus de messages de périphérie, ou explorez comment PubNub peut prendre en charge les communications et les solutions web3 de blockchain.
L'essai de PubNub est gratuit, il suffit de se connecter ou de s'inscrire pour un compte gratuit afin de créer une application ou d'expérimenter notre visite guidée pour voir ce qu'est PubNub.
Posted on February 8, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


