Avoiding the messy git history

Vlatko Vlahek
Posted on September 17, 2019

Avoiding the messy git history
If we try to name the things that have clearly defined modern software development, source control would most certainly be very high on the list, especially git which is probably the most widely used version control system today.
Days of having our code versioned in different folders locally, often prone to corruption are long gone. However, a lot of developers use git just as a means to store the source files somewhere remotely, without actually utilising some of its more advanced features that allow us to have a great, easily readable git history.
This article will cover one of the git-flow approaches, heavily based on git rebase, that will allow you to have a more streamlined git experience, especially when working inside a team. It’s a strict approach and takes a while to get used to.
The experience stems from working on bigger projects, based on the in-house practices that we have at PROTOTYP. We put a strong emphasis on code review and easy readability of all changes that happen inside our codebase.
Main goals of the approach are:
cleaner git history
fewer merge conflicts
enforcing code review
increasing branch stability
All examples in the article are done via command line, but there will be links and references on how to achieve some parts of the process in the git provider dashboards.
Initialising git flow
The first step of the journey is definitively initialising Git flow over your repository.
More thorough documentation on the matter by its original author can be found here.
In short, it’s a branching model that scaled really well for us in the past and is widely adopted.
In order to use this from the command line, you will most probably need to install git-flow. GUI solutions such as Tower or Sourcetree usually have it integrated.
You can check the installation instructions here.
Example:
// initialises git on your repository
git init
// initialises git flow on your git repo
git flow init
After initialising git flow on your repository, you will be asked for default branch names. We use the default values internally, only prefixing tags with letter “v”, so our versions are v1.0.0, v1.0.1 etc.
Feel free to use the versioning system for releases that has the most sense for your team and your product. However, semantic versioning or semver has been our weapon of choice for some time now, and while it could be an overkill for smaller one-off projects, it has proven great for releasing new features for SaaS products or mobile apps inside our company.
Each of the branches git flow introduces has its own place in the ecosystem, and understanding when to use each one is a must!
// New features
Feature branches? [feature/]
// Tags a version and merges develop to master.
// A short lived branch. Versions bumps are ok inside it.
Release branches? [release/]
// A branch done from master directly, for fast hotfix push
// We use bugfix/ name for a bugfix branch that is branched from
// develop
Hotfix branches? [hotfix/]
// Need to add some client specific code ? Use a support branch
Support branches? [support/]
// Tag for release branches
Version tag prefix? [v]
Remember, git is not some sort of a magic wand that makes all of your issues go away just by itself, nor does it have any sense in having multiple branches if you don’t know what to do with them in the first place.
Locking down develop and master branches
This one is maybe a tad controversial for people not used to this approach, but I would definitively note this as one of the most important steps in the process.
Protecting **develop* and master branches will require your team to merge code to them exclusively via merge requests, and through a code review process, which are both strongly encouraged practices.
It will also save you from a lot of potential “instability” troubles that tend to happen when people push a “small and insignificant fix that can’t break anything” directly to one of these branches. This creates a lot of frustration when things go wrong, which happens, sooner or later.
How to do it, differs from provider to provider, but here is the outline for more popular ones:
Bitbucket: https://blog.bitbucket.org/2016/12/05/protect-your-master-branch-with-merge-checks/
GitHub: https://help.github.com/articles/configuring-protected-branches/
GitLab: https://docs.gitlab.com/ee/user/project/protected_branches.html
I would suggest enabling some merge checks along, such as at least one code review and approval from another developer before merging any code to them.
Adding new code through feature branches
Considering that no code can be directly pushed to develop or master branches, it’s required that you create a new feature branch to add a new functionality to your app.
You can either do it from the command line or use integrated functionality in tools such as Sourcetree or Tower.
Source branch: develop
Naming: feature/feature-name
Example:
git checkout develop
git branch feature/my-new-feature
After you have successfully created your feature branch, feel free to push the code to it, until you are ready to get your feature reviewed as merged by another member of your team.
Merging your code
In order to merge the code via this approach, after you have finished your feature, you will first need to rebase it. This is a multi-step process.
Rebase by developer
As a developer who created a feature, you generally want to pull the latest changes from the develop branch that happened in the meantime and test whether your feature is still working.
git checkout develop
git pull
git checkout feature/your-feature-name
// This line will return a hash of commit where your branch diverged // from develop
git merge-base develop feature/your-feature-name
// {hash} is the result from the previous step
git rebase --onto develop {hash}
This will start the rebase process where changes from develop are integrated to your own feature branch, commit by commit.
Once you understand the steps that happen with rebase, there are also shorter alternatives such as:
git checkout feature/your-feature-name
git pull --rebase origin develop
You can check the complete rebase documentation here.
Why not simply use merge?
A valid point. You can, of course, merge the develop to your own feature branch and get similar results. However, there are a few key differences, why we prefer to rebase the branch over merge in this scenario.
Rebase:
Integrates changes commit by commit.
Conflicts also come in commit by commit, and it’s easy to ask your colleague what was the change to resolve the conflict more efficiently together.
-
Rebase can easily be aborted and started over, reverting all changes that you made if you are unsure if you messed up somewhere.
// After you stage files, you can continue to next commit git rebase --continue // Skips the current commit entirely git rebase --skip // Reverts all rebase changes that you did // Returns the branch to pre-rebase state git rebase --abort You have more flexibility when rebasing as you can rename incoming commits or completely skip them, if you think they are unnecessary or superseded by your changes.
It doesn’t create unnecessary merge commits if you integrate changes to your feature branches often.
If you don’t have any conflicts, it will just pass through all commits and the process will be a breeze as it is with git merge.
Merge chaos:

Merge glues all changes together leading to a huge amount of potentially conflicting files, and resolving the differences is often quite a chore. Also, it makes it much harder to understand who and for what reason changed a file if a conflict occurs.
However, regardless of your choice, the burden of testing the feature before creating a Pull Request is definitely on the developer, and shouldn’t be skipped.
Creating a pull request (merge request in some providers)
Create a pull request from your feature branch to develop (or branch from which you branched off) inside the interface of your git provider.
Bitbucket: https://confluence.atlassian.com/bitbucket/create-a-pull-request-to-merge-your-change-774243413.html
GitHub: https://help.github.com/en/articles/creating-a-pull-request
GitLab: https://docs.gitlab.com/ee/gitlab-basics/add-merge-request.html
Gitlab offers automatic rebase option inside their interface, a feature that I really like, and would be hyped to see it in BitBucket, for example.
Rebase by reviewer
This step is the main trick to have a readable and streamlined git history.
Unlike the developer rebase, which is used for resolving potential conflicts and testing your feature with the latest changes, this one is primarily for readability reasons, although it can also catch issues if they do happen.
We think it’s a critical step in the process because after you create a PR, you don’t know how long it will take for somebody to review and merge it.
More often than not, before this happens, there are new features merged to your development branch, which means:
new features might have introduced conflicts which need to be resolved
git history has changed from the moment you first rebased
If the reviewer does another rebase, it should improve the testing of the feature, minimise the potential of the feature not working after being merged, and provide you with a very clean and linear git history.
How does it look in practice
Here is a little screenshot from Sourcetree, showing features merged via this method, and mutual relationships between develop, master and other branches.
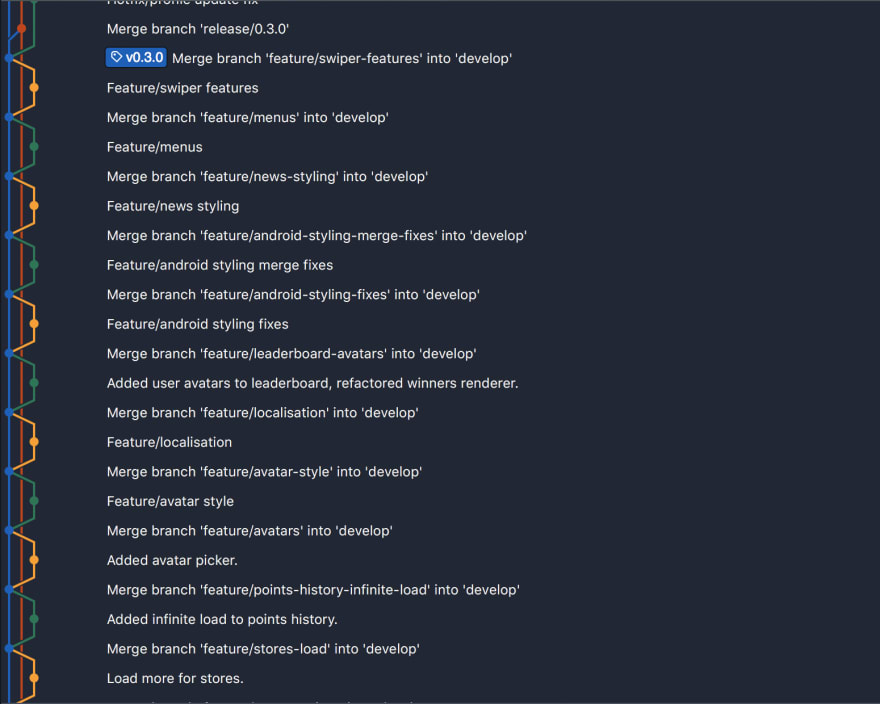
As you can see:
it’s very readable
release point with the tag from develop to master can be found quickly
you can easily see in which order your features or bug fixes were merged.
This can help a lot if you are unsure which feature broke something else in your project. It even makes using *git bisect* much easier if things come to that.
Squash or no squash
The example shown here uses squash which is given as a feature by GitLab automatically, although you can squash commits locally if required, like this:
git checkout feature/my-new-feature // If you are not on it
git rebase -i HEAD~1
This would squash your whole branch to one commit. A word of advice, discuss internally if this is what you want.
From our perspective, as long as you follow the rebase flow, squash will not significantly impact the readability of your git graph, unless your features have 100+ commits.
In that scenario, maybe you bundled too much inside a single feature :).
I prefer squashing commits in a branch before doing a PR because it forces you to go for a new bugfix/ or hotfix/ branch if you messed something up. Also, regardless of whether your developers do atomic commits or huge beasts of commits, it will not matter.
However, it’s not mandatory to squash all to one single commit. If it’s a bigger feature, you can manually squash your branch to a few important commits via interactive rebase.
git checkout feature/your-feature-name
git merge-base develop feature/your-feature-name // returns {hash}
git rebase -i {hash}
You will get a screen like this:
pick be8606b Added localisation package and settings
pick 48e6aec Fixed an issue with payload not being propagated
squash 6085ce3 Added connected intl
squash 60ec657 Fixed connected intl
squash ba09d22 Modified tasks from package.json
pick 0bea497 Build android
pick 52c67b9 Updated packages
pick 21aa18c rm package lock
Simply change pick to squash to merge a commit with the commit that preceded it.
This is usually used to squash commit duplicates or commits with stupid names such as removed console.log in order to maintain a git history that is relevant and informative.
Not convinced that this is a way to go?
If you haven’t used git in this fashion it’s very understandable. At least try it out, and try to make an opinion of it after you use it for a few days or a single project.
It did allow us to improve our git usage at PROTOTYP, and to achieve better git readability with far fewer conflicts. And when they do happen, they are resolved quickly, allowing us to be more efficient and focus on features, and not pulling our hair out.
The process of switching to the flow on all projects was not easy and took some time. After a while though, everybody is satisfied with the results that it has brought to our team.
Here are a few final things about the process.
A few words about Git rebase
Oh boy. Not rebase, right?
For us, git rebase is one of the most powerful features that comes with git. Think of it as a swiss-tool for managing your git history.
However, opinions for this functionality are often highly opinionated and this can lead to a few misconceptions.
Here are a few:
Don’t use rebase, it’s a destructive operation!
This has some merit. Rebase rewrites git history, and can lead to disastrous results, if not used properly!
However, a lot of things with git are potentially destructive. This doesn’t mean they shouldn’t be used, just that you need to understand how and when to use them, and how to mitigate the issues if they do happen.
Be mindful of using this approach on public repositories and open-source projects where a lot of different people are pushing code, and not everybody is using the same principle. It requires the whole team to be disciplined.
Also, if several people are working on the same feature, only rebase before the pull request or if you are completely sure everybody commited their changes. Rebase does rewrite the history of your own branch, so it could lead to a lot of force pulling and pushing on the branch then, which can create a frustration of its own.
This flow only makes the git graph nicer, it doesn’t bring in any value.
I strongly disagree with this one, for multiple reasons.
First off, you can write nice code and ugly spaghetti code, but both can be functional. However, do ask yourself which is faster to understand and refactor and less prone to issues?
The same logic applies here. Added brevity is rarely a bad thing.
Also, the whole point of enforcing rebase is to minimise issues with conflicts, as they happen to be much much easier to resolve via this approach. The nice graph is only a great side effect of the whole process.
What if using rebase messes my branch and project up?
To be honest, it’s very very hard to completely mess a project or a branch up, especially if multiple people are working on it, and have their own local versions which are ok. They can always force push the change to reset your state.
You can also mess a branch up if you use merge and commit these changes, but you haven’t resolved issues properly.
However, if you do manage to do to the unthinkable, resolving these issues is often a very easy thing to do.
Git reflog
Behold, the magic eraser pen of all the bad things that we do to our repository.
git reflog
Hitting that command will show hashes of all states in which your branch was, up to 90 days. You can simply check out or reset the branch to a state before the merge or rebase, and start over, by finding the last hash before you did any destructive operation.
Something is strange here. Sometimes I need to rebase, sometimes not. What’s the catch?
If your branch is ahead of the tip of develop, you don’t need to do it. In the following scenario, ensure that you have pulled all changes from develop, and if you are still ahead of it, just do a Pull request.
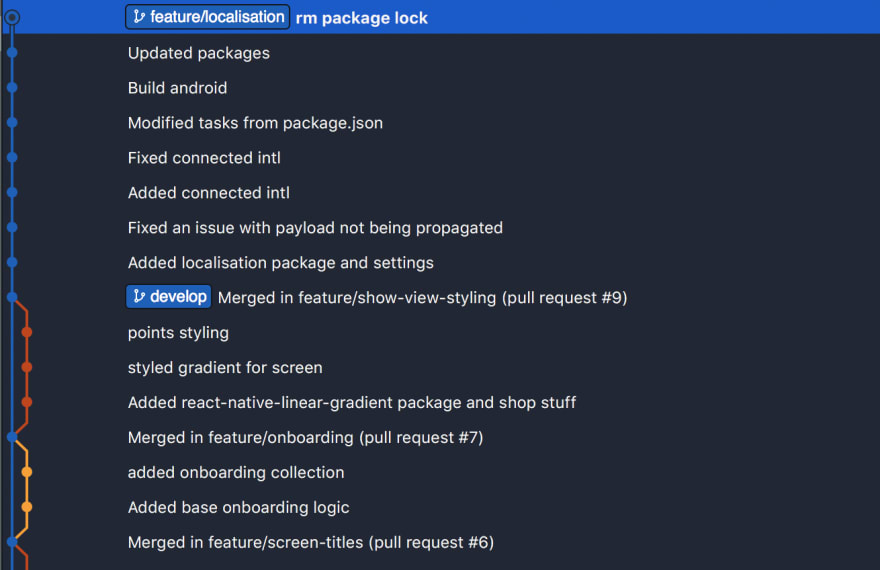
If your branch is behind the tip of develop, you will need to rebase. Observe how the feature/other-feature is not connected to the foremost point of develop, but a point behind its tip.

Closing words
We hope that this article outlined both the process and its pros and cons, based on our experiences.
If you are looking for a new process that could bring in improvements to readability and stability of your git process, making you and your team more efficient in the process, give it a shot. It could go a long way!
If you have a similar or different workflow which works for your team, we would like to hear about it and see how it compares.
Posted on September 17, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

