Demystifying Containers

Pratik Shivaraikar
Posted on June 19, 2020

Ever since Docker released it's first version back in 2013, it triggered a major shift in the way the software industry works. "Lightweight VMs" suddenly caught the attention of the world and opened opportunities of unlimited possibilities. Containers provided a way to get a grip on software. You can use Docker Containers to wrap up an application in such a way that its deployment and runtime issues— how to expose it on a network, how to manage its use of storage and memory and I/O, how to control access permissions, etc. — are handled outside of the application itself, and in a way that is consistent across all “containerized” apps.
Containers offers many other benefits besides just handy encapsulation, isolation, portability, and control. Containers are small (megabytes). They start instantly. They have their own built-in mechanisms for versioning and component reuse. They can be easily shared via the public or private repositories.
Today, Containers are an essential component of the Software Development process. Many of us use it on a day-to-day basis. In spite of all this, there is still a lot of "magic" involved for all many who want to venture into the world of Containers in general. Even till date, there is a lot of ambiguity in how exactly a container works. Today we will demystify a lot of that "magic". But before that, I believe it is necessary for us to understand the process of evolution which lead to the
The world before Containers
For many years now, enterprise software has typically been deployed either on “bare metal” (i.e. installed on an operating system that has complete control over the underlying hardware) or in a virtual machine (i.e. installed on an operating system that shares the underlying hardware with other “guest” operating systems). Naturally, installing on bare metal made the software painfully difficult to move around and difficult to update — two constraints that made it hard for IT to respond nimbly to changes in business needs.
Then virtualization came along. Virtualization platforms (also known as “hypervisors”) allowed multiple virtual machines to share a single physical system, each virtual machine emulating the behavior of an entire system, complete with its own operating system, storage, and I/O, in an isolated fashion. IT could now respond more effectively to changes in business requirements, because VMs could be cloned, copied, migrated, and spun up or down to meet demand or conserve resources.
Virtual machines also helped cut costs, because more VMs could be consolidated onto fewer physical machines. Legacy systems running older applications could be turned into VMs and physically decommissioned to save even more money.
But virtual machines still have their share of problems. Virtual machines are large (gigabytes), each one containing a full operating system. Only so many virtualized apps can be consolidated onto a single system. Provisioning a VM still takes a fair amount of time. Finally, the portability of VMs is limited. After a certain point, VMs are not able to deliver the kind of speed, agility, and savings that fast-moving businesses are demanding.
Containers
Containers work a little like VMs, but in a far more specific and granular way. They isolate a single application and its dependencies — all of the external software libraries the app requires to run — both from the underlying operating system and from other containers. All of the containerized apps share a single, common operating system, but they are compartmentalized from one another and form the system at large.
Taking an example of docker, in the image below, you can see that my host OS has a hostname of it's own. It has it's own set of processes running. When I run an Ubuntu container, we can see that it has it's own hostname and it's own set of processes:

This means that our Ubuntu container is running in an isolated environment. The PID 1 confirms this fact. Similarly we can provide a mounted storage to our container, or allocate a particular number of processes or a certain amount of RAM to run with. But what exactly is all this? What exactly is process isolation? What is a containerized environment? What do metered resources mean?
We will try to make sense of all this jargon. We will try to replicate the behavior of docker run <image> as close as possible. To make it all happen, we will be using Go for this purpose. There is no specific reason behind the selection of Go in this case. You can literally choose any language like Rust, Python, Node, etc. The only requirement is that the language should support syscalls and namespaces. The reason why I picked Go for this purpose is just a personal preference. The fact that Docker is built on Go also helps my case.
Building a container from scratch
As mentioned earlier, we will try to replicate something as close to docker as possible. Just like docker run <image> cmd args we will go for go run main.go cmd args. To start with, we will proceed with the basic snippet that most Go plugins of all the major editors has to offer:
package main
func main() {
}
Now we will add support for execution of basic commands like echo and cat
func must(err error) {
// If error exists, panic and exit
if err != nil {
panic(err)
}
}
func run() {
fmt.Printf("Running %v\n", os.Args[2:])
// Execute the commands that follow 'go run main.go run'
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
func main() {
// Make sure that the first argument after 'go run main.go' is 'run'
switch os.Args[1] {
case "run":
run()
default:
panic("I'm sorry, what?")
}
}
Let's see what that boils down to:

Now that we can run simple commands with our script, we will try running a bash shell. Since it can get confusing as we are already in a shell, we will try to run ps before and after running our script.

It is still difficult to say anything. To confirm if we have isolation like an actual container, let us try by simply changing the hostname from within our bash shell launched using our script. To modify hostname, we need to be root:
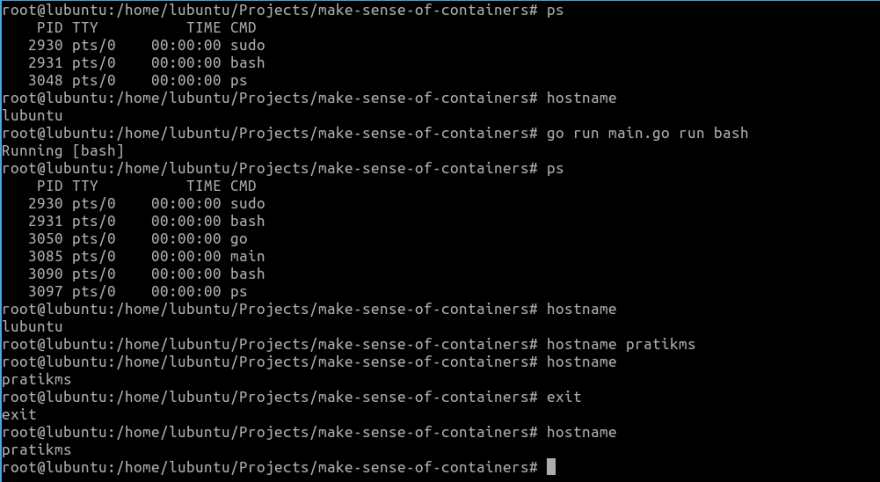
Just to summarize, we did the following in the specified order:
- Check the processes running on our host OS, by running the command
ps - Check hostname of our host OS by running the
hostnamecommand - Run our script to launch a
bashshell - Check the processes running in our launched
bashshell using thepscommand - Check the
hostnamefrom within our launchedbashshell - Try to modify the
hostnameand set it to arbitrary string - Verify if the
hostnamewas modified successfully within our launchedbashshell. It indeed did. - Exit to return to our host OS shell
- Check
hostnamein our host OS - The
hostnamechange within ourbashshell launched using our script unfortunately persisted causing thehostnameto change in our host OS as well
This means that we do not have isolation as of yet. To address this, we need the help of namespaces
Namespaces
Namespaces provide the isolation needed to run multiple containers on one machine while giving each what appears like it’s own environment. There are six namespaces. Each can be independently requested and amounts to giving a process (and its children) a view of a subset of the resources of the machine.
PID
The PID namespace gives a process and its children their own view of a subset of the processes in the system. This is in analogous to a mapping table. When a process of a PID namespace asks the kernel for a list of processes, the kernel looks in the mapping table. If the process exists in the table the mapped ID is used instead of the real ID. If it doesn’t exist in the mapping table, the kernel pretends it doesn’t exist at all. The PID namespace makes the first process created within it PID 1 (by mapping whatever its host ID is to 1), giving the appearance of an isolated process tree in the container. This is a really interesting concept.
MNT
In a way, this one is the most important. The mount namespace gives the process’s contained within it their own mount table. This means they can mount and unmount directories without affecting other namespaces including the host namespace. More importantly, in combination with the pivot_root syscall it allows a process to have its own filesystem. This is how we can have a process think it’s running on Ubuntu, CentOS, Alpine, etc — by swapping out the filesystem that the container sees.
NET
The network namespace gives the processes that use it their own network stack. In general only the main network namespace (the one that the processes that start when you start your computer use) will actually have any real physical network cards attached. But we can create virtual ethernet pairs — linked ethernet cards where one end can be placed in one network namespace and one in another creating a virtual link between the network namespaces. Kind of like having multiple IP stacks talking to each other on one host. With a bit of routing magic this allows each container to talk to the real world while isolating each to its own network stack.
UTS
The UTS namespace gives its processes their own view of the system’s hostname and domain name. After entering a UTS namespace, setting the hostname or the domain name will not affect other processes.
IPC
The IPC Namespace isolates various inter-process communication mechanisms such as message queues. This particular namespace deserves a blog post of it's own. There's so much to IPC than what I can comprehend myself. Which is why I will encourage you to check out the namespace docs for more details.
USER
The user namespace was the most recently added, and is the likely the most powerful from a security perspective. The user namespace maps the UIDs to different set of UIDs (and GIDs) on the host. This is extremely useful. Using a user namespace we can map the container's root user ID (i.e. 0) to an arbitrary and unprivileged UID on the host. This means we can let a container think it has root access without actually giving it any privileges in the root namespace. The container is free to run processes as uid 0 - which normally would be synonymous with having root permissions, but the kernel is actually mapping that UID under the covers to an unprivileged real UID belonging to the host OS.
Most container technologies place a user’s process into all of the above namespaces and initialize the namespaces to provide a standard environment. This amounts to, for example, creating an initial internet card in the isolated network namespace of the container with connectivity to a real network on the host. In our case, for satisfying our immediate requirement, we will add the UTS namespace to our script so that we can modify hostname.
func run() {
// Stuff that we previously went over
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
must(cmd.Run())
}
Running it, returns:

Awesome! We now have the ability to modify hostname in our container-like environment without letting the host environment change. But, if we observe closely, our process IDs within the container are still the same. We're able to see the processes running in our host OS even from within our container. To fix this, we need to use the PID namespace. As discussed above, the PID namespace will allow us process isolation.
func run() {
// Stuff that we previously went over
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID,
}
must(cmd.Run())
}
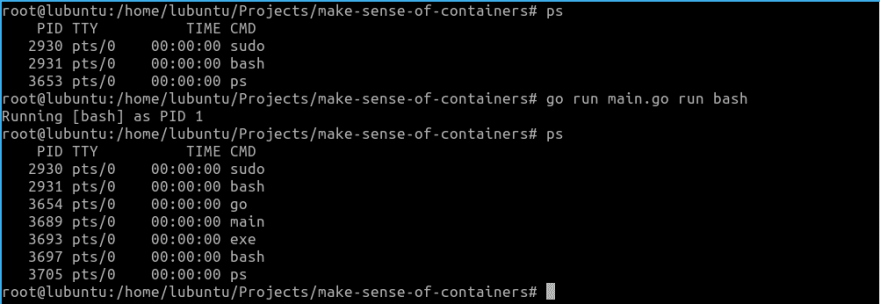
However, unlike the case of UTS namespace, simply adding the PID namespace here like this won't help. We will have to create another copy of our process so that it can be run with PID 1.
func run() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID,
}
must(cmd.Run())
}
func child() {
fmt.Printf("Running %v as PID %d\n", os.Args[2:], os.Getpid())
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("I'm sorry, what?")
}
}
What we're basically doing is that whenever we will run go run main.go run bash, our main() function will be called. As the value of os.Args[1] will be 'run' at this instance, it will call our run() function. Within run(), we are using /proc/self/exe to create a copy our current process. We are essentially creating a copy and calling it again by appending the string 'child' to it followed by the rest of the arguments that we received in run(). When we do this, our main() function will be invoked again with the difference being that the value of os.Args[1] will be 'child' this time. From there on, the rest of the script executes as we saw before.
Unfortunately, even after doing all this, the results that we get are not that different. To understand why, we need to know what exactly goes on behind the scenes when we run the ps command. It turns out that ps looks at /proc directory to find out what processes are currently running on the host. Let us observe the contents of the /proc directory from our host and also from our container.

As we can see, the contents of the /proc directory when observed from the host and even from the container are one and the same. To overcome this, we wan't the ps of our container to be looking at a /proc directory of it's own. I other words we need to provide our container it's own filesystem. This brings us to an important concept of containers: layered filesystems
Layered Filesystems
Layered Filesystems are how we can efficiently move whole machine images around. They're the reason why the ship floats and does not sinks. At a basic level, layered filesystems amount to optimizing the call to create a copy of the root filesystem for each container. There are numerous ways of doing this. Btrfs uses copy on write (COW) at the filesystem layer. Aufs uses “union mounts”. Since there are so many ways to achieve this step, we will just use something horribly simple. We’ll do a copy of the filesystem. It’s slow, but it works.
To do this, I have a copy of the Lubuntu filesystem copied in the path specified below. The same can be seen in the screenshot provided below as I have touched HOST_FS and CONTAINER_FS as two files within the root of the host and within the copy of our Lubuntu FS.

We will now have to let our container know about this filesystem and ask it to change it's root to this copied filesystem. We will also have to ask the container to change it's directory to / once it's launched.
func child() {
// Stuff that we previously went over
must(syscall.Chroot("/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs"))
must(syscall.Chdir("/"))
must(cmd.Run())
}
Running this we get our intended FS. We can confirm it as we can see CONTAINER_FS, the file that we created in our container:
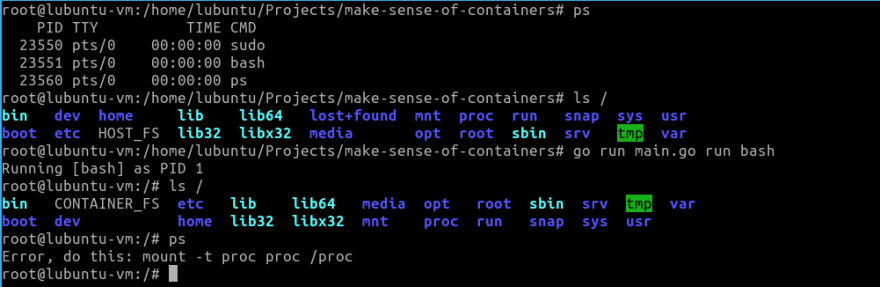
However, once again, in-spite of all of these efforts, ps still remains a problem.
This is because while we provided a new filesystem for our container using chroot, we forgot that /proc, in itself, is a special type of virtual filesystem. /proc is sometimes referred to as a process information pseudo-file system. It doesn't contain 'real' files but runtime system information like system memory, devices mounted, hardware configuration, etc. For this reason it can be regarded as a control and information center for the kernel. In fact, quite a lot of system utilities are simply calls to files in this directory. For example, lsmod is the same as cat /proc/modules. By altering files located in this directory you can even read/change kernel parameters like sysctl while the system is still running.
Hence, we need to mount /proc for our ps command to be able to work.
func child() {
// Stuff that we previously went over
must(syscall.Chroot("/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs"))
must(syscall.Chdir("/"))
// Parameters to this syscall.Mount() are:
// source FS, target FS, type of the FS, flags and data to be written in the FS
must(syscall.Mount("proc", "proc", "proc", 0, ""))
must(cmd.Run())
// Very important to unmount in the end before exiting
must(syscall.Unmount("/proc", 0))
}
You can think of syscall.Mount() and syscall.Unmount() as the functions that are called when you plug-in and safely remove a pen-drive. In the same analogy, we mount and unmount our /proc filesystem in our container.
Now if we run ps from our container:

There! After all these efforts, we finally have PID 1! We have finally achieved process isolation. We can see our /proc filesystem has been mounted by doing ls /proc which lists the current process information of our container.
One small thing that we need to check is to see the mount points of proc. We will do that by first running mount | grep proc from our host OS. We will then launch our container and again run the same command. With our container still running, we will once again run mount | grep proc to check the mount points of proc with our container running.

As we can see, if we run mount | grep proc from our host OS with our container running, the host OS can see where proc is mounted in our container. This should not be the case. Ideally, our containers should be as transparent to the host OS as possible. To fix this, all we need to do is to add MNT namespace to our script:
func run() {
// Stuff we previously went over
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
Now if we observe the mount points from our host OS with the container running, we get:

There! With this, now we can say that we have a truly isolated environment. Just so that there is a better distinction between our host and our containerized environments, we can assign our container some arbitrary hostname
func child() {
// Stuff that we previously went over
must(syscall.Sethostname([]byte("container")))
must(syscall.Chroot("/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs"))
must(syscall.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
must(cmd.Run())
must(syscall.Unmount("/proc", 0))
}
Running it gives:

This gives us a fully running, fully functioning container!
There is, however, one more important concept which we haven't yet covered. While Namespaces provide isolation, and Layered Filesystems provide us with a root filesystem for our container, we need Cgroups for resource sharing.
Cgroups
Cgroups, also known as Control Groups, previously known as Process Groups is perhaps one of the most prominent contribution of Google to the software world. Fundamentally, cgroups collect a set of process or task ids together and apply limits to them. Where namespaces isolate a process, cgroups enforce resource sharing between processes.
Just like /proc, Cgroups too, are exposed by the kernel as a special file system that we can mount. We add a process or thread to a cgroup by simply adding process ids to a tasks file, and then read and configure various values by essentially editing files in that directory.
func cg() {
// Location of the Cgroups filesystem
cgroups := "/sys/fs/cgroup/"
pids := filepath.Join(cgroups, "pids")
// Creating a directory named 'pratikms' inside '/sys/fs/cgroup/pids'
// We will use this directory to configure various parameters for resource sharing by our container
err := os.Mkdir(filepath.Join(pids, "pratikms"), 0755)
if err != nil && !os.IsExist(err) {
panic(err)
}
// Allow a maximum of 20 processes to be run in our container
must(ioutil.WriteFile(filepath.Join(pids, "pratikms/pids.max"), []byte("20"), 0700))
// Remove the new cgroup after container exits
must(ioutil.WriteFile(filepath.Join(pids, "pratikms/notify_on_release"), []byte("1"), 0700))
// Add our current PID to cgroup processes
must(ioutil.WriteFile(filepath.Join(pids, "pratikms/cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func child() {
fmt.Printf("Running %v as PID %d\n", os.Args[2:], os.Getpid())
// Invoke cgroups
cg()
cmd := exec.Command(os.Args[2], os.Args[3:]...)
// Stuff that we previously went over
must(syscall.Unmount("/proc", 0))
}
On running our container, we can see the directory 'pratikms' created inside /sys/fs/cgroup from our host. It has all the necessary files in it control resource sharing within our container.

When we cat pids.max from our host, we can see that our container is limited to running a maximum of 20 processes at a time. If we cat pids.current, we can see the number of processes currently running in our container. Now, we need to test the resource limitation that we applied on our container.
:() { : | : & }; :
No, this is not a typo. Neither did you read it wrong. It's essentially a fork bomb. A fork bomb is a denial-of-service attack wherein a process continuously replicates itself to deplete available system resources, slowing down or crashing the system due to resource starvation. To make more sense of it, you can literally replace the : in it with anything. For example, :() { : | : & }; : can also be written as forkBomb() { forkBomb | forkBomb &}; forkBomb. It means that we're declaring a function forkBomb() who's body recursively calls itself with forkBomb | forkBomb and runs it in background using &. Finally, we call it using forkBomb. While this works, a fork bomb is conventionally written as :() { : | : & }; :, and that is what we will proceed with:

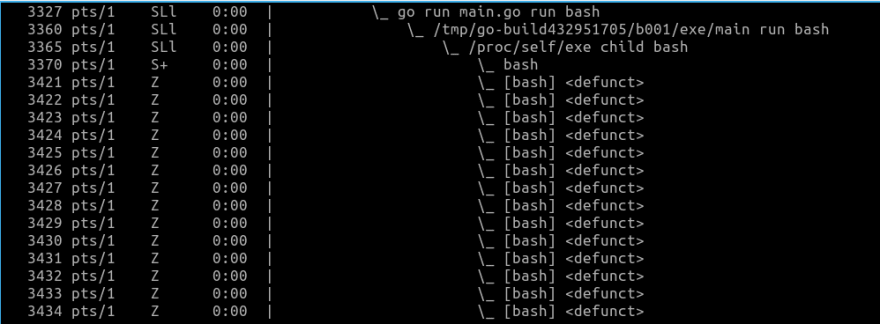
As we can see, our the current number of processes running within our container were 6. After we triggered the fork bomb, the current number of running processes increased to 20 and remained stable there. We can confirm the forks by observing the output of ps fax:
Putting it all together
So here it is, a super super simple container, in less than 100 lines of code. Obviously this is intentionally simple. If you use it in production, you are crazy and, more importantly, on your own. But I think seeing something simple and hacky gives us a really useful picture of what’s going on.
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strconv"
"syscall"
)
func must(err error) {
if err != nil {
panic(err)
}
}
func cg() {
cgroups := "/sys/fs/cgroup/"
pids := filepath.Join(cgroups, "pids")
err := os.Mkdir(filepath.Join(pids, "pratikms"), 0755)
if err != nil && !os.IsExist(err) {
panic(err)
}
must(ioutil.WriteFile(filepath.Join(pids, "pratikms/pids.max"), []byte("20"), 0700))
// Remove the new cgroup after container exits
must(ioutil.WriteFile(filepath.Join(pids, "pratikms/notify_on_release"), []byte("1"), 0700))
must(ioutil.WriteFile(filepath.Join(pids, "pratikms/cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func child() {
fmt.Printf("Running %v as PID %d\n", os.Args[2:], os.Getpid())
cg()
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(syscall.Sethostname([]byte("container")))
must(syscall.Chroot("/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs"))
must(syscall.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
must(cmd.Run())
must(syscall.Unmount("/proc", 0))
}
func run() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("I'm sorry, what?")
}
}
Again, as stated before, this is in no way a production-ready code. I do have some hard-coded values in it. For example value of the path to the filesystem, and also the hostname of the container. If you wish to play around with the code you can get it from my GitHub repo. But, at the same time, I do believe this is a wonderful exercise to understand what goes on behind the scenes when we run that docker run <image> command in our terminal. It introduces us to some of the important OS concepts that Containers, in general leverage. Like Namespaces, Layered Filesystems, Cgroups, etc. Containers are important – and its prevalence in the job market is incredible. With Cloud, Docker and Kubernetes becoming more linked every day, that demand will only grow. Going forward, it is only imperative to understand the inner workings of a Container. And this was my small attempt in doing the same.
This post first appeared at https://blog.pratikms.com
Posted on June 19, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related