Understanding Standard Input and Output

Preslav Mihaylov
Posted on December 19, 2017

This article is part of the sequence The Basics You Won't Learn in the Basics aimed at eager people striving to gain a deeper understanding of programming and computer science.
Somewhere in the first lectures of a programming basics course, we are shown how to take input and show output on the terminal. That's called standard input/output or just Standard IO for short.
So, in C# we have Console.WriteLine and Console.ReadLine.
In C++, we have cin and cout.
All these things are associated with the topic of Standard IO. And what they tell us is that the standard input is the keyboard and the standard output is the screen. And for the most part, that is the case.
But what we don't get told is that the Standard IO can be changed. There is a way to accept input from a file and redirect output to another file. No, I'm not talking about writing code to read/write files. I am talking about using the Standard IO for the job, via the terminal.
And how can this be useful?
Remember all those times where you have to do a console application and test it afterwards against several examples. The normal workflow was to write some code, and then manually input the examples with the keyboard. Then you visually compare the output to the given expected output. A more optimized approach might be to write the input to a file once and copy-paste it all the time afterwards.
Sure, that will save you time. But there is a more general, automated approach to this. Let's check it out.
How does a program know its inputs and outputs?
We will start by a little bit of operating system theory.
Whenever you have an open file, the operating system stores a number somewhere, which acts as an index you can use to read that file. In Unix based operating systems (All Linux distributions in that number), that is called a file descriptor. In Windows, it is called a handle, but is basically the same thing. In this article, we will refer to the Unix terminology - file descriptors.
So when you open a file in your program, the operating system gives you a file descriptor to use in order to access it.
But there are 3 file descriptors which every process always have. That is file descriptor 0 - the standard input, 1 - the standard output and 2 - the standard error. These reference another file or process which is used when you invoke Console.WriteLine or Console.ReadLine.
Let's make a quick demo in the Linux operating system I am using - Ubuntu.
I have compiled a simple program called parrot, which receives input and prints the same output all the time until it receives the line "end":

So, I will let it run and open another terminal in the meantime. In it, I will list some processes and find my program.

The TTY column of that output shows which is the terminal that is running the process. See how it shows /dev/pts/19 for the parrot process? Remember that name. Also, check out the process id (PID).
Now, I will go to this magic Linux directory - /proc. It contains all the data about currently running processes in files (Everything in Linux is a file, including processes, but that's another topic). If I open the directory 23764 (the process id!), I will see the data of my parrot process. I open the directory fd, which holds info about all the file descriptors of that process and show you its contents:

As you can see, we have the 3 file descriptors I told you about and they point to /dev/pts/19, which is the terminal that is running the program.
So, what you see when you run the parrot program is some strings being printed out in the terminal window. But from the operating system's viewpoint, there is a program called parrot, which sends its Standard IO to the device /dev/pts/19 which happens to be our opened terminal!
Manipulating the IO
Well, now that you know what actually happens when you write Console.ReadLine, it's time to show you how to change that behavior. How can you alter those file descriptors not to use the /dev/pts/XX process, but something else.
Turns out, there are simple routines you can use in the terminal with which you can easily change the Standard IO. One is using the '>' command. So, I am in the parrot program's folder and this time I will run it using the following command:
./parrot > output.txt
This time, when I write messages, I don't see any output on the screen. All you see is the input I type in.

But if I open the file output.txt, you can see that all the output I expected is written in it!
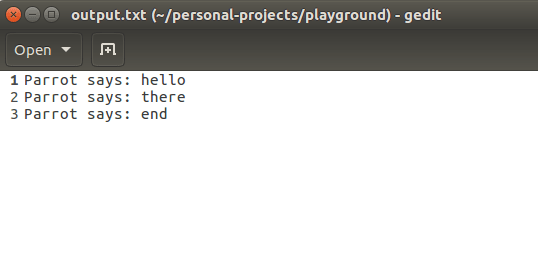
Now, doing all the routines I described in the demo from the previous section, I go to the proc directory and check out the file descriptors of my process. It turns out that file descriptor 1 now points to the file I just mentioned!

That is how you can override the default standard output and this time, Console.ReadLine writes not to the screen, but to a file instead. But what about standard input?
Similarly, there is a '<' command which accepts the standard input from a file.
I create a file called input.txt and add some content. Next I execute:
./parrot < input.txt

Before going on, though, I modify the parrot program not to exit after it has finished reading the input as I want to inspect its process data. Going through all the stuff from the first demo, I observe the following file descriptors:

As you might guess, you can override both the standard input and output by doing something like:
./parrot < input.txt > output.txt
Oh and by the way, I mentioned there is a thing called standard error as well? That is the output you get for any error information a program outputs. For example, the output from an exception in C# goes to the standard error stream. You can redirect that using the '2>' command.
What about processes?
Until now, I have shown you how to redirect the Standard IO from/to files. But a very interesting endeavor is to implement communication between two processes using similar techniques. This can be done using pipes, which are indicated by the '|' symbol in the terminal.
What a pipe does is to redirect the standard output from process A to the standard input of process B. In a more informal language, the output of one process goes as input to another.

Let's say I want a list of the first 3 files sorted in alphabetical order from some directory. Well, there are programs in Linux to do each of these tasks in isolation.
ls -1: lists the files from a given directory in rows
sort - sorts all input rows in alphabetical order
tail -n 3: takes the first three entries from all input rows
Using pipes, you can combine these together and you get:
ls -1 | sort | head -n 3
The result is:
"ls -1" outputs all the files in rows. "sort" sorts them in alphabetical order and "head -n 3" takes only the first three rows.

And that's the beauty of working with the terminal. When using GUI programs like Excel, you expect them to be able to do everything - edit, search, sort, filter, etc. But when you work with the terminal, you expect programs to be doing one thing. And it is the combination of different small programs that grants you tremendous power.
A simple test platform
Now that we know the capabilities, we can make a useful system to help us in our development. Remember how I mentioned all that manual testing we were doing while writing our console applications?
Instead of manually writing the input all the time, we can write it in some test file and use it as standard input for our program. Next, we can redirect the standard output to a file, which we compare to a file with the expected output. So, we will do this with a simple shell script, which you simply run (by typing bash test.sh) and it outputs whether all the tests passed or failed:
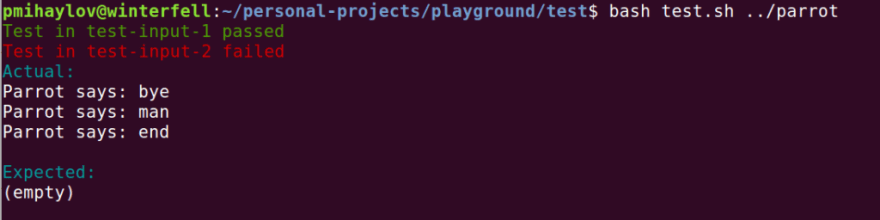
Don't be intimidated if you haven't encountered a shell script before. Its intent is to automate you typing in all the commands in it on an actual terminal all the time. So what you can do, instead, is to run the script and it does all the work for you. Maybe I will make an article later on about creating shell scripts.
What I do in the script is traverse a list of test files and I use them as standard input for the provided program. Then I output the standard output to another file and compare it against an expected file. For details about the test platform itself, check it out here:
Note that this will work for Linux, as it is a bash script, but there are equivalent Windows commands and scripts you can make. They are called bat files there. Maybe you can try implementing such a platform on Windows as well. If not, you can install MinGW, which lets you emulate Linux commands/scripts on a Windows machine.
Conclusion
So, we have passed the long road from reading IO from the keyboard and the screen to redirecting it towards files and other processes. That is the power of the Standard Input/Output. We used it to create a simple, but smart, test platform for checking your programs against some input and expected output.
Try these things now. Compile your source files, open the location of the output "exe" or whatever you might have, and try altering its standard IO with some of the commands I showed you. They work for Windows as well, by the way.
Once you have grasped this concept, you will be one step closer to being more efficient and knowledgeable as a developer.
Posted on December 19, 2017
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related