High Quality Data is All you Need!

Abel Peter
Posted on January 2, 2024
There are numerous models available from commercial to open source all trained on a huge corpus of data that is available online. These models are referred to us "base models" in the LLM community lingo, this is because they are not trained to do a specific task, for this, they need to be fine tuned to make them viable for deployment on a production or a business setting so as to provide value to clients of a business. This "finetuning" process is ultimately where the business value resides and as we shall see high quality data is what you need to have an edge which is the subject of this article.
Data integrity.
Data integrity plays a significant role in addressing several aspects related to the evaluation and performance of Large Language Models (LLMs). Today we will focus on 3 main problems in most tabular data I have worked with from various businesses that process huge amounts of data. The first one:
1. Mixed data types.
A mix of data types can significantly impact machine learning models, as it introduces complexity in feature engineering, preprocessing, and model interpretation. Some of the mixed data usually include; numerical data mixed with text data, date and time data mixed with text data. This arises due to utilization of different ETL processes and thus a data cleaning process is leveraged to jump this hurdle, this process can be streamlined using the deepchecks library as shown below.
First install the deepchecks library.
pip install deepchecks
import dependencies and dataset.
# Import dependencies
import numpy as np
import pandas as pd
from deepchecks.tabular.datasets.classification import adult
# Prepare functions to insert mixed data types
def insert_new_values_types(col: pd.Series, ratio_to_replace: float, values_list):
col = col.to_numpy().astype(object)
indices_to_replace = np.random.choice(range(len(col)), int(len(col) * ratio_to_replace), replace=False)
new_values = np.random.choice(values_list, len(indices_to_replace))
col[indices_to_replace] = new_values
return col
def insert_string_types(col: pd.Series, ratio_to_replace):
return insert_new_values_types(col, ratio_to_replace, ['a', 'b', 'c'])
def insert_numeric_string_types(col: pd.Series, ratio_to_replace):
return insert_new_values_types(col, ratio_to_replace, ['1.0', '1', '10394.33'])
def insert_number_types(col: pd.Series, ratio_to_replace):
return insert_new_values_types(col, ratio_to_replace, [66, 99.9])
# Load dataset and insert some data type mixing
adult_df, _ = adult.load_data(as_train_test=True, data_format='Dataframe')
adult_df['workclass'] = insert_numeric_string_types(adult_df['workclass'], ratio_to_replace=0.01)
adult_df['education'] = insert_number_types(adult_df['education'], ratio_to_replace=0.1)
adult_df['age'] = insert_string_types(adult_df['age'], ratio_to_replace=0.5)
Running a check.
from deepchecks.tabular import Dataset
from deepchecks.tabular.checks import MixedDataTypes
adult_dataset = Dataset(adult_df, cat_features=['workclass', 'education'])
check = MixedDataTypes()
result = check.run(adult_dataset)
result
Output.

The output above shows the percentages of mixed data types in the columns provided.
2. Null data(NaN).
Null data, also known as missing data, refers to the absence of values in certain observations or variables within a dataset. Missing data can occur for various reasons, including data collection errors, non-response in surveys, or system failures.
You will mostly encounter this in clickstream data; which is data that captures user interactions on websites or applications, providing insights into user behavior and customer support logs; such as chat logs and support ticket histories. To check for this using Deepchecks, you can power up a colab notebook and follow the guide steps below.
Note: you might need to run {pip install deepchecks} if you are using a new notebook.
Below are the dependencies you will need.
import numpy as np
import pandas as pd
from deepchecks.tabular.checks.data_integrity import PercentOfNulls
Read the csv data to a dataframe.
The data is a sample of click stream data that can downloaded from here.
df = pd.read_csv('/content/events-export-2795217-1678446726055.csv')
Running a check.
result = PercentOfNulls().run(df)
result.show()
output

The output gives a very clear visual presentation of which columns have null values and by what percentage amount, so as to allow an engineer decide on the course of action.
Define a Condition.
A condition allows us to validate the models and data quality, and let us know if some threshold is met. This then informs the course of action.
check = PercentOfNulls().add_condition_percent_of_nulls_not_greater_than()
result = check.run(df)
result.show()
Output.

3. Data duplicates.
Data duplicates refer to identical or nearly identical instances or observations within a dataset. In other words, duplicate data occurs when two or more records in a dataset share the same values across all or a significant portion of their features. These duplicates can manifest in various forms depending on the context of the data, and they may arise for different reasons.
It occasionally leads to overfitting, where the model learns to perform well on the training set but fails to generalize to new, unseen data. The model may memorize the duplicated patterns instead of learning the underlying patterns of the data.
Here is a way to handle data duplicates using the deepchecks library.
Import dependencies.
from datetime import datetime
import pandas as pd
from deepchecks.tabular.datasets.classification.phishing import load_data
Loading the data.
phishing_dataset = load_data(as_train_test=False, data_format='DataFrame')
phishing_dataset
Output.
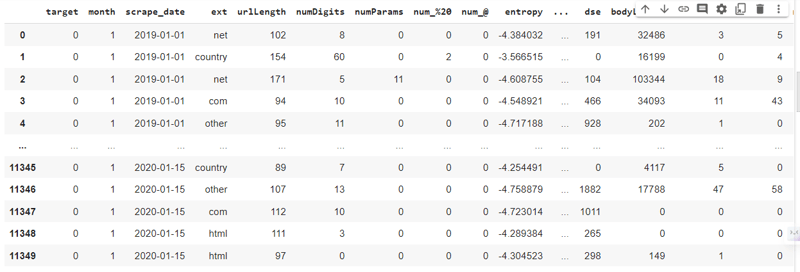
Run the Check.
from deepchecks.tabular.checks import DataDuplicates
DataDuplicates().run(phishing_dataset)
DataDuplicates(columns=["entropy", "numParams"]).run(phishing_dataset)
Output.
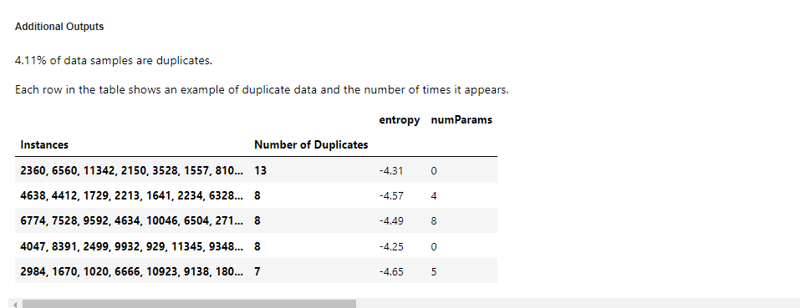
This output indicates the percentage of 4.11% of duplicate samples, in a small dataset, this might not much but working with millions of entries, this duplicates could result in a significant overfitting problem.
Define a condition.
A condition is deepchecks' way to validate model and data quality, and let you know if anything goes wrong.
check = DataDuplicates()
check.add_condition_ratio_less_or_equal(0)
result = check.run(phishing_dataset)
result.show(show_additional_outputs=False)
Output.

Summary.
In the realm of machine learning, the quality of training data is paramount to the success and reliability of models. The commitment to data integrity not only ensures the reliability of machine learning models but also contributes to the broader goal of responsible and impactful AI development.
Good learning!
Posted on January 2, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.