
Paceaux
Posted on February 29, 2024

A few years back I ran into a difficult situation on a project: I needed to find out where a particular CSS selector was used.
I had a static version of the site, and so I did what any fool might do and I tried searching for it in my IDE. I had two problems though:
Writing a RegEx to essentially parse HTML is substantially more
difficultdangerous than you might expect.The actual live version of the site was managed by a CMS (content management system), and it would be much more difficult to know where that selector might end up
So after almost a day of failing to produce a good-enough RegEx, I got an idea: What if I just scanned the live site for that selector?
In about the same amount of hours it took for me to write a RegEx that didn’t always work, I was able to produce a node.js-based script that could scan a live site for the selector.
So with that, I got the bright idea to make it a proper NPM package that could run on the command line. And now I should introduce you.
Introducing SelectorHound
SelectorHound is on NPM and it’s already at 2.2!
It’s a Command Line Interface (CLI) that offers a pretty robust set of options:
- Give it a single selector or a CSS file
- Give it a URL to a sitemap or tell it to crawl your site
- Ask for a lot of details about HTML elements that match the selector, or a screenshot
- Tell it to treat pages like they’re a SPA (Single Page Application) or like static HTML
What it's good for
- Do you have CSS on your site that you’d like to delete, but you’re uncertain if it’s used anywhere?
- Are you looking for instances where one element may be next to another?
- Would you like to know if your stylesheet has rulesets that could be deleted?
- Has malware infected your CMS and started adding weird links, but you don't know what pages?
- Do you have calls to action that might be missing data attributes?
All of these are real world use-cases that I’ve used SelectorHound for.
Try it out
First, Install it
npm install -g selector-hound
For, for more speed (requires installing bun first):
bun install -g selector-hound
Then Run it
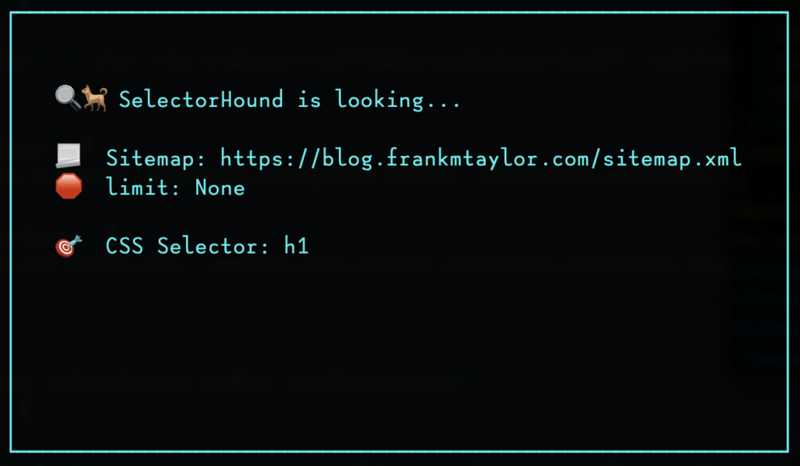
SelectorHound -u https://blog.frankmtaylor.com/sitemap.xml -s "h1"
Then Look at what you got
First it'll tell you what it's doing as it gets started
Whether it's crawling or using your sitemap, it will export the URLs to a JSON file.
This means you can customize the pages it scans.
And it’ll rely on that JSON file for every scan unless you pass -X to force it to generate a new sitemap file.
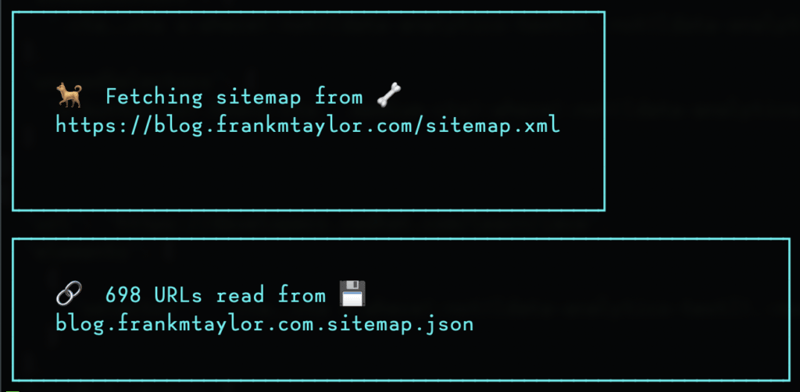
BTW it's way easier to represent fetching with emoji than "I read these URLs from a file on your computer"
Then it’ll tell you when it’s finished and give you a nice summary of what it found.
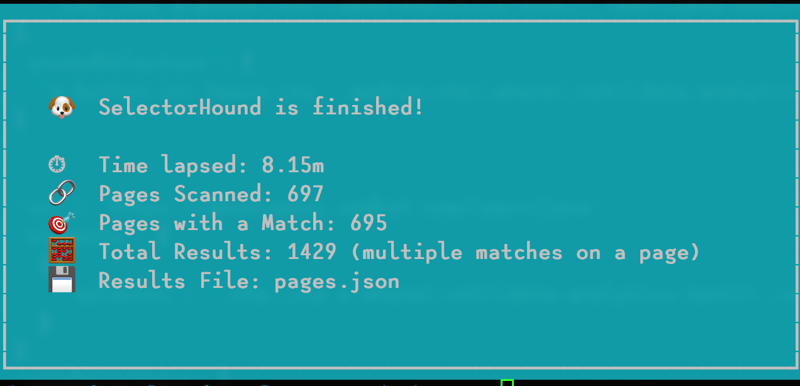
You can modify the output file name with the -o flag. Your chosen name will be prepended to pages.json.
Don't forget to check the log
The log file will look a lot like what you see in the CLI. One big difference though is that any errors that occur will show up here. It'll also tell you in the log if a page didn't have any matches.
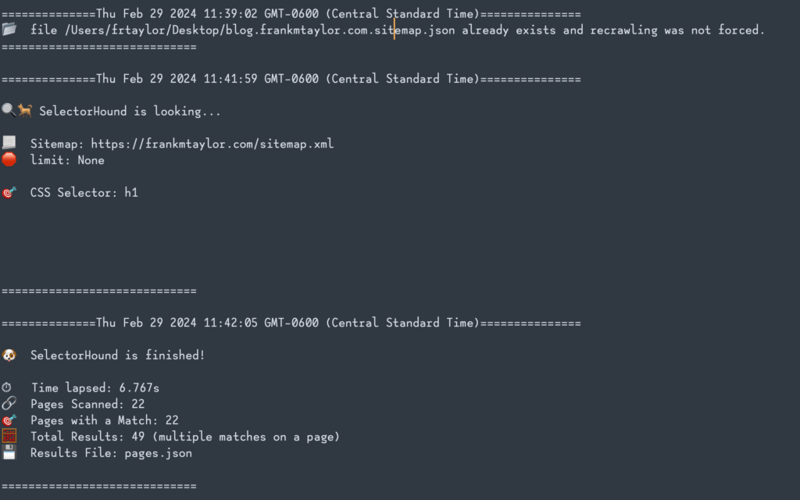
And then check out the results
The results will be in a JSON format.
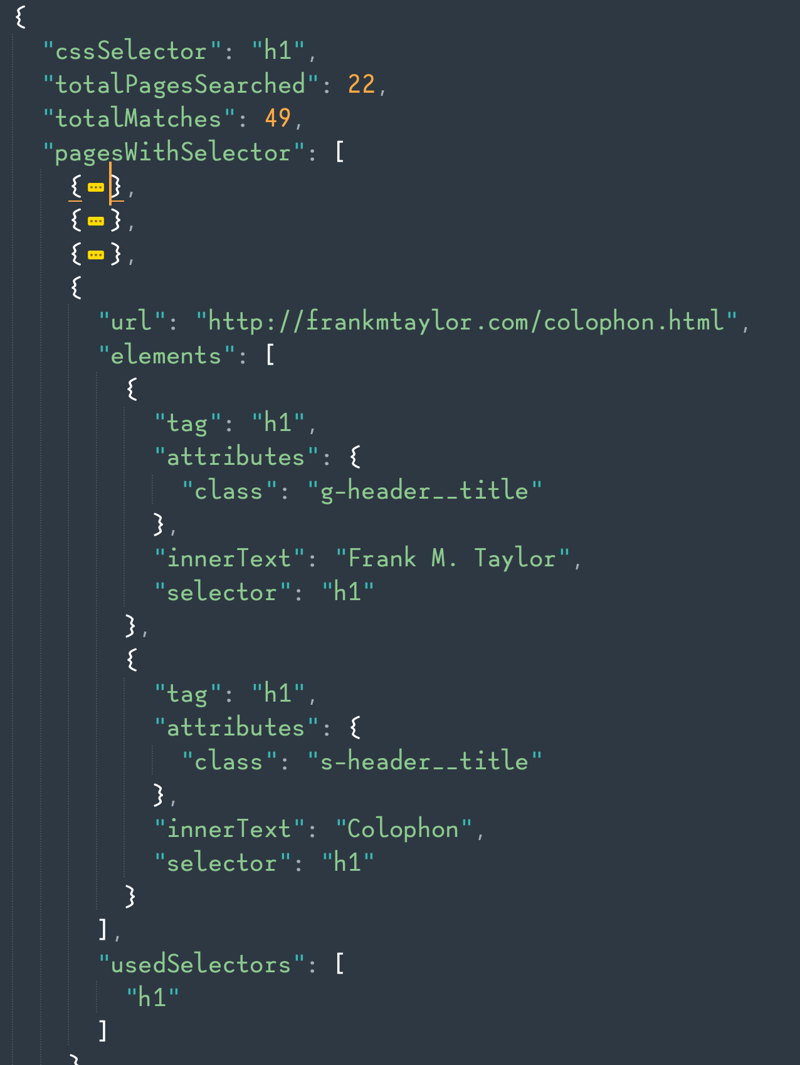
The -e flag can give you details about the elements in case you want to know exactly where on the page your selector is found.
The output can be pretty robust because it’ll give you results for every page that it found. I am working on a reporting feature that can summarize the results if you don’t want to wade through what could be thousands of lines of JSON.
Is it Performant?
It’s faster than writing a RegEx to scan your codebase, that’s for sure.
I’ve done a some testing and found that, if you were looking for a single HTML element, it might take on average .52s per page. If you install with Bun, you will get maybe a .1s gain.
We use it a lot at work and I can tell you that one site which has about 5600 pages, SelectorHound takes about 3 hours to find one very complex CSS selector. If you do the math that's 31 pages a minute or ... .52 seconds a page.
Whether you think that's fast or slow is going to be relative to how much energy you're willing to spend blindly clicking through a site trying to find those 12 buttons missing data attributes.
Activating Puppeteer to either take screenshots or just expect it to be a SPA will slow things down significantly, so use that with caution. I mentioned that you can take screen shots with -c, right?
Did I also mention you can use -f to pass in a whole CSS file? Because you can. And if you do, expect that to take a little longer, too.
Where can you see the code?
You can view the package on NPM and you can look at the code on Github
Feature requests and pull requests welcome.
Posted on February 29, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related