Semantic Search with Elasticsearch on Large Documents

Lövei Róbert
Posted on November 15, 2023
Semantic search is a technique used by search engines to improve the accuracy of search results by understanding the intent and contextual meaning of the words used in a search query. Traditional search engines primarily rely on keyword matching to retrieve results. However, semantic search goes beyond matching keywords and takes into account the relationship between words, the context of the search, and the user's intent to deliver more relevant results. What if we combine both with a search engine?
Elasticsearch introduced the dense_vector field type in late 2020, which stores dense vectors of float values. So how does this support semantic search?
In the context of semantic search and natural language processing, vectors are mathematical representations of words or phrases in a high-dimensional space. These representations capture the semantic meaning of words or phrases based on their context and relationships with other words in a given dataset. Vectors are part of a mathematical technique known as word embeddings or word vectors.

1. Prepare Documents to Transformation into Embeddings
There are several ways of transforming our documents into embeddings. One is to use an external API, like OpenAI’s, or Microsoft Azure’s embedding endpoints. Another way is to use our local computer, or an on-premises server with a Hugging Face model, like bge-large-en.
Either way, we will face a document size limitation in the transformation step. In the case of OpenAI’s text-embedding-ada-002 model, the limit is 8192 tokens, which is roughly 5000 words. In the case of Hugging Face models, the token size limitation in most cases is 512, which is around 312 words. What can we do to overcome these limits?
First, we need to slice our documents to make them fit into token limits with the right tool. At One Beyond, we use CharacterTextSplitter class from Python’s langchain library.
text = "..." # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = ".",
chunk_size = 512,
chunk_overlap = 256
)
docs = text_splitter.create_documents([text])
In this example our separator is a “.” punctuation sign, which means we split at sentence endings. We allow 512 characters in one chunk, but with 256 characters overlap from the last and next chunks. We need the overlap to keep the context of a specific chunk. If you want to read about other chunking solutions this is the right article for you.
2. Transform a Single Text into Multiple Embeddings
At this step we have our original documents and the chunked versions of them, which fit into the limitations of our selected model.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-large-en-v1.5')
text = "..." # your text
document_chunks = text_splitter.create_documents([text])
texts = [doc.page_content for doc in document_chunks]
texts = [text.replace("\n", ". ") for text in texts]
embeddings = model.encode(texts)
In this example we use SentenceTransformer class to load model BGE Large and use it to tokenize our chunks.
The other options are to use either OpenAI, or Azure AI API to embed them. Here is an example with Azure:
import openai
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("AZURE_AI_KEY")
openai.api_base = "https://ob-openai-semantic-search-eastus.openai.azure.com/"
openai.api_type = 'azure'
openai.api_version = '2023-05-15'
your_text = "..." # your text
document_chunks = text_splitter.create_documents([your_text])
texts = [doc.page_content for doc in document_chunks]
texts = [text.replace("\n", ". ") for text in texts]
embeddings = []
for text in texts:
response = openai.Embedding.create(engine="text-embedding-ada-002", input=text)
embeddings.append(response.data[0].embedding)
We can configure openai python lib to user either OpenAI, or Azure endpoints.
3. Create Elasticsearch schema and insert documents
Since we have our original long text and multiple chunks and embeddings associated with it, we need to create parent child relationship between them in our Elasticsearch index. There is an example payload below how you can create such an index.
{
"mappings": {
"properties": {
"id": {"type": "keyword", "store": "true"},
"text": {"type": "text", "store": "true"},
"embedding_bge_large_en_v1_5": {
"type": "dense_vector",
"dims": 512,
"index": True,
"similarity": "cosine",
},
"vectors": {
"type": "join",
"relations": {
"chunk_embedding": "embedding_bge_large_en_v1_5",
},
}
}
}
}
As we can see, we define the document property embedding_bge_large_en_v1_5 as dense_vector with 512 lengths. We define cosine as similarity type. Cosine similarity is a method to determine distance between vectors. If you want to know more about it this is a useful article. Below is an example of insert document payload into this index.
{
"id": f"{text['id']}_{vector_index}",
"embedding_bge_large_en_v1_5": vector,
"vectors": {
"name": "embedding_bge_large_en_v1_5",
"parent": text['id']
},
"routing": 1
}
4. Search in the index
At this point we have our index populated with data. It is time to run semantic search on it.
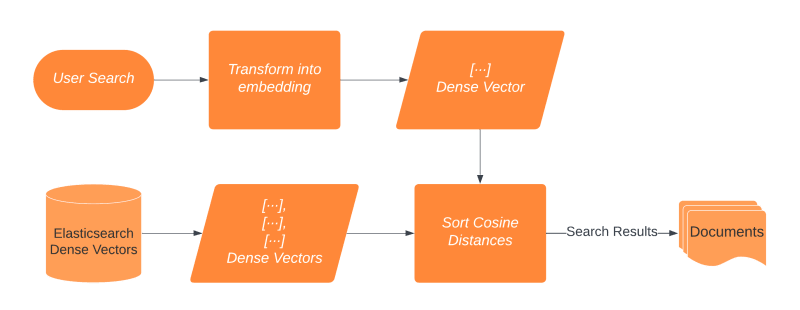
As we can see above, we transform our user search into an embedding in similar way to the one I detailed it in Point 2, except that we will have only 1 embedding without chunking this time.
We compare this embedding with cosine similarity to the chunk embeddings we store in Elasticsearch. This is a built-in feature, so we can do it with a simple query as detailed below.
{
"size": 10,
"_source": ["text"],
"query": {
"has_child": {
"score_mode": "max",
"type": "embedding_bge_large_en_v1_5",
"query": {
"function_score": {
"script_score": {
"script": {
"source": "(cosineSimilarity(params.vector,'embedding_bge_large_en_v1_5') + 1)",
"params": {"vector": query_vector.tolist()},
}
}
}
}
}
}
}
Earlier, we defined cosine as similarity on the child field’s similarity type, so we don’t need to tell Elastic in the query to use it. In the example, query_vector is the search embed passed in as vector to proceed similarity search. The parent document’s score will be the maximum similarity score of its children.
5. Example
A good example for all the above is when we have written transcriptions of knowledge sharing sessions or other kind of presentations and we want to build a search bot. Usually presentation or knowledge sharing transcriptions are way longer than embedding limitations with a few hundred words. With the method I explained above you’ll be able to run searches on your knowledge base like “Show presentations about user interface development”. Here is a real example answer from our knowledge sharing bot on our company Slack:
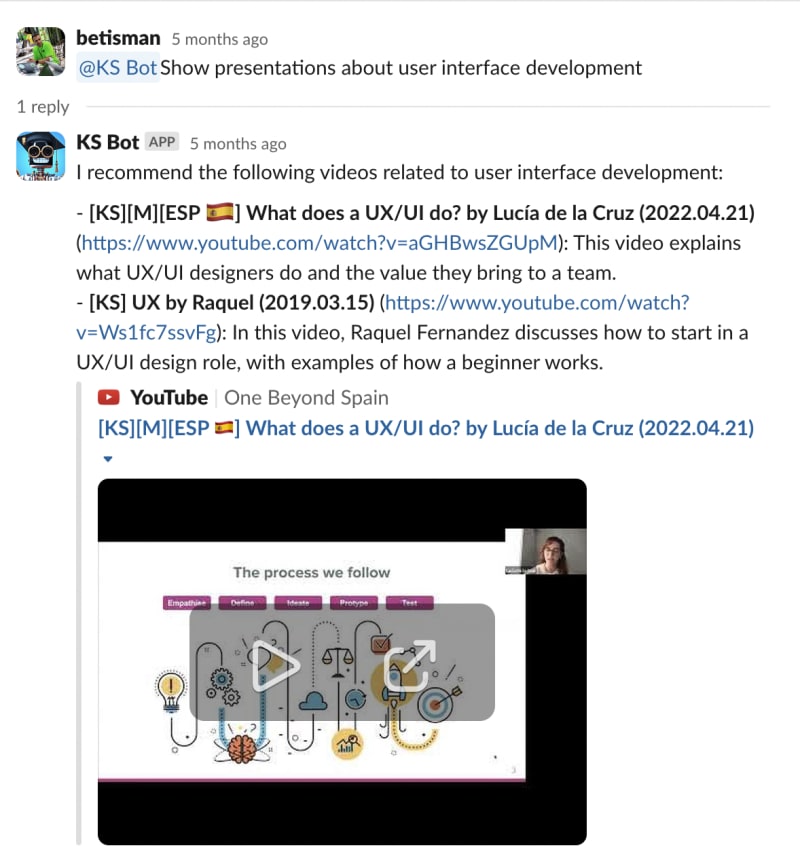
Semantic search is a powerful information retrieval technique that goes beyond traditional keyword matching to understand the meaning and context of user queries. In the context of searching for UI development presentations, semantic search can enhance the search experience by considering the underlying concepts and relationships between words.
For instance, this query was focused on UI development, but semantic search algorithms can recognize related terms like "user experience (UX)" even if not explicitly mentioned in the query. This enables the system to retrieve presentations that may be relevant to UX, ensuring a more comprehensive and accurate set of results. In essence, semantic search helps bridge the gap between user intent and search results by intelligently interpreting the meaning behind the words used in the query.
Posted on November 15, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
