Introduction to Data Engineering

OLABAYO BALOGUN
Posted on December 23, 2021

Introduction
The year is 2021, and the internet as we know it is transitioning into web 3.0, with web 4.0 becoming more than a concept note. Underneath all the pomp and fanfare, we produce a massive amount of data that needs to be refined and properly categorized before all of the massive digital infrastructures we leverage on a daily basis can work.
Data engineering is a practice where you design and build systems to collect, store, and analyze data at scale. A more relatable explanation is that data engineering is what is done to data that we receive from users (or alternative sources) to ensure that the said data is useful and can be relied upon to make decisions that may result in a product or service.
For many, the term data engineering seems like something that should fall under the purview of data scientists. However, the reality is that data engineers have entirely different responsibilities from what data scientists do. Data engineers create an enabling environment for data scientists to perform their analysis of data.
In the past (and present in some organizations that are behind the times), data scientists would complain about the data they needed to analyze. Most of the data they were working with required a lot of cleanup to be useful. These cleanups constituted 80% of their workload and delayed data analysis. Data engineering exists to get rid of this bottleneck.
To the untrained eye, having data scientists clean the data might not look like much, but for organizations in fast-moving industries, such as machine learning, it can be quite a nightmare for data scientists. Data engineering exists to improve the efficiency of data scientists by working with all stakeholders, including software engineers and database administrators.
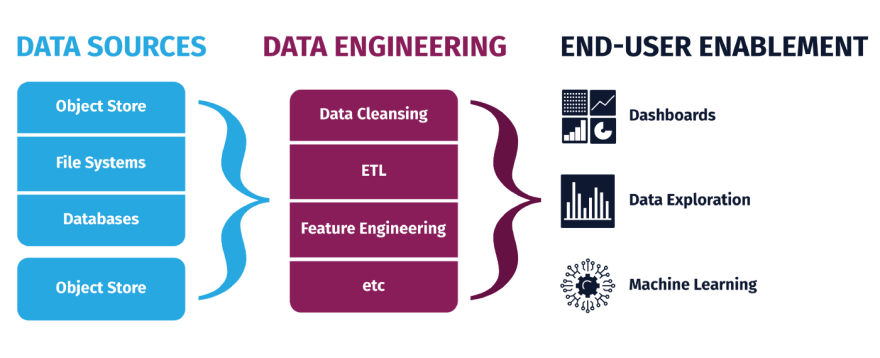
Applications Of Data Engineering
The applications of data are inexhaustible. But, despite the work of software engineers and other well-meaning professionals, the data that makes its way from applications to databases is far from what data scientists need. While there are processes like input validation put in place by software engineers, a huge amount of data slips through the cracks and must be fixed.

Data Cleansing
If there’s anything this article must have sold you on, it should be this: we need data engineers to clean up our data. For many, data is hard to conceptualize. We perceive data as just pictures, music, videos, and word documents floating around cyberspace and possibly on devices. Perceiving data in such a way prevents us from seeing the need for clean up of data.
Data cleansing or data cleaning is when you fix or remove incorrect, corrupted, inaccurately formatted, repeated, or incomplete data within a dataset. Data cleansing is different from data transformation (though some argue that data transformation is encompassed by data cleansing). Data transformation involves changing the format or the structure of data.
If data is dirty, then it is unreliable. The impact of unreliable data manifests in algorithms. A recent example of what can happen when algorithms are wrong is Zillow’s $569 million financial scandal, where the algorithm was blamed for the error. However, algorithms work hand in hand with data. So, a bad algorithm is a function of bad data.

ETL
ETL is an acronym for extract, transform and load. ETL describes the process of taking data from one or more sources, manipulating it, and storing it somewhere else. The process of manipulation of this data changes some of the characters and characteristics of the data. ETL is where data warehousing is called upon.
The amount of liquid capital required to store and manage data gave rise to industries like PaaS (Platform as a Service) and IaaS (Infrastructure as a Service), all of which can be regarded as a cloud data warehouse. ETL has to occur because if a project is big enough, the data it requires will come from different sources, and these sources may have different storage conventions.
At other times, ETL is used to create databases in compliance with laws and as a company decides to change its cloud storage processes. On a small scale, this may not seem like much. However, when you’re dealing with thousands of databases holding millions of datasets, ETL becomes a project in itself.

Feature Engineering
Feature engineering describes the act of identifying and manipulating key component(s) of unprocessed data to create statistical models and predictive models through the use of machine learning. As a result of the amount of esoteric knowledge one needs to have about the dataset, data engineers are the best qualified to carry out feature engineering.
Modeling is at the heart of machine learning, artificial intelligence, and other disciplines that require strong predictive analysis. Feature engineering is a critical process that can determine how algorithms behave, and, if Zillow is anything to go by, mistakes at this level can prove costly if not quickly identified.
Conclusion
Data engineering remains indispensable for making sense of the noise we now know as data. The work that goes into clearing the rubble to create order among data sets is one that is well worth its weight in gold now that data is beginning to take on a larger-than-life persona. As we stabilize web 3.0 and try to chart our course for web 4.0, our need for solid footing on not just data, but refined and structured data, can very well be the determining factor in building the internet of the future.
Posted on December 23, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related