Amazon DynamoDB: SQL, NoSQL e Escala. Como o DynamoDB escala onde bancos de dados relacionais não!

Eduardo Rabelo
Posted on February 10, 2020

Nos últimos anos, o DynamoDB se tornou cada vez mais popular como banco de dados. Isso ocorreu por alguns motivos, como o modo que ele se adapta tão bem às arquiteturas serverless que usam o AWS Lambda, o AWS AppSync ou devido à crescente comunidade de como modelar o DynamoDB estimulada pelas conversas do incrível Rick Houlihan.
Quando falo com pessoas novas no DynamoDB, geralmente ouço as mesmas queixas iniciais:
- "Uau, isso parece estranho."
- "Por que o DynamoDB não tem JOIN?"
- "Por que não posso fazer agregações?"
- "Por que o DynamoDB é tão difícil?"
Para entender a resposta a essas reclamações, você precisa saber uma coisa importante sobre o DynamoDB:
O DynamoDB não permitirá que você escreva uma consulta incorreta.
Quando digo "consulta incorreta", quero dizer "consulta que não será possível escalar". O DynamoDB foi desenvolvido para escalar. Quando você escreve um aplicativo usando o DynamoDB, você obtém as mesmas características de desempenho quando há 1 GB de dados e quando há 100 GB de dados ou 100 TB de dados.
O mesmo não se aplica aos bancos de dados relacionais. Seu aplicativo pode parecer rápido quando é implementado pela primeira vez, mas você verá a degradação do desempenho à medida que o banco de dados aumenta.
Nesta postagem, veremos como os bancos de dados são ou não escalonáveis. Abordaremos os seguintes tópicos:
- O maior problema com bancos de dados relacionais: imprevisibilidade
- Como o DynamoDB shifts left na escalabilidade
- Os três motivos pelos quais os bancos de dados relacionais enfrentam problemas em grande escala
- Como o DynamoDB evita os três problemas
Onde você pode encontrar problemas de desempenho com o DynamoDB.
"shifts left" é um termo para a prática de testes em estágios iniciais do desenvolvimento de software
Nota: Nada disso sugere que o DynamoDB é o "único banco de dados verdadeiro que deve ser usado para tudo". Há prós e contras em tudo, e você deve considerar o seu cuidadosamente ao escolher um banco de dados.
Vamos começar!
A imprevisibilidade de bancos de dados relacionais
Os bancos de dados relacionais são uma maravilhosa peça de tecnologia. Eles são relativamente fáceis de entender, o que os tornou o primeiro banco de dados a se aprender para novos desenvolvedores. Eles trabalham para uma ampla variedade de casos de uso e, portanto, são a opção padrão para a maioria dos aplicativos. E os bancos de dados relacionais têm SQL, uma sintaxe de consulta flexível que facilita o manuseio de novos padrões de acesso ou os padrões OLTP e OLAP em um único banco de dados.
Mas há um grande problema com bancos de dados relacionais: o desempenho é como uma caixa preta. Há vários fatores que afetam a rapidez com que suas consultas retornam.
Durante o teste e no início do ciclo de vida do seu aplicativo, você pode ter uma consulta no seu aplicativo que retorne rapidamente:

Nesses estágios iniciais, a consulta retorna rápida e tudo está bem.
Mas o que acontece quando o seu conjunto de dados aumenta? Em nossa consulta de exemplo, temos JOI em uma instrução GROUP BY. À medida que o tamanho de suas tabelas aumenta, essas operações ficam cada vez mais lentas.

E não é apenas do tamanho das suas tabelas que você precisa se preocupar. O desempenho do banco de dados relacional também é afetado por outras consultas em execução ao mesmo tempo. O que acontece com o desempenho da sua consulta quando 100 dessas grandes consultas estão em execução ao mesmo tempo? Ou se o gerente de produto estiver executando uma grande consulta de análise no seu banco de dados para encontrar os principais usuários do mês passado?

O desempenho do seu banco de dados relacional está sujeito a vários fatores - tamanho da tabela, tamanho do índice, consultas simultâneas - que são difíceis de testar com precisão e antecedência. Mesmo se você tiver uma boa idéia do número de solicitações por segundo que precisará suportar, é complicado convertê-lo no tamanho de instância adequado (número de CPUs + RAM) que pode lidar com essas solicitações.
É essa imprevisibilidade que pode ser enlouquecedora com um banco de dados relacional.
Como o DynamoDB "shifts left" na escalabilidade
Uma grande mudança no desenvolvimento de software nos últimos vinte anos é a ideia de "shift left testing". A mudança principal é mover os testes para à esquerda no ciclo de vida do software, testando no início do ciclo de vida do desenvolvimento de software, ao invés de esperar até o final.
Imagine um gráfico com um eixo X representando o ciclo de vida completo da construção de um produto, desde requisitos e design até desenvolvimento e suporte. Normalmente, o teste seria realizado mais tarde no ciclo de vida após a conclusão do design e implementação iniciais.

O modelo tradicional de desenvolvimento de software - a maioria dos testes ocorre após a implementação.
"Shift Left" sugere incluir testes no início do ciclo de vida ou "mover para a esquerda" no eixo X (daí o nome 'shift left'). O principal motivo é que é melhor encontrar defeitos antecipadamente, enquanto é mais fácil mudar, com pouco tempo desperdiçado no desenvolvimento.
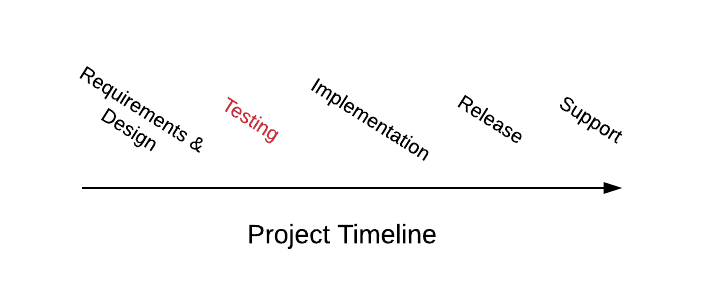
O modelo shift-left do desenvolvimento de software - faça mais testes antecipadamente.
Há um modelo semelhante em jogo com bancos de dados e escalabilidade. Muitos bancos de dados são difíceis de testar com antecedência. Tudo corre bem em ambientes de teste em baixa escala.
Em essência, esse é o "modelo tradicional" de escalabilidade - você realiza algum trabalho relacionado à escalabilidade antecipadamente, como criação de índice e planejamento de capacidade. No entanto, a maior parte do problema é acontece quando o aplicativo atinge a escala real e começa a esticar os limites do banco de dados.
O DynamoDB, por outro lado, usa um modelo de escalabilidade shift-left. Obriga você a pensar em projetar seu modelo de dados antecipadamente de uma maneira que seja escalável.
Com o DynamoDB, não há caixa preta sobre como o seu banco de dados será dimensionado:
- Com que rapidez minha consulta retornará quando a escala for 100X maior? O mesmo - milissegundos de um dígito
- Como minha consulta afetará outras consultas no banco de dados? Não vai - as consultas são limitadas no impacto dos recursos alocados
Essa abordagem de "shift-left" não tem custo. Você precisará dedicar tempo para realmente entender os padrões de acesso do seu aplicativo com antecedência e projetar seu modelo de dados de acordo. Parece chato, mas o retorno é bem alto - você não precisará refazer o modelo de dados devido a problemas de dimensionamento. Você obterá exatamente o mesmo desempenho em 10 TB e em 1 GB.
Como o DynamoDB faz isso? Isso envolve algumas decisões importantes de design no DynamoDB. Mas antes de nos aprofundarmos nisso, vamos ver as diferentes maneiras pelas quais os bancos de dados relacionais não são escaláveis, pois isso informa as decisões de design por trás do DynamoDB.
Por que os bancos de dados relacionais não escalam
Ah, o RDBMS - a maravilhosa tecnologia subjacente a sistemas bancários, hospitais e, claro, 90% da internet que roda no Wordpress.
O RDBMS nos serviu notavelmente bem e ainda é uma ótima opção para muitas aplicações. É bem conhecido pelos desenvolvedores, é flexível para evoluir conforme suas necessidades mudam e fornece funcionalidade OLTP e OLAP.
No entanto, vimos várias empresas migrando dos bancos de dados RDBMS para NoSQL nos últimos vinte anos devido a problemas com o RDBMS em escala. Para saber mais, dê uma olhada no Dynamo Paper, escrito por alguns engenheiros da Amazon.com (incluindo o atual CTO da AWS Werner Vogels), que apresenta os conceitos por trás do banco de dados Dynamo criado para a Amazon.com. O Dynamo Paper inclui muitas das decisões de design por trás do DynamoDB e inspirou bancos de dados NoSQL posteriores, como o Apache Cassandra.
Existem três grandes problemas com bancos de dados relacionais que dificultam sua escala:
- As más características de complexidade de tempo do SQL JOIN;
- A dificuldade em dimensionar horizontalmente; e
- A natureza sem restrições das consultas
Exploraremos cada um deles abaixo.
SQL JOIN têm complexidade de tempo ruim
O primeiro problema com o RDBMS deriva da operação JOIN.
Em uma operação de JOIN, seu banco de dados relacional está combinando resultados de duas ou mais tabelas diferentes. Você não apenas está lendo um pouco mais de dados, mas também está comparando os valores um para o outro para determinar quais valores devem ser retornados.
Rick Houlihan, em sua épica palestra no re:Invent em 2019 no DynamoDB, percorreu parte da complexidade de tempo de SQL JOINs em comparação às operações do DynamoDB. Seus resultados variam com base no tipo de JOIN que você está usando, bem como nos índices de suas tabelas, mas você pode estar obtendo tempo linear ( O (M + N)) ou pior.
Essas operações com uso intenso de CPU funcionarão bem durante o teste ou enquanto seus dados forem pequenos. À medida que seus dados aumentam, você começará lentamente a ver o uso da CPU aumentar e o desempenho da consulta diminuir. Como tal, convém ampliar seu banco de dados. Isso nos leva ao próximo problema com bancos de dados relacionais.
É difícil dimensionar horizontalmente um RDBMS
O segundo problema com o RDBMS é que eles são difíceis de dimensionar horizontalmente.
Existem duas maneiras de dimensionar um banco de dados:
- Escala vertical, aumentando a CPU ou RAM de suas máquinas de banco de dados existentes ou
- Escala horizontal, adicionando máquinas adicionais ao cluster de banco de dados, cada uma das quais manipula um subconjunto do total de dados.
Em escala mais baixa, provavelmente não há uma enorme diferença de preço entre as escalas vertical e horizontal. De fato, com a AWS, eles fizeram um bom trabalho de paridade de preços entre uma máquina grande e várias máquinas menores.
No entanto, você atingirá os limites da escala vertical. Seu provedor de nuvem não terá uma caixa grande o suficiente para lidar com seu crescente banco de dados. Nesse ponto, convém considerar a escala horizontal. Agora você está tendo problemas maiores.
O ponto principal da escala horizontal é que cada máquina em seu cluster geral manipula apenas uma parte do total de dados. À medida que seus dados continuam a crescer, você pode adicionar máquinas adicionais para obter a quantidade de dados em cada máquina relativamente estável.
Isso é complicado com um banco de dados relacional, pois geralmente não há uma maneira clara de dividir os dados. Muitas vezes, você deseja armazenar todos os resultados de uma determinada tabela na mesma máquina para poder lidar corretamente com a exclusividade e outros requisitos.
Se você dividir tabelas em máquinas diferentes, agora suas junções SQL exigirão uma solicitação de rede além do cálculo da CPU.
A escala horizontal funciona melhor quando você pode compartilhar os dados de maneira que uma única solicitação possa ser tratada por uma única máquina. Pular em várias caixas e fazer solicitações de rede entre elas resultará em desempenho mais lento.
As consultas relacionais são sem restrições
O terceiro problema com o RDBMS é que, por padrão, as consultas SQL não têm restrições. Não há limite inerente para a quantidade de dados que você pode digitalizar em uma única solicitação para o banco de dados, o que também significa que não há limite inerente para como uma única consulta incorreta pode consumir seus recursos e bloquear o banco de dados.
Um exemplo simples seria uma consulta como SELECT * FROM large_table - uma verificação completa da tabela para recuperar todas as linhas. Mas isso é bastante óbvio no código do aplicativo e é menos provável que consuma todos os recursos do banco de dados.
Um exemplo mais nefasto seria algo como o seguinte:
SELECT user_id, sum(amount) AS total_amount
FROM orders
GROUP BY user_id
ORDER BY total_amount DESC
LIMIT 5
O exemplo acima examina a tabela orders em um aplicativo para encontrar os 5 principais usuários pelo valor gasto. Um desenvolvedor pode pensar que essa não é uma operação cara, pois está retornando apenas 5 linhas. Mas pense nas etapas envolvidas nesta operação:
- Digitalizar toda a tabela de pedidos
- Agrupe pedidos pelo ID do usuário e some o valor do pedido por usuário para encontrar um total
- Ordene os resultados da etapa anterior de acordo com o total somado
- Retornar os 5 principais resultados
Isso é caro em vários recursos diferentes - CPU, memória e disco. E está completamente escondido do desenvolvedor.
Agregações são armadilhas para os desavisados, prontos para derrubar seu banco de dados quando você atinge uma escala maior.
Como os bancos de dados NoSQL lidam com esses problemas relacionais
Na seção anterior, vimos como os bancos de dados relacionais enfrentam problemas à medida que escalam. Nesta seção, veremos como os bancos de dados NoSQL, como o DynamoDB, lidam com esses problemas. Sem surpresa, eles são essencialmente o inverso dos problemas listados acima:
- O DynamoDB não permite JOINs;
- O DynamoDB obriga a segmentar seus dados, permitindo uma escala horizontal mais fácil; e
- O DynamoDB coloca limites explícitos em suas consultas.
Novamente, vamos revisar cada um deles em ordem.
Como os bancos de dados NoSQL substituem JOINs
Primeiro, vamos ver como os bancos de dados NoSQL substituem JOINs. Para fazer isso, devemos entender os trabalhos que as associações estão realizando em um banco de dados relacional.
A maneira canônica de modelar seus dados em um banco de dados relacional é normalizar suas entidades. A normalização é um assunto complexo que não abordaremos aqui em profundidade, mas essencialmente você deve evitar repetir qualquer dado singular em um banco de dados relacional. Em vez disso, você deve criar um registro canônico dos dados e fazer referência a esse registro canônico sempre que necessário.
Por exemplo, um cliente em um aplicativo de comércio eletrônico pode fazer vários pedidos ao longo do ano. Ao invés de armazenar todas as informações do cliente no próprio registro do pedido, o registro do pedido conteria uma propriedade CustomerId que apontaria para o registro canônico do cliente.

No exemplo acima, o pedido #348901 tem uma propriedade CustomerId com um valor de 145. Isso aponta para o registro na tabela Customers com um Id de 145. Se o cliente nº145 alterar algo sobre ele, como seu nome ou endereço, o pedido não precisará fazer as alterações correspondentes.
Há dois benefícios nessa abordagem:
- Eficiência de armazenamento: Com um único registro de dados nós podemos "escrever uma vez, referenciar em várias", os bancos de dados relacionais requerem menos armazenamento do que as opções que duplicam os dados em vários registros.
- Integridade dos dados: É mais fácil garantir a integridade dos dados entre as entidades com um banco de dados relacional. No exemplo acima, se você duplicar as informações do cliente em cada registro de pedido, poderá ser necessário atualizar cada registro de pedido quando o cliente alterar algumas informações sobre si. Em um banco de dados relacional, você só precisa atualizar o registro do cliente. Todos os registros que se referem a ele receberão as atualizações.
No entanto, normalização significa que seus dados estão espalhados por todo o lugar. Como recupero o registro do pedido e as informações sobre o cliente que o fez?
É aqui que entram JOINs. Elas permitem remontar dados de vários registros diferentes em uma única operação. Eles oferecem uma enorme flexibilidade no acesso aos seus dados. Com a flexibilidade das JOINs e o restante da gramática SQL, você pode basicamente remontar quaisquer dados conforme necessário. Devido a essa flexibilidade, você realmente não precisa pensar em como acessará seus dados com antecedência. Você modela suas entidades de acordo com os princípios da normalização e depois escreve as consultas para atender às suas necessidades.
No entanto, como observado acima, essa flexibilidade tem um custo - as JOINs exigem muita CPU e memória. Portanto, para se livrar das JOINs SQL, o NoSQL precisa lidar com os três benefícios das JOINs:
- Acesso flexível a dados
- Integridade de dados
- Eficiência de armazenamento
Dois deles são tratados por tradeoffs específicos, enquanto o terceiro é menos uma preocupação.
Primeiro, os bancos de dados NoSQL evitam a necessidade de flexibilidade no acesso a dados, exigindo que você faça um planejamento antecipado. Como você irá ler seus dados? Como você irá escrever seus dados? Ao trabalhar com um banco de dados NoSQL, você precisa considerar essas questões completamente antes de projetar seu modelo de dados. Depois de conhecer seus padrões, você pode projetar seu banco de dados para lidar especificamente com essas questões. Ao invés de remontar seus dados no momento da leitura, você 'pré-juntará' os dados, colocando-os da maneira que serão lidos.
A segunda desvantagem dos bancos de dados NoSQL é que a integridade dos dados agora é uma preocupação no nível do aplicativo. Enquanto JOINs permitiria um padrão "escrever uma vez, referenciar em várias" para nossos dados, talvez você precise desnormalizar e duplicar dados no seu banco de dados NoSQL. Para dados inalterados (datas de nascimento, datas dos pedidos, leituras dos sensores), essa duplicação não é um problema. Para dados que mudam, como nomes de exibição ou preços listados, você pode estar atualizando vários registros no caso de uma alteração.
Finalmente, os bancos de dados NoSQL são menos eficientes em termos de armazenamento do que seus pares relacionais, mas isso geralmente não é uma preocupação. Quando o RDBMS foi projetado, o armazenamento era mais premium que a computação. Esse não é mais o caso - os preços de armazenamento caíram no chão enquanto a Lei de Moore está desacelerando. A computação é o recurso mais valioso em seus sistemas; portanto, faz sentido otimizar a computação ao invés de armazenamento.
Por que os bancos de dados NoSQL escalam horizontalmente
Na seção anterior, vimos como os bancos de dados NoSQL lidam com o problema de complexidade de tempo em torno das JOINs, exigindo que você organize seus dados de forma que eles sejam pré-unidos para o seu caso de uso. Nesta seção, veremos como o NoSQL resolve o problema de escala, permitindo a escala horizontal.
O principal motivo pelo qual os bancos de dados relacionais não podem ser dimensionados horizontalmente é devido à flexibilidade da sintaxe da consulta. O SQL permite que você adicione todos os tipos de condições e filtros aos seus dados, de forma que seja impossível para o sistema de banco de dados saber quais partes de seus dados serão buscadas até que sua consulta seja executada. Como tal, todos os dados precisam ser mantidos locais, no mesmo nó, para evitar chamadas de rede entre máquinas ao executar uma consulta.
Para evitar esse problema, os bancos de dados NoSQL exigem que você divida seus dados em segmentos menores e execute todas as consultas em um desses segmentos. Isso é comum em todos os bancos de dados NoSQL. No DynamoDB e Cassandra, é chamada de chave de partição. No MongoDB, isso é chamado de chave de fragmento.
A maneira mais fácil de pensar em um banco de dados NoSQL é uma tabela de hash em que o valor de cada chave na tabela de hash é uma Árvore B. A chave de partição é a chave na tabela de hash e permite espalhar seus dados por um número ilimitado de nós.
Vamos ver como essa chave de partição funciona. Suponha que você tenha um modelo de dados centrado nos usuários e, portanto, use UserId como chave de partição. Quando você grava seus dados no banco de dados, ele usa esse valor de UserId para determinar qual nó deve ser usado para armazenar a cópia principal dos dados.
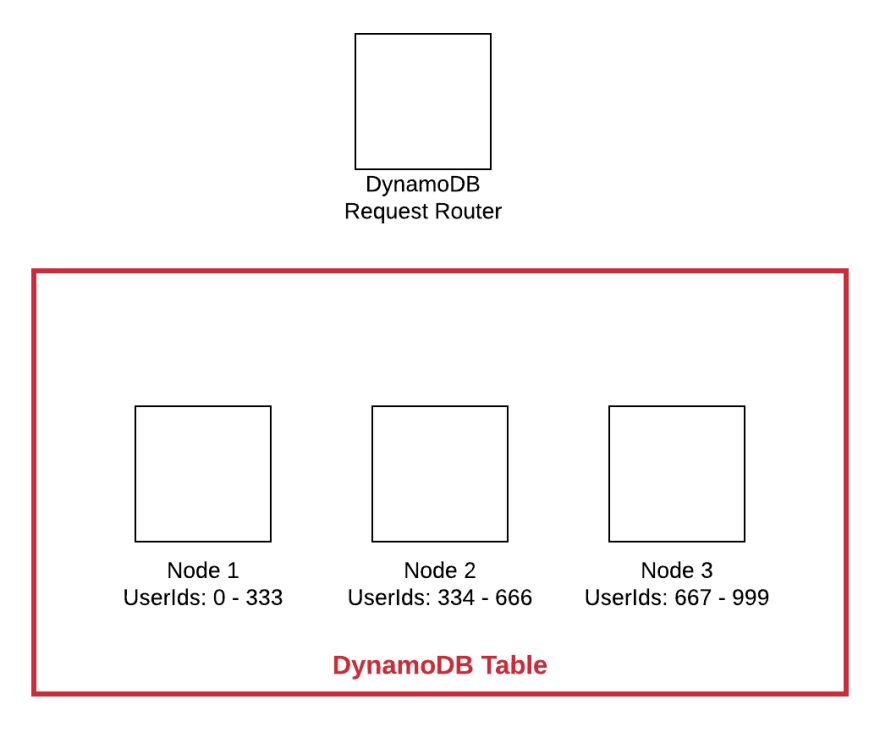
No diagrama simplificado acima, a caixa vermelha indica nossa tabela do DynamoDB como um todo. Dentro da tabela, existem três nós que armazenam todos os dados. Cada nó é o principal para um subconjunto diferente dos dados.
Quando uma nova gravação chega com um valor UserId igual a 741, o DynamoDB Request Router determinará qual nó deve manipular os dados. Nesse caso, ele é roteado para o Nó 3, pois é responsável por todos UserId entre 667 e 999.

Nota: A maioria dos bancos de dados NoSQL faz o hash do valor da chave da partição antes de atribuí-lo a um nó. Isso ajuda a distribuir melhor os dados, principalmente quando a chave da partição está aumentando monotonicamente (de modo uniforme). Para obter mais informações, consulte a documentação do MongoDB sobre Hashed Sharding.
No momento da leitura, todas as consultas devem incluir a chave da partição. Assim como na gravação, essa operação pode ser enviada para o nó responsável por essa parte dos dados sem incomodar os outros nós no cluster.

Esse mecanismo de sharding é o que permite a escala essencialmente infinita do NoSQL sem degradação do desempenho. À medida que o volume de dados aumenta, você pode adicionar nós adicionais, conforme necessário. Toda operação atinge apenas um nó no cluster.
Como o DynamoDB restrita suas consultas
A maneira final pelo qual o DynamoDB evita problemas de escalabilidade do RDBMS é que ele limita suas consultas.
Mencionamos anteriormente que o DynamoDB é basicamente uma tabela de hash distribuída em que o valor de cada chave é uma Árvore B. Encontrar o valor da tabela de hash é uma operação rápida e atravessar sequencialmente uma Árvore B é uma operação eficiente. No entanto, se você tiver uma coleção grande de itens, pode demorar um pouco para ler e devolver os itens. Imagine executar uma operação Query que corresponda a todos os itens em uma coleção de itens com 10 GB no total. É bastante I/O, tanto no disco quanto na rede, para lidar com tantos dados.
Por esse motivo, o DynamoDB impõe um limite de 1MB no Query e Scan, as duas operações de leitura de "buscam muitos" no DynamoDB. Se sua operação tiver resultados adicionais após 1MB, o DynamoDB retornará uma propriedade LastEvaluatedKey que você pode usar para manipular a paginação no lado do cliente.
Esse limite é o requisito final para o DynamoDB oferecer garantias de latência de milissegundos de um dígito em qualquer consulta em qualquer escala. Vamos revisar as operações envolvidas em uma grande operação de consulta:
Operação: 1. Encontre o nó para a chave de partição
Estrutura de dados:: Tabela de Hash
Notas: Complexidade de tempo de O(1)
Operação: 2. Encontre o valor inicial para a chave de classificação
Estrutura de dados:: Árvore B
Notas: Complexidade de tempo de O(log n), onde n está o tamanho da coleção de itens, não a tabela inteira
Operação: 3. Leia os valores até o final da correspondência da chave de classificação
Estrutura de dados:: -
Notas: Leitura sequencial. Limitado a 1 MB de dados
Não há muito espaço para o desempenho de uma única consulta diminuir à medida que o aplicativo cresce. A operação inicial de segmentar por chave de partição ajuda a reduzir sua tabela de escala gigantesca (100 TB) para uma única coleção de itens (geralmente <10 GB). Em seguida, a pesquisa em árvore b é executada em uma quantidade gerenciável de dados e os riscos do disco são poucos.
Uma nota final sobre as implicações dessa delimitação antes de prosseguir. O DynamoDB não tem suporte para quaisquer operações de agregação, como max, min, avg, ou sum. Meu palpite é que é devido a esse limite de 1 MB, ele poderia retornar resultados inconsistentes. Imagine que você tenha uma coleção de itens de 1 GB e execute uma Query contra esses itens com uma agregação max em um atributo específico. O DynamoDB deseja ler 1 MB de dados nessa solicitação; portanto, esse max se aplicaria apenas ao 1 MB lido, e não a 1 GB inteiro de dados na coleção de itens.
Isso pode confundir os usuários quanto ao comportamento das agregações. Provavelmente é melhor para o aplicativo lidar com agregações em tempo de gravação, armazenando informações agregadas em um item de resumo em uma coleção de itens.
Além disso, se você realmente quiser o valor max desse conjunto de resultados de 1MB que foi lido, é muito simples para você calcular isso do lado do cliente. Portanto, acho improvável que tenhamos suporte explícito à agregação em Query ou Scan no futuro próximo.
Onde você pode encontrar problemas de desempenho com o DynamoDB à medida que escala
Nas seções acima, vimos como o DynamoDB foi projetado para fornecer uma escala massiva, fazendo você considerar as preocupações de escalabilidade antecipadamente. Na grande maioria dos aplicativos, sua tabela do DynamoDB executará exatamente o mesmo no teste e em milhões de solicitações por segundo.
No entanto, há duas situações em que você pode ver a degradação do desempenho conforme o aplicativo é escalado. Essas situações são:
- Paginação
- Hot Keys
Vamos abordar cada um destes abaixo.
Paginação
Anteriormente, vimos como DynamoDB limita o tamanho do resultado de uma peração Query ou Scan para 1 MB de dados. Mas o que acontece se sua operação tiver mais de 1 MB de dados? O DynamoDB retornará uma propriedade LastEvaluatedKey em sua resposta. Essa propriedade pode ser enviada na solicitação seguinte para continuar a paginação na sua consulta de onde você parou.
Essa paginação pode morder você à medida que você escala. Quando seus dados são pequenos ou em teste, talvez você não precise paginar os resultados ou pode ser apenas uma solicitação de buscar a segunda página de resultados. À medida que seus dados crescem, esse padrão de acesso pode demorar mais e mais, pois são necessárias várias páginas.
Felizmente, esse problema é muito fácil de identificar e considerar com antecedência. Na maioria das vezes, você pode procurar na cadeia de código a string LastEvaluatedKey. Se você não vir essa propriedade, é provável que você não esteja usando a paginação e possa pular esta seção completamente.
Nota: Existem outras maneiras de paginar sem usar LastEvaluatedKey, como o Query Paginator no Boto3 ou se estiver usando um cliente DynamoDB de terceiros que ofereça suporte a uma paginação mais fácil. Se for esse o caso, você precisará olhar mais de perto para ver como está paginando.
Se você se encontrar fazendo paginação, precisa pensar em mais casos. Considere as seguintes perguntas:
- Essa paginação está em um hot key em que o tempo de resposta é importante (por exemplo, uma solicitação HTTP voltada para o usuário)?
- Existe uma chance de o tamanho do resultado de uma consulta aumentar a ponto de exigir várias páginas (3 ou mais) para passar por todos os resultados?
- Se sim aos dois acima, onde devo lidar com a paginação?
Vamos dar um exemplo. Imagine que você está construindo um jogo online para vários jogadores, como o Fortnite, onde os jogadores jogam vários jogos ao longo do tempo. Você tem um padrão de acesso - ListGamesForPlayer- onde um jogador pode ver os jogos anteriores que jogou.
Com o tempo, o número de jogos para um único jogador aumentará, de modo que você precisará usar a paginação para obter os resultados. Ao projetá-lo inicialmente, você pode buscar todos os resultados em seu aplicativo e devolvê-los ao cliente:
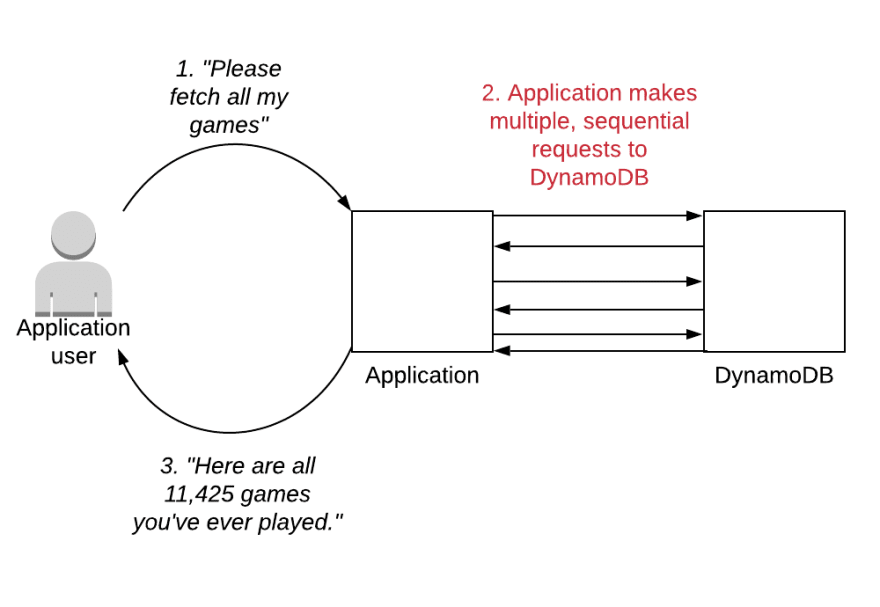
No exemplo acima, o usuário faz uma solicitação ao back-end para os jogos do usuário. Nesse caso, existem muitos jogos - mais de 11.000. O aplicativo busca todos esses jogos no back-end e os devolve ao usuário.
Esse endpoint ficará mais lento com o tempo para jogadores com muitos jogos, pois o servidor fará toda a paginação nessa solicitação única do cliente.
Se você pensar bem, o player que está visualizando esses resultados provavelmente não consegue lidar com a visualização de todos os resultados ao mesmo tempo. Visualizar 11.000 resultados em uma página é incontrolável. Eles provavelmente querem ver os 10 ou 20 resultados mais recentes e raramente querem se aprofundar nos resultados antigos.
Você pode alternar para que a paginação ocorra no cliente. O endpoint de ListGamesForPlayer pode retornar apenas os 20 resultados mais recentes. Se o usuário quiser ver mais, o aplicativo cliente terá um botão "próximo" ou usará a rolagem infinita para buscar jogos adicionais.
Agora nosso padrão de acesso fica assim:

O usuário solicita uma lista de jogos. O aplicativo faz uma única solicitação ao DynamoDB e retorna os primeiros vinte jogos, bem como a hora do último jogo lido. Podemos mostrar vinte jogos em uma interface do usuário com bastante facilidade.
Se o usuário desejar revisar jogos mais antigos, o front-end poderá usar páginas ou rolagem infinita para permitir que os usuários se aprofundem mais. Isso faria uma solicitação consecutiva ao aplicativo para solicitar mais jogos, com data anterior do último recebido. Obteríamos os próximos vinte resultados para mostrar ao usuário.
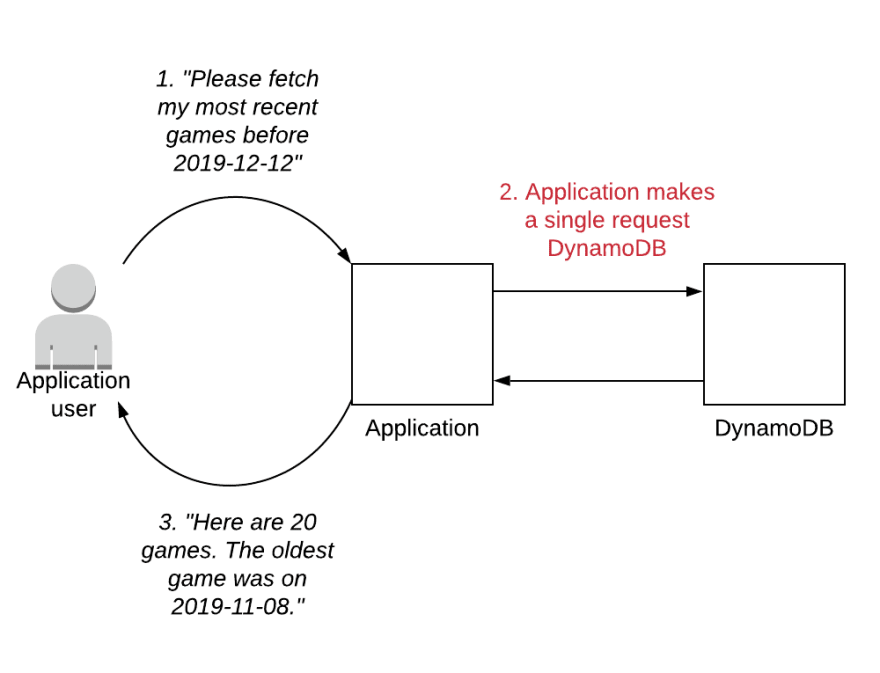
Nosso endpoint permanece ágil e paginamos apenas os dados para buscar mais resultados quando realmente são necessários pelo usuário.
Nota: Para informações adicionais sobre padrões de paginação no DynamoDB, leia o artigo de Yan Cui: "Pessoal, estamos fazendo paginação errada...".
Hot Keys
A segunda e mais maligna maneira pela qual a tabela do DynamoDB terá problemas à medida que é escalada é através das hot keys.
Hot Keys é uma coleção de itens acessada com uma frequência mais significante do que as outras coleções de itens em uma tabela. Por exemplo, imagine o Twitter. Justin Bieber, com seus >100 milhões de seguidores, provavelmente será acessado com mais frequência do que eu, com meus poucos seguidores. Se esses dados foram lidos diretamente no DynamoDB, os Beliebers podem causar uma hot key no perfil de Justin.
Hot Keys podem aparecer em vários padrões diferentes. Você pode ter uma única chave que seja consistentemente quente, como no exemplo de Justin Bieber acima. Isso também pode ser verdade se você não projetar sua chave de partição corretamente e tiver uma carga de trabalho desequilibrada. Em uma veia diferente, você também pode fazer com que hot keys diferentes fiquem quentes em momentos diferentes. Imagine um site de ofertas rápidas onde diferentes itens foram colocados à venda por curtos períodos de tempo. Enquanto um item estiver à venda, ele será acessado com muito mais frequência do que os outros itens.
Há boas e más notícias em torno de hot keys.
A boa notícia é que as hot keys são principalmente um problema para aplicativos com uma escala realmente alta. E este é um bom problema para ter! Parabéns por fazer algo que as pessoas usam. Por um tempo, você pode escolher se escalar desse problema. O DynamoDB tem um máximo de 3.000 RCUs e 1.000 WCUs em uma única partição. As RCUs e as WCUs são realizadas por segundo, para que você possa ler um item de 4KB 3.000 vezes por segundo e ainda assim ficar bem. Isso é suficiente para a maioria das aplicações.
Além disso, o DynamoDB trabalhou muito nos últimos anos para ajudar a aliviar os problemas relacionados às hot keys. O DynamoDB costumava distribuir uniformemente o rendimento provisionado pelas partições. Isso significava que você precisava provisionar mais recursos para taxa de transferência para lidar com uma única partição mais quente. Isso mudou em 2017, quando o DynamoDB anunciou a capacidade de adaptação. A capacidade adaptativa muda automaticamente a taxa de transferência da sua tabela para as partições que mais precisam dela. Inicialmente, levaria alguns minutos para a capacidade adaptativa reagir a uma partição quente. Em maio de 2019, a AWS anunciou que a capacidade de adaptação do DynamoDB agora é instantânea. Além disso, eles anunciaram um recurso no final de 2019 para isolar automaticamente itens quentes, movendo-os para outra partição.
A má notícia sobre as hot keys é que pode ser realmente complicado conhecer suas hot keys ao projetar sua tabela. Não há um indicador fácil como a propriedade LastEvaluatedKey no caso de uso da paginação. Estamos quase de volta ao mundo do SQL, onde há pouca visibilidade sobre o desempenho da sua consulta à medida que ela cresce.
Uma ferramenta útil nessa área é o CloudWatch Contributor Insights for DynamoDB. Quando você ativa o CloudWatch Contributor Insights na tabela do DynamoDB ou no índice secundário, o DynamoDB efetua logs da partição e classifica as chaves acessadas na tabela. Você pode usar os gráficos do CloudWatch para encontrar as chaves acessadas com mais frequência e ver como ele se compara ao restante dos itens da sua tabela.
Isso será útil se você puder gerar tráfego representativo em seu ambiente de teste ou mesmo no início ao liberar seu aplicativo. O monitoramento desses CloudWatch Contributor Insights pode ajudar a identificar possíveis problemas antes de você começar a executar o limite de 3000 RCU em uma única partição.
Conclusão
Neste artigo, demos uma espiada por trás da cortina sobre por que o DynamoDB pode parecer tão inflexível quando você começa a aprender. Vimos como o DynamoDB "muda para a esquerda" na escalabilidade, fazendo você considerar a escalabilidade durante a fase de design da tabela. Em seguida, vimos os três motivos pelos quais os bancos de dados relacionais enfrentam problemas em grande escala e as três decisões de design que o DynamoDB tem para evitar esses problemas. Por fim, analisamos duas áreas em que você pode ver problemas de desempenho com o DynamoDB.
O DynamoDB é uma ótima ferramenta, e você deve considerá-lo quando tiver um ajuste certo na sua arquitetura. Se você deseja um banco de dados com redimensionamento contínuo à medida que seu aplicativo cresce em popularidade, vale a pena aprender o DynamoDB e projetar sua tabela corretamente.
Os conceitos neste post são necessariamente compactados devido ao seu formato. Se você estiver interessado em saber mais sobre esse e outros tópicos relacionados, confira o excelente livro de Martin Kleppmann, Designing Data-Intensive Applications.
Créditos
- SQL, NoSQL, and Scale: How DynamoDB scales where relational databases don't, escrito originalmente por Alex DeBrie.
Posted on February 10, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.