Web Scraping mit Node.js

Christel
Posted on March 14, 2023

Artikel Quelle: Web Scraping mit Node.js

Web Scraping ist eine Technik, die häufig von Entwicklern und Data Scientists genutzt wird, um Daten von Websites zu extrahieren. Mit Node.js können Sie Web Scraping-projekte effektiv und einfach implementieren. In diesem Artikel werden wir einen Überblick über Web Scraping mit Node.js geben und Ihnen zeigen, wie Sie mit Node.js Web Scraping-Anwendungen entwickeln können.
Was ist Web Scraping?
Web Scraping ist ein prozess, bei dem Informationen von einer Website extrahiert und in einer strukturierten Form gespeichert werden. Diese Informationen können auf verschiedene Arten genutzt werden, wie zum Beispiel für Datenanalysen, Marktforschung, preisvergleiche oder zum Erstellen von Inhalten. Web Scraping kann manuell durchgeführt werden, aber dies ist ineffizient und zeitaufwendig. Mit der Automatisierung von Web Scraping mithilfe von programmen kann der prozess deutlich beschleunigt werden.
Web Scraping mit Node.js
Node.js ist eine Open-Source-plattform, die auf der JavaScript-Laufzeitumgebung aufbaut. Mit Node.js können Sie serverseitige Anwendungen mit JavaScript erstellen. Es bietet eine leistungsstarke ApI und viele Bibliotheken, die Ihnen helfen, schnell und einfach Web Scraping-Anwendungen zu erstellen.
Node.js eignet sich ideal für das Web Scraping, da es schnell und skalierbar ist. Darüber hinaus bietet es die Möglichkeit, asynchrone programmierung mit Callbacks, promises und Async / Await zu implementieren. Dies ist entscheidend, da das Scraping von Websites häufig asynchrone Aufgaben erfordert, um mit Verzögerungen und Fehlern umzugehen.
So entwickeln Sie eine Web Scraping-Anwendung mit Node.js
Um eine Web Scraping-Anwendung mit Node.js zu erstellen, müssen Sie zunächst die zu scrapende Website identifizieren. Sobald Sie die Website ausgewählt haben, müssen Sie die Struktur der Website analysieren, um zu verstehen, wie Sie die gewünschten Informationen extrahieren können.
Als nächstes müssen Sie eine HTTp-Anfrage an die Website senden, um die Website-Inhalte zu erhalten. Hierfür können Sie die http oder https-Module von Node.js verwenden. Mit diesen Modulen können Sie HTTp-Anfragen senden und die Serverantworten verarbeiten.
Wenn Sie die Antwort erhalten haben, müssen Sie den HTML-Inhalt der Website analysieren, um die gewünschten Informationen zu extrahieren. Hierfür gibt es viele Bibliotheken wie Cheerio, jsdom oder puppeteer, die Ihnen helfen können, HTML-Elemente zu analysieren und zu manipulieren.
Sobald Sie die benötigten Informationen extrahiert haben, können Sie diese in einer geeigneten Form speichern, wie zum Beispiel in einer Datenbank oder in einer Datei. Hierfür können Sie Bibliotheken wie MongoDB, MySQL oder SQLite verwenden.
Abschließend müssen Sie sicherstellen, dass Ihre Anwendung die Website in einem angemessenen Tempo und auf eine respektvolle Weise scrapped, um sicherzustellen, dass Sie nicht gegen die Nutzungsbedingungen der Website verstoßen.
Beispiel: Top 250 Filme mit Node.js scrapen
Hier ist ein Beispiel für Web Scraping mit Node.js:
Angenommen, Sie möchten Informationen über die Top 250 Filme auf IMDb sammeln.

Schritt 1: Machen Sie die Website https://www.imdb.com/chart/top/ auf.
Schritt 2: Sie können das folgende Skript verwenden, um die Titel, Bewertungen und Beschreibungen dieser Filme zu extrahieren:
const request = require('request');
const cheerio = require('cheerio');
const url = 'https://www.imdb.com/chart/top/';
request(url, function (error, response, html) {
if (!error && response.statusCode == 200) {
const $ = cheerio.load(html);
const movies = $('.lister-list tr').slice(0, 250);
movies.each((i, el) => {
const title = $(el).find('.titleColumn a').text().trim();
const rating = $(el).find('.imdbRating strong').text().trim();
console.log(`${i+1}. ${title} - ${rating}`);
});
}
});
In diesem Skript verwenden wir das request-Modul, um eine HTTP-Anfrage an die IMDb-Website zu senden und den HTML-Inhalt der Website zu erhalten. Wir verwenden dann das cheerio-Modul, um die HTML-Elemente der Website zu analysieren und die benötigten Informationen zu extrahieren.
Wir suchen nach jedem tr-Element in der tbody.lister-list und verwenden die find()-Methode, um die HTML-Elemente zu finden, die den Titel, die Bewertung und die Beschreibung jedes Films enthalten. Wir rufen dann die text()-Methode auf, um den Textinhalt dieser HTML-Elemente zu extrahieren und in den Variablen title, rating zu speichern.
Schließlich geben wir diese Informationen mit console.log() aus. Wenn Sie dieses Skript ausführen, sollten Sie eine Liste der Top 10 Filme auf IMDb mit ihren Titeln, Bewertungen und Beschreibungen erhalten.
Vergleich zwischen Node.js und Octoparse
Node.js und Octoparse sind beide leistungsfähige Tools für Web Scraping, aber sie haben unterschiedliche Vor- und Nachteile.
Node.js ist eine serverseitige plattform, die auf der JavaScript-Sprache basiert und es Benutzern ermöglicht, schnell und einfach Web Scraping-Anwendungen zu entwickeln. Es verfügt über eine große Anzahl von Bibliotheken, die von der Community erstellt wurden, und bietet eine skalierbare Architektur, die es Benutzern ermöglicht, effizient mit großen Datenmengen umzugehen. Ein weiterer Vorteil von Node.js ist die Unterstützung von asynchroner programmierung, die besonders nützlich ist, wenn es darum geht, mit vielen Websites gleichzeitig zu interagieren.
Auf der anderen Seite ist Octoparse ein visuelles Scraping-Tool, das es Benutzern ermöglicht, Websites zu durchsuchen und Daten zu extrahieren, ohne Code schreiben zu müssen. Es verfügt über eine intuitive Benutzeroberfläche und ist einfach zu bedienen, auch für Benutzer ohne programmierkenntnisse. Ein weiterer Vorteil von Octoparse ist, dass es eine Reihe von Vorlagen bietet, die Benutzer verwenden können, um bestimmte Arten von Daten zu extrahieren, wie z.B. produktinformationen, Bewertungen und Kontaktdaten.
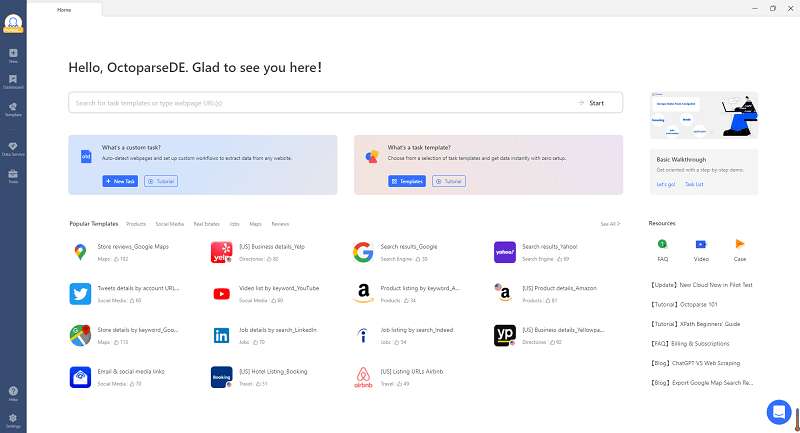
Beispiel: Top 250 Filme mit Octoparse scrapen
Vor dem Scraping sollte man die Ziel-URL vorbereiten. In disem Beispiel nehmen wir die URL https://www.imdb.com/chart/top/. Informationen über die Top 250 Filme auf IMDb sammeln.
Schritt 1 Downloaden und öffnen Sie Octoparse.
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise: Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen: Octoparse für Windows und MacOs
Schritt 2 Geben Sie die obige URL ein und Octoparse fängt an, die URL zu analysieren und automatisch alle Code der Seite zu überprüfen.

Schritt 3 Nach Auto-Detection sind alle Datenfeldern im unten angezeigt. Klicken Sie auf "Creat workflow" zu Erstellen eines Task-Workflows.

Schritt 4 Der Workflow rechts zeigt die Scraper Logik. Die extrahierten Daten auf der Seite sind in rot dargestellt und alle Datentitel sind nach Ihrem Wunsch umbenennenbar.

Schritt 5 Klicken Sie auf "Run", um den Task zu starten. Hier sind Device Mode und Cloud Mode zu wählen.
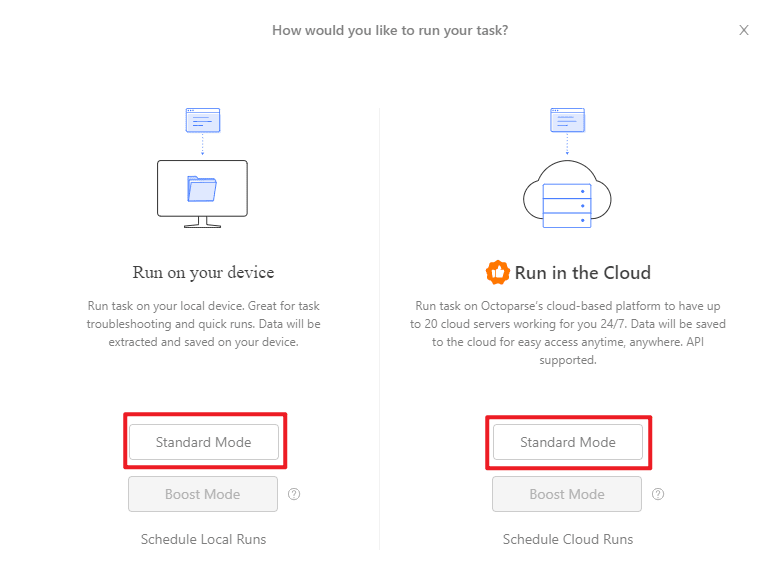
Schritt 6 Daten exportieren in Excel, CSV, HTML oder JSON. Zapier ist auch verfügbar in Cloud Mode.

Schritt 7 Hier ist ein Beispiel von Informationen der Top 250 Filmen aus IMDB.

Zusammenfassung
In Bezug auf die Geschwindigkeit und Genauigkeit des Scraping kann Node.js aufgrund seiner asynchronen Architektur schneller arbeiten als Octoparse, insbesondere bei der Verarbeitung großer Datenmengen. Node.js bietet auch mehr Flexibilität bei der Gestaltung von Scraping-Workflows und der Anpassung von Scraper-Code.
Auf der anderen Seite ist Octoparse besser geeignet, wenn Benutzer schnell und einfach Daten von einer einzelnen Website extrahieren möchten, ohne viel Zeit und Aufwand in die Entwicklung von Code zu investieren. Es ist auch eine gute Option für Benutzer, die keine programmierkenntnisse haben oder nicht die Zeit oder Ressourcen haben, um eine Web-Scraping-Anwendung von Grund auf neu zu entwickeln.
Insgesamt hängt die Wahl zwischen Node.js und Octoparse davon ab, welche Art von Web-Scraping-projekt Sie durchführen möchten und welche Fähigkeiten und Ressourcen Sie haben. Wenn Sie auf der Suche nach einer flexiblen, skalierbaren und leistungsfähigen plattform sind und über programmierkenntnisse verfügen, ist Node.js die bessere Wahl. Wenn Sie jedoch schnell und einfach Daten von einer einzelnen Website extrahieren möchten und keine programmierkenntnisse haben, ist Octoparse möglicherweise die bessere Option.
Posted on March 14, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related