BGP Graceful Restart, some inter-platform oddities, what to do with it

Nick Schmidt
Posted on March 8, 2020
Since most of NSX-T runs in a firewall mode of sorts, it's probably worthwhile to discuss on of the less well-known routing protocol features - Graceful Restart.
As published for BGP, IETF RFC 4724 outlines a mechanism for "preserving forwarding traffic during a BGP restart." This definition may be a little misleading, but that's mostly because of HOW the industry is leveraging Graceful Restart. Here are a few of the "normal use-cases" for BGP GR:
Cisco Non-Stop Forwarding and other similar technologies:
Cisco has developed another standard - NSF - that applies industry-generic methods for executing a BGP restart with forwarding continuity, with a twist. In many cases, multi-supervisor redundancy is a popular way of keeping your high-availability numbers up, with either a chassis switch running multiple supervisor modules or multiple devices bonded into a virtual chassis. In theory, these implementations get better availability numbers because they'll keep the main IP address reachable during software upgrades or system failures.
In my experience, this is great in campus applications, where client devices don't really have any routing/switching capability (like a cell phone) and where availability expectations are somewhat low (99%-99.99% uptime). However, in higher availability situations or ones running extensive routing protocol functionality, this appears to fall apart somewhat, where the caveats start to break the paradigm:
- ISSU caveats: You have to CONSTANTLY upgrade your routers because ISSU is typically only supported across 1 or 2 minor releases. If you have a "cold" cutover, i.e. with a major version upgrade, you'll see a pretty extensive outage (5-30 minutes long depending on hardware)
- Older implementations of a multi-supervisor chassis tend to have configuration sync issues, you need to CONSTANTLY test your failover capability (I mean, you should do that anyway...)
Just my 2 cents. But here's where Graceful Restart does its job: During a supervisor failover, the IP address of the routing protocol speaker is shared between supervisors, so when establishing a routing protocol adjacency, the speakers negotiate GR capability, along with tunable timers. Since the IP doesn't change, the greatest availability action would be to continue forwarding to a "dead" address until the adjacency is established, ensuring sub-second availability for a dynamic routing protocol speaker (except in the case of updating your gear...)
Firewalls:
Most firewall implementations are either Active-Active or Active-Standby, with shared IP addresses and session state tables. Well-designed firewall platforms use a generic method for sharing the state table, which includes (ideally) the session table, routing table, etc. ensuring that mismatched software versions do not introduce a disproportionate outage. The primary downside to this approach is that you don't have a good way to test your forwarding path (beyond Layer 2) so you should TEST OFTEN.
Now let's cover where you should NOT use Graceful Restart:
Any situation where the routing protocol speaker does not have a backup supervisor or any state mechanism. Easy, right?
NOPE. You have to enable Graceful Restart on speakers that have an adjacent firewall (or NSX-T Tier-0 gateway) to support the downstream failover.
RFC 4724 outlines two modes for Graceful Restart: Capable and Aware. Intuitively, GR Capable speakers should be stateful network devices, such as multi-supervisor chassis, firewalls, or NSX-T edges, and GR Aware devices should be stateless network devices, such as layer 3 switches.
The catch, however, is that not all devices support GR Awareness mode. For example, it IS supported in IOS 12, but provides caveats on what hardware has this capability.
So why does this matter? Well, Cisco illustrated it well in this NANOG presentation by stating that if an NSF-Capable advertising device fails, but there is no backup device sharing that same IP address, all traffic is dropped until the GR timers expire. Ouch. This is especially bad given some defaults:
- RFC 8538 Recommendation: 180 seconds
- Palo Alto: 120 seconds
- Cisco: 240-300 seconds
- VMWare NSX-T: 600 seconds?!?!?!?
Now that's pretty weird. If we fetch from VMWare's VVD 5.0.1, it says the following:
NSXT-VISDN-038 Do not enable Graceful Restart between BGP neighbors. Avoids loss of traffic. Graceful Restart maintains the forwarding table which in turn will forward packets to a down neighbor even after the BGP timers have expired causing loss of traffic.
Coupled with the recommendation for Tier-0 to be active-active (remember, as I stated before, stateless devices do NOT need GR):
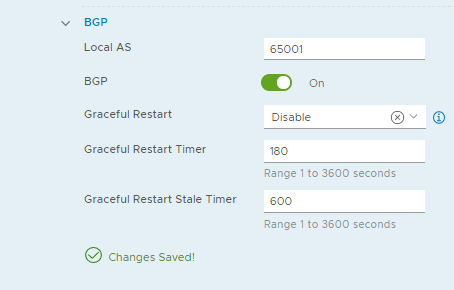
Oddly, it did not warn me about needing to restart the session. Let's find out why:
bgp-rrc-l0#show ip bgp summaryBGP router identifier 10.6.0.0, local AS number 65000BGP table version is 84, main routing table version 847 network entries using 819 bytes of memory11 path entries using 572 bytes of memory14/6 BGP path/bestpath attribute entries using 1960 bytes of memory2 BGP AS-PATH entries using 48 bytes of memory0 BGP route-map cache entries using 0 bytes of memory0 BGP filter-list cache entries using 0 bytes of memoryBGP using 3399 total bytes of memoryBGP activity 102/93 prefixes, 264/247 paths, scan interval 60 secsNeighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd10.6.0.240 4 65000 143031 142962 84 0 0 14w1d 210.6.0.241 4 65000 143036 142962 84 0 0 14w1d 110.6.99.1 4 64900 330104 280526 84 0 0 1d17h 110.6.200.2 4 65001 178250 174230 84 0 0 1w0d 3FD00:6::240 4 65000 310833 578924 84 0 0 14w1d 0FD00:6::241 4 65000 301493 578924 84 0 0 14w1d 1
Note that for GR to be modified, the BGP session must re-start, so if this was a production environment with equipment that supports GR ( *sigh* ) you would want to get into the leaf switch and perform a hard restart of the BGP peering.
VMWare's VVD recommendation here is pretty sound, as with most devices the GR checkbox is a global one, so you'd want to buffer between GR/Non-GR with a dedicated router (it's just a VM in NSX's case!), keeping in mind most leaf switches will have GR enabled by default.
Oddly enough, Cisco's Nexus 9000 platform (flagship datacenter switches) default to graceful restart capable. My recommendations (to pile on with the VVD) on this platform would be to:
- Set BGP timers to 4/12
- Set GR timers to 120/120 or lower (they're fast switches, so I chose 30/30)
- Under BGP, configure graceful-restart-helper to make the device GR-Aware instead of GR-Capable
Obviously, the VVD will adequately protect your infrastructure to issues like this, but I think it's unlikely you'll have NSX-T as the only firewall in your entire datacenter.
Posted on March 8, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.