Kubernetes for Data Science

Napptive
Posted on February 28, 2023

Are you a data scientist? If so, are you tired of devoting precious time to tasks that have nothing to do with models? Are you overwhelmed by the complexity of moving your models to the production environment? If your answer is a resounding YES, we’ve got your back! In this article, we explain how to leverage Kubernetes for data scientists plus a really easy way to use Kubernetes in data science projects – without having to waste any more time learning and configuring tools unrelated to data models or machine learning.
Kubernetes for data scientists
Data science projects (very much like most projects) face two distinct stages: development and production. In this particular case, as Chip Huyen pointed out in a very enlightening article, the differences remain mainly in the scale and the statefulness. During development, you usually have one instance that can keep running forever. When moving the project to production, you need to provide a mechanism for autoscaling, as well as a way to persist data and state across dynamically changing instances.
You may have heard – or even experienced – that Kubernetes can help both with scaling up and down, and with providing ways for the instances to communicate and store data/state… if its complexity wasn’t such a barrier. But don’t despair. Let’s see all the reasons why Kubernetes is the way to go, and how you can avoid all the excruciating configuration it requires.
Benefits of Kubernetes for data science
Kubernetes (aka K8s) is an orchestration tool. This means that it’s able to create and destroy instances of an application according to demand over a cluster of machines. In fact, what it runs aren’t exactly instances, but containers. A container is a running instance of an application, together with its dependencies and configuration, packaged and isolated from other applications running on the same machine. The beauty of using containers is that you can wrap your development environment and send it to production as is. You don’t need to rewrite your code to a different language, and you can keep using the same dependencies.
In addition, given that the environment is preserved between different people and points in time, experiments are reproducible, which is key to data science. Due to the isolation between containers, you can use different versions of the same tool for different steps in your pipeline, just by breaking up the app into several microservices. This simplifies the development environment because you’re not restricted by a dependency’s version for other uses.
These microservices can be automatically scheduled to the best-fitting devices. Kubernetes gives you infrastructure abstraction because it’s able to manage the underlying infrastructure. It can also spin up new instances when heavy computational loads occur and then shut them down when they are no longer needed. Both features lead to the efficient use of resources and make a data scientist happy.
What’s more, you could even get access to cutting-edge equipment at a low cost if you choose to run your models on a public cloud. Investing in private machines is costly because they get outdated over time and are expensive to maintain. K8s has become the de facto standard of the cloud, and so all cloud vendors offer Kubernetes support. You could choose the best fit for you and even have some cloud flexibility, as it would be relatively easy to change vendors or make use of multi or hybrid cloud environments.
Of course, it’s not all a bed of roses. The main drawback to using such a powerful tool is, obviously, its complexity. Full-stack data scientists are well aware of this and have surely spent many hours tweaking YAML files. But, we’ve got something in store that really simplifies the use of Kubernetes, and it’s called Napptive.
How to use Kubernetes in data science projects
Napptive is a cloud computing platform that abstracts an underlying Kubernetes, so that you don’t have to spend much time configuring your workloads. You can still access some Kubernetes configuration in case you need it, but its main purpose is to let you start running your apps in no time. We’ll show you how by launching R Studio from the tool’s catalog.
First, you need to login into Napptive at https://playground.napptive.dev. If you don’t have an account yet, you can easily log in for free with your email or your GitHub or Google account.

Once you’re in, you have to click the catalog icon.

Search for R, you’ll find it as rstudio.
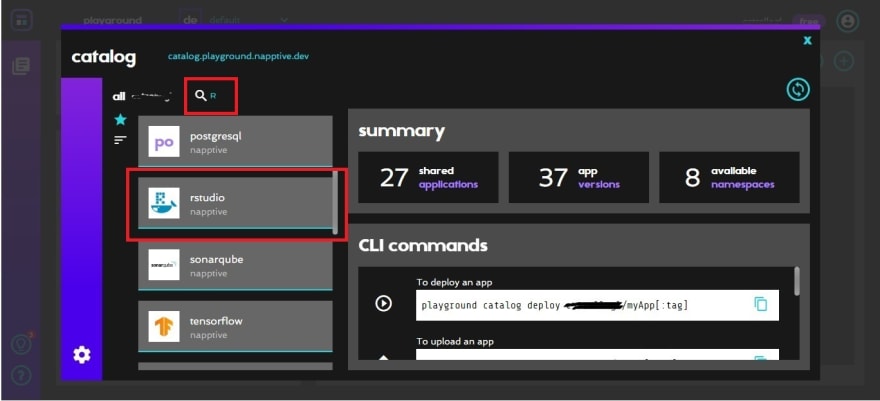
When you click the card, it will open a box with more information about the app image. Click “Deploy”.

It will ask in which environment you want to deploy the app. If you’re using the free account, you have just one, so click “Deploy” again. Then, “yes, deploy” to confirm.
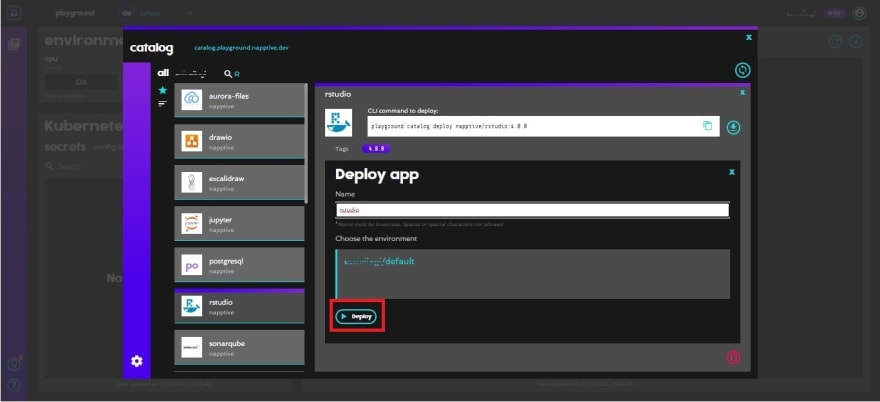

After that, you can close the catalog to restore the playground view

You’ll see rstudio status as a colored box. It’ll be yellow for a while.
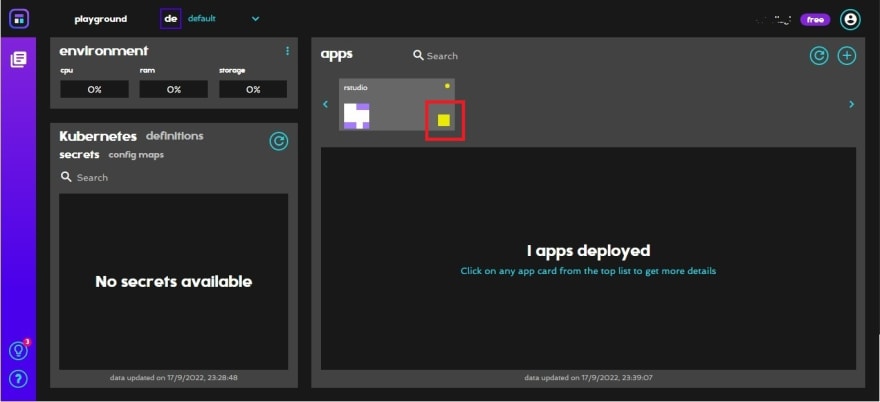
Once it’s ready, the box will become green.

You can click on the box to see more information about the application. There you’ll find the path and a button to access the endpoint and open the app.
And that’s it! In this demonstration, we’ve used an existing app from the catalog, but you can certainly create and upload your own applications to Napptive. You can refer to the documentation to learn how.
If you want to propel your development, why not try our playground? It’s free, simply sign up and get started!

Posted on February 28, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related