Exploratory Analysis on GitHub Data

Ferdinand Mütsch
Posted on April 11, 2019

Background
A few days ago, I wrote a crawler (with NodeJS and Sequelize) that fetches publicly available data from GitHub's GraphQL API. More precisely, I downloaded information about users, repositories, programming languages and topics.
After running the crawler for a few days, I ended up with 154,248 user profiles, 993,919 repositories and 351 languages, many of which I had never heard of (e.g. did you know about PogoScript?). However, although my MySQL database is already 953 MB in size with only these data, I barely crawled 0.4 % of all user profiles (~ 31 million).
The first (less extensive) version of my database – which I performed the following analyses on – looked like this.
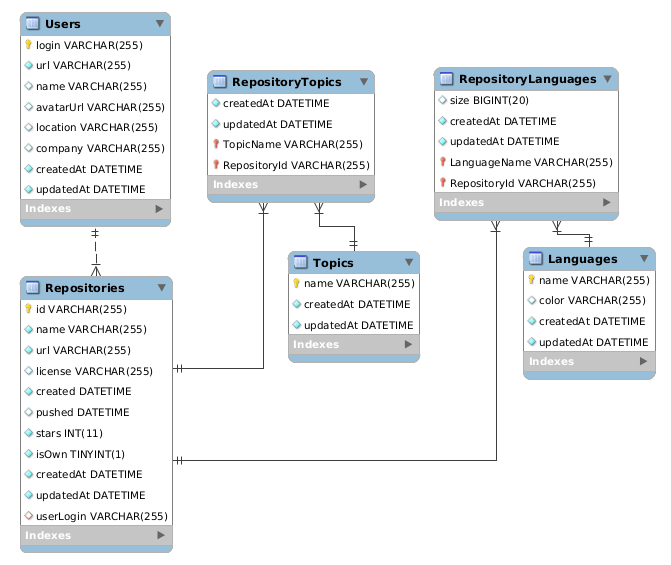
While one could argue that the data I collected is not of a representative sample size, I still wanted to do some data analysis on it – just for fun.
Analyses
To perform the analyses, I used Python 3 with Pandas and Matplotlib.
import apriori
import pymysql
import pandas as pd
import matplotlib.pyplot as plt
from sqlalchemy import create_engine
%matplotlib inline
pymysql.install_as_MySQLdb()
sql_engine = create_engine('mysql://user:heheyouwish@localhost:3306/github_data', echo=False)
connection = sql_engine.raw_connection()
Most popular programming languages
One of the first and most obvious thing to check (for the sake of brevity I'll skip basic data set statistics like count, mean, variance, ...) is which languages are most widely used.
df_top_langs = pd.read_sql_query('''
select LanguageName, count(LanguageName) as count from RepositoryLanguages
group by LanguageName
order by count(LanguageName) desc
limit 10;
''', con=connection)
df_top_langs.set_index('LanguageName').plot.bar(figsize=(12,8))
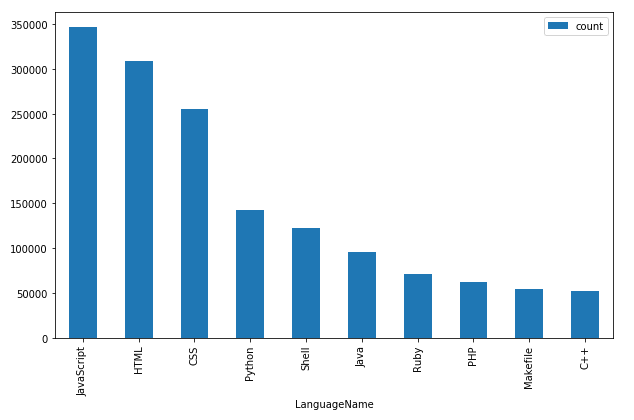
Not too surprisingly, the typical web stack consisting of JavaScript, HTML and CSS, is among the most popular programming languages, according to how often they appear in repositories.
Least popular programming languages
A little more interesting is to see, which programming languages occur least.
df_last_langs = pd.read_sql_query('''
select LanguageName, count(LanguageName) as count from RepositoryLanguages
group by LanguageName
order by count(LanguageName) asc
limit 10;
''', con=connection)
print(df_last_langs)
Here are the results. Have you heard of any one of them? I didn't.
LanguageName count
0 Nit 1
1 Myghty 1
2 Public Key 1
3 DCPU-16 ASM 1
4 TI Program 1
5 Genie 1
6 Ox 1
7 PogoScript 1
8 Cirru 1
9 JFlex 2
User Skills
Let's analyze the users' skills in terms of languages. I decided to consider a user being "skilled" in a certain language if at least 10 % of her repositories' code is in that language.
N = int(1e7)
MIN_SUPP = .0005
MIN_CONF = .45
MIN_LANG_RATIO = .1
df_skills = pd.read_sql_query(f'''
select RepositoryLanguages.LanguageName, RepositoryLanguages.size, Users.login, Users.location from RepositoryLanguages
left join Repositories on Repositories.id = RepositoryLanguages.RepositoryId
right join Users on Users.login = Repositories.userLogin
limit {N}
''', con=connection)
df_skills = df_skills.merge(pd.DataFrame(df_skills.groupby('login')['size'].sum()), how='left', on='login').rename(columns={'size_x': 'size', 'size_y': 'totalSize'})
df_skills = df_skills[df_skills['totalSize'] > 0]
df_skills['sizeRatio'] = df_skills['size'] / df_skills['totalSize']
print(f"{df_skills['login'].unique().size} users")
print(f"{df_skills['LanguageName'].unique().size} languages")
# Output:
# 130402 users
# 351 languages
Association Rules
What I wanted to look at is combinations of different skills, i.e. languages that usually occur together as developer skills. One approach to get insights like these is to mine the data for association rules, e.g. using an algorithm like Apriori (as I did). The implementation I used was asaini/Apriori.
user_langs = df_skills[df_skills['sizeRatio'] >= MIN_LANG_RATIO].groupby('login')['LanguageName'].apply(set).values
items1, rules1 = apriori.runApriori(user_langs, MIN_SUPP, MIN_CONF)
rules1 = sorted(rules1, key=lambda e: e[1], reverse=True)
print(rules1)
Output:
[((('ShaderLab',), ('C#',)), 0.904),
((('Vue',), ('JavaScript',)), 0.671277997364954),
((('Vue', 'CSS'), ('JavaScript',)), 0.656140350877193),
((('GLSL',), ('C#',)), 0.625),
((('CMake',), ('C++',)), 0.6229508196721312),
((('CSS',), ('JavaScript',)), 0.5807683959192532),
((('Tcl',), ('Python',)), 0.5658914728682171),
((('Kotlin',), ('Java',)), 0.5655375552282769),
((('ASP',), ('C#',)), 0.5488215488215488),
((('Vue', 'HTML'), ('JavaScript',)), 0.5404411764705882),
((('CoffeeScript',), ('JavaScript',)), 0.5339578454332553),
((('CSS', 'PHP'), ('JavaScript',)), 0.5116117850953206),
((('Elm',), ('JavaScript',)), 0.4951923076923077),
((('CSS', 'HTML'), ('JavaScript',)), 0.4906486271388778),
((('Smarty',), ('PHP',)), 0.4788732394366197),
((('TypeScript',), ('JavaScript',)), 0.4739540607054964),
((('CSS', 'C#'), ('JavaScript',)), 0.464926590538336),
((('Groovy',), ('Java',)), 0.4604651162790698)]
The left part of each row is a tuple of tuples of programming languages that represent an association rule. The right part is the confidence of that rule.
For example:
Read ((('ShaderLab',), ('C#',)), 0.904) as "90 % of all people who know ShaderLab also know C#".
The results reflect common sense. For instance, the rule that developers, who know VueJS, also know JavaScript seems to make sense, given that VueJS is a JavaScript framework. Analogously, CMake is a common build tool for C++, etc. Nothing too fancy here, except for that I didn't know about ShaderLab and GLSL.
Locations
Let's take a look at where most GitHub users are from. Obviously, this only respects profiles where users have set their locations.
df_locations = df1.reindex(['location'], axis=1).groupby('location').size()
df_locations = df_locations.sort_values(ascending=False)[:20]
df_locations.plot.bar(figsize=(12,8))
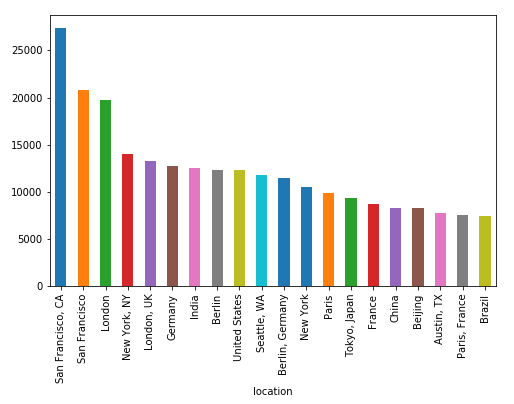
Clearly, San Francisco seems to be the most popular city for developers (or at least for those who are active on GitHub).
Skills by location
To take this a step further, let's take a look at which skills users tend to have in what cities.
def language_replace(df):
df = df.copy()
# Little bit of manual cleaning
replace = {'San Francisco': 'San Francisco, CA',
'Berlin': 'Berlin, Germany',
'New York': 'New York, NY',
'London': 'London, UK',
'Beijing': 'Beijing, China',
'Paris': 'Paris, France'}
for (k, v) in replace.items():
if isinstance(df, pd.DataFrame):
if k in df.columns and v in df.columns:
df[k] = df[k] + df[v]
df = df.drop([v], axis=1, errors='ignore')
else:
if k in df.index and v in df.index:
df[k] = df[k] + df[v]
#df = df.drop([v], axis=1)
del df[v]
return df
langs_by_loc = {}
for l in df_locations.index:
langs_by_loc[l] = df1[df1['location'] == l][['LanguageName']].groupby('LanguageName').size()
df_loc_langs = pd.DataFrame.from_dict(langs_by_loc).fillna(0)
df_loc_langs = language_replace(df_loc_langs)
df_loc_langs = df_loc_langs.T
df_loc_langs = df_loc_langs.drop([c for c in df_loc_langs.columns if c not in df_top_langs['LanguageName'].values], axis=1)
df_loc_langs = (df_loc_langs.T / df_loc_langs.T.sum()).T # normalize heights
df_loc_langs.plot.bar(stacked=True, figsize=(16,10))
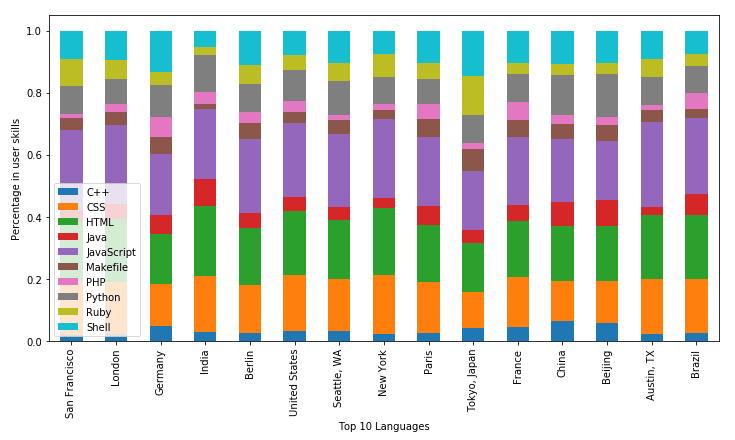
Look like there are no real outliers in the distribution of developer skills between different cities of the world. Maybe you could say that, e.g., Indians like web frontends a little more than command-line hacking.
Skills: Karlsruhe vs. the World
While an overview is cool, I found it even more interesting to specifically compare between to cities. So in the following chart I compare language-specific programming skills in Karlsruhe (the city where I live and study) to the rest of the world's average.
df_ka = df1[df1['location'] == 'Karlsruhe'][['LanguageName']].groupby('LanguageName').size()
df_ka = pd.DataFrame(df_ka, index=df_ka.index, columns=['Karlsruhe']) / df_ka.sum()
df_world = pd.DataFrame(df_loc_langs.mean(), index=df_loc_langs.mean().index, columns=['World'])
df_compare = df_world.merge(df_ka, how='left', left_index=True, right_index=True)
ax = df_compare.plot.barh(title='Languages: World vs. Karlsruhe', legend=True, figsize=(10,5))
ax.set_xlabel('Percentage (Top 10)')
ax.set_ylabel('Programming Language Skills')
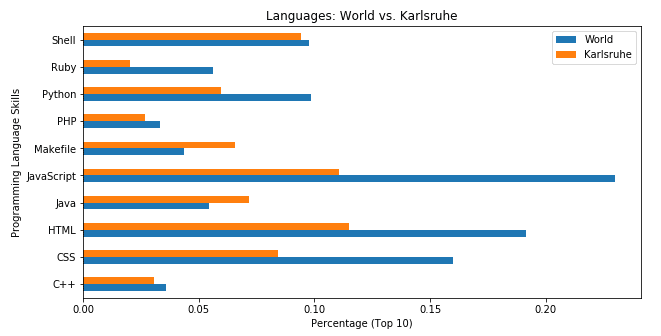
These results are a bit surprising to me. Clearly, Karlsruhe-based developers seem to dislike JavaScript compared to the world. However, this is different from what I experienced in several student jobs and internships here.
Project Tech Stacks
Last but not least, let's apply Apriori once more, but this time in a slightly different way. Instead of looking at user skills, let's look at languages that occur together on a per-repository basis. And instead of trying to find rules, let's only look at frequent item sets (which are the basis for rules). My expectation was to get back sets of commonly used tech stacks.
N = int(1e7)
MIN_SUPP = .0005
MIN_CONF = .45
MIN_LANG_RATIO = .1
df_stacks = pd.read_sql_query(f'''
select LanguageName, size, RepositoryId from RepositoryLanguages
order by RepositoryId
limit {N}
''', con=connection)
df_stacks = df_stacks.merge(pd.DataFrame(df_stacks.groupby('RepositoryId')['size'].sum()), how='left', on='RepositoryId').rename(columns={'size_x': 'size', 'size_y': 'totalSize'})
df_stacks = df_stacks[df_stacks['totalSize'] > 0]
df_stacks['sizeRatio'] = df_stacks['size'] / df_stacks['totalSize']
print(f"{df_stacks['RepositoryId'].unique().size} repositories")
print(f"{df_stacks['LanguageName'].unique().size} languages")
# Output:
# 853114 repositories
# 351 languages
repo_langs = df_stacks[df_stacks['sizeRatio'] >= MIN_LANG_RATIO].groupby('RepositoryId')['LanguageName'].apply(set).values
items2, rules2 = apriori.runApriori(repo_langs, MIN_SUPP, MIN_CONF)
itemsets2 = sorted(list(filter(lambda i: len(i[0]) > 2, items2)), key=lambda i: i[1], reverse=True)
print(itemsets2)
Output:
[(('CSS', 'JavaScript', 'HTML'), 0.04360026913167525),
(('CSS', 'JavaScript', 'PHP'), 0.0045574213997191465),
(('Ruby', 'CSS', 'HTML'), 0.004456614239128651),
(('TypeScript', 'JavaScript', 'HTML'), 0.0042034241613664765),
(('TypeScript', 'HTML', 'CSS'), 0.0035024627423767517),
(('Python', 'JavaScript', 'HTML'), 0.002962089474560258),
(('Python', 'HTML', 'CSS'), 0.002769852563666755),
(('Ruby', 'JavaScript', 'HTML'), 0.0022400288824236856),
(('JavaScript', 'HTML', 'PHP'), 0.0022154131804190294),
(('Ruby', 'CSS', 'JavaScript'), 0.0021532878372644217),
(('CSS', 'HTML', 'PHP'), 0.0019915275098052547),
(('JavaScript', 'Objective-C', 'Java'), 0.0018614159420663593),
(('CSS', 'JavaScript', 'Python'), 0.0017992905989117516),
(('Python', 'JavaScript', 'Objective-C'), 0.0017735027206211597),
(('Python', 'JavaScript', 'Java'), 0.001508590879999625),
(('CSS', 'JavaScript', 'TypeScript'), 0.0014745977677074812),
(('Python', 'Objective-C', 'Java'), 0.0014066115431231934),
(('Python', 'JavaScript', 'Objective-C', 'Java'), 0.0013222148505358019),
(('Vue', 'CSS', 'JavaScript'), 0.0012554008022374501)]
Here, the left side is sets of frequently occurring combinations of languages. The right side is the set's support, which is the relative occurrences of that set among the whole data set.
Obviously, many of these are actually common "tech stacks" and almost all of them are web technologies. I guess GitHub is most popular among web developers.
Conclusion
There is a lot of more complex analyses that could be might on rich data like this and probably tools like BigQuery are better suitable than Pandas, operating on a tiny sample. However, I used this little project to improve my EDA skills and hopefully give you guys an interesting article to read. Let me know if you like it!---
Originally published at muetsch.io
Posted on April 11, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related