Web Scrapping con NodeJS

Anartz Mugika Ledo
Posted on August 18, 2020
En este nuevo artículo, vamos a trabajar con Node aplicando la técnica “Web-Scrapping”
0.- ¿Qué es?
El “Web-scrapping” se refiere a la recopilación de información de un sitio web a través de scripts automatizados. Esto va a facilitarnos el proceso de recopilación de grandes cantidades de datos de sitios web donde no se ha definido ninguna API oficial.
1.- ¿En qué consiste?
El “Web-scrapping” se puede dividir en dos pasos principales: obtener el código fuente HTML del sitio web a través de una solicitud HTTP o mediante un navegador sin cabeza, y analizar los datos sin procesar para extraer solo la información que nos interesa en un formato utilizable.
2.- Para qué sirve el scraping
Estas son algunas de las utilidades más habituales para las que usamos esta técnica:
- Agregadores de contenido
- Reputación online
- Caza de tendencias (cool hunting)
- Optimización de precios
- Monitorización de la competencia
- Optimización ecommerce
- Google Search Analysis
3.- Advertencia antes de empezar a extraer datos
¡Tener cuidado! El “Web scrapping”va en contra de los términos de servicio de la mayoría de los sitios web. Nuestra dirección IP puede ser prohibida en un sitio web si aplicamos la técnica con demasiada frecuencia o de manera maliciosa.
Por eso es importante no abusar de ello y no hacerlo con fines maliciosos.
4.- Preparativos del proyecto
Antes de empezar a trabajar con el proyecto, tenemos que tener instalado:
- NodeJS
- NPM
Si no lo tenemos, acudimos a la página https://nodejs.org/en/ y seguimos las indicaciones para su descarga e instalación. Es muy sencillo.
Una vez que ya tenemos lo necesario para trabajar accedemos al terminal y dentro el creamos un nuevo directorio en el que vamos a trabajar.
mkdir web-scrapping && cd web-scrapping
Ahora creamos el fichero package.json, que será el manifiesto de nuestro proyecto que servirá para almacenar la información más relevante de nuestro proyecto como nombre, descripción, dependencias,…
npm init -y
Modificamos el package.json para añadirle la descripción, las palabras clave (keywords) y el autor, quedará de la siguiente manera:
Creamos el ficheros index.js que será donde vamos a ejecutar la operación para extraer la información e instalamos las dependencias que vamos a necesitar para trabajar con ello.
npm install request request-promise cheerio objects-to-csv
Las librerías que instalamos harán lo siguiente:
- request / request-promise : Para traer la información que queremos descargar.
- cheerio: Para manipular y seleccionar la información que queremos extraer únicamente.
- objects-to-csv: Para guardar la información en un fichero CSV después de obtener lo que deseamos.
5.- Empezando a hacer Scrapping
Vamos a trabajar con la web que nos brinda información de las estadísticas del ciclismo mundial llamada Pro Cycling Stats.
Lo que vamos a querer obtener concretamente es la información del ranking UCI PRO TOUR de la clasificación individual de los ciclistas.
Por lo tanto, vamos a trabajar con esta URL:
PCS Ranking Individual
_Summation of PCS points over a 12-month + 2 weeks overlap period. Races are counted once. After the finish of a stage…_www.procyclingstats.com
Cuya página tendrá esta apariencia:
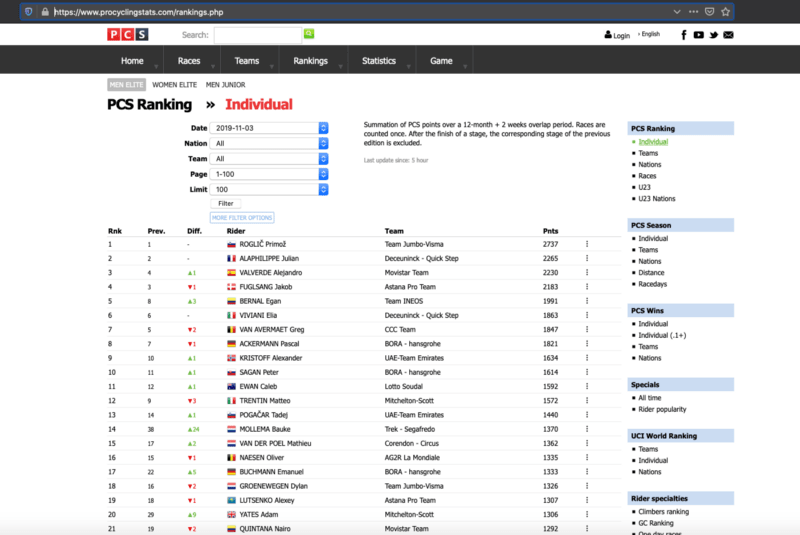
Realizamos mediante request-promise una solicitud HTTP en la URL mencionada.
Si ejecutamos y visualizamos el log de salida, nos da toda la información de esa página.
Ya tenemos el primer paso en el que somos capaces de extraer la información de una URL concreta y descargar todo su código HTML. Todo lo que se ha visualizado aquí es como si hiciesemos en el navegador “click derecho” en la página y seleccionasemos “Ver código fuente de la página”.
6.- Seleccionando la información que deseamos extraer
Ahora que ya hemos conseguido extraer la información, vamos a seleccionar la que queremos obtener y para saber lo que tenemos que obtener, podemos hacer uso de las herramientas de desarrollo que nos proporcionan navegadores como Firefox o Google Chrome.
Para acceder a esas herramientas, tanto en uno como en otro, pulsamos click derecho sobre cualquier apartado de la web y seleccionamos “Inspeccionar elemento” (Firefox) ó “Inspeccionar” (Chrome).
A continuación os muestro la parte que queremos “extraer” para obtener los datos que queremos, en este caso la información de:
- Posición en el ranking.
- Ciclista.
- URL con la información principal del ciclista.
- Equipo al que pertenece.
- Puntos obtenidos.

Ahora que ya tenemos localizado el apartado que queremos obtener para tratar sus datos, vamos a hacer referencia a ese apartado de la tabla y vamos a obtener todas las filas de esa tabla. Vamos a hacer referencia dentro de la tabla a todos los “tr”.
Por lo tanto, nos quedaría algo de este estilo:
Como véis, después de asignar a la constante el extracto con el que queremos trabajar, pones la orden la orden “debugger” y pulsamos estando en Visual Studio code y ese fichero seleccionado “F5” que sirve para ejecutar en modo debugger.
En el momento que se ejecuta, si os fijáis en la siguiente imagen, podéis apreciar que el cursor amarillo está parado en la línea de debugger.

Gracias a esta parada, podemos ir viendo la información que se ha ido almacenando en las constantes, variables anteriores y demás.
Lo que nos interesa en este momento es ver todos los nodos que tenemos dentro de la constantes “rankingTable”. Poniendo el cursor veremos que tenemos hasta un total de 100, que casualmente son los ciclistas que aparecen en la clasificación. Vamos paso a paso correctamente.
7.- Seleccionar los datos por ciclista deseados
Ahora que ya tenemos dentro de la constante los nodos con la información de los ciclistas, lo que tenemos que hacer es recorrerlos uno por uno y para hacer esto debemos de usar la función “each”.
Vamos a implemenarla y dentro vamos a mostrar el log en formato texto con todo el contenido de las 7 columnas que tenemos por fila.
Ejecutamos modo debugger (F5) y podemos ver como nos aparece la información de los ciclistas, fila a fila en la consola:

Ahora lo que nos queda es extraer los valores que queremos individualmente y almacenarlo en un objeto para añadirlos en un array y tener toda la información a mano para poder guardarla en un fichero CSV, que será el último paso que haremos.
Para seleccionar los elementos, en este caso, dentro del nodo tenemos 7 nodos hijos como podemos ver en esta imagen.
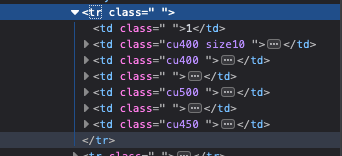
La información que tendremos en cada uno, será la siguiente. Así sabremos que tenemos que usar y que posición de los hijos tenemos que seleccionar.
- Ranking Actual.
- Ranking Previo a la actualización.
- Diferencia de puestos entre ranking actual / anterior.
- Ciclista.
- Equipo.
- Puntos totales
- No hay nada de información.
Como hemos mencionado anteriormente, lo que queremos extraer es el ranking actual (1), información del ciclista (4) como es el nombre y enlace a su información más detallada, equipo (5) y puntos totales (6).
Para hacer esto, como queremos seleccionar los hijos del elemento con el que estamos trabajando, vamos a usar el selector “nth-child(posicion)” para seleccionar el que queremos utilizar y lo vamos a hacer refiriéndonos al elemento “td”
Quedará de la siguiente manera:
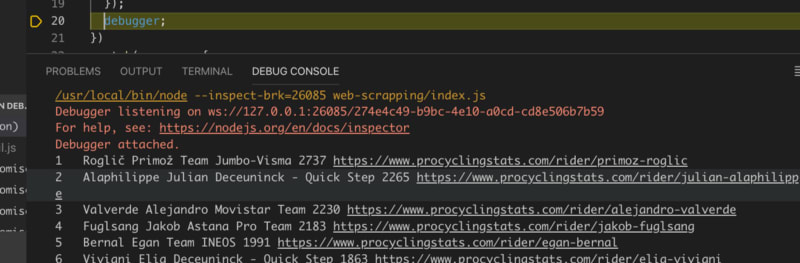
Si ejecutamos, ya tendremos la información “limpia” con lo que queremos únicamente:
8.- Almacenar en una lista de objetos
Ahora que ya tenemos los datos que queremos guardar, tenemos que almacenarlo en una lista de objetos para que al final de este artículo podamos crear un fichero CSV con esa información y tengamos un backup de lo que hemos descargado, para hacer uso de esa información.
Añadimos un array al inicio del script y dentro del each almacenamos como objeto dentro de esa lista añadiendo las propiedades necesarias.
Como veís, ya tenemos todo almacenado en una lista con los items del ranking.
Si ejecutamos el modo debugger y ponemos el cursor encima de rankingItems dentro del each de la tabla del ranking, podremos ver que tiene 100 elementos, que es la cantidad de ciclistas que aparecen en el ranking.
9.- Guardar la información en un fichero CSV
Ahora que ya tenemos toda la información deseada, lo único que nos queda es hacer una copia para no tener que andar descargando una y otra vez la información.
Creamos una función y guardamos en el disco lo que hemos almacenado en el array.
El resultado que tendremos en el fichero CSV será el siguiente:
El resultado lo encontraremos en el siguiente repositorio:
Anartz Mugika Ledo / scapping-uci-pro-tour-riders-ranking
_Ejemplo de Scrapping de la tabla de clasificación del ranking actual. Artículo escrito en Medium:_gitlab.com
By Anartz Mugika Ledo🤗 on .
Exported from Medium on August 18, 2020.
Posted on August 18, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.