
Adam Furmanek
Posted on September 26, 2023
How to Optimize SQL Queries With ChatGPT and Metis
Machine Learning is the thing! Let’s see how we can optimize queries with ChatGPT and other online solutions, and how Metis can help even better.
Introduction
We played with IMDb data in Unlocking IMDb Data With Metis for Awesome Database Optimization Insights . We saw how to improve queries using Metis, and how to configure our database to get best possible performance. Let’s see if ChatGPT can do the same. I’m using ChatGPT May 24 version available for free.
We are going to take each query and ask ChatGPT how to improve it. We’ll then measure the performance before and after the suggestions to see if it’s worth doing that.
For a given actor, find their latest movies
For each case I provide a link to the discussion with ChatGPT. Here is the first one.

Let’s try it now. I’m restarting my database and running the initial query a few times to get buffers filled and best result which is 4.8 seconds. Let’s now take improved query as specified by ChatGP:
SELECT TB.tconst
FROM name_basics AS NB
LEFT JOIN title_principals AS TP ON TP.nconst = NB.nconst
LEFT JOIN title_basics AS TB ON TB.tconst = TP.tconst
WHERE NB.nconst = 'nm1588970' -- Apply filtering before joining
ORDER BY TB.startyear DESC
LIMIT 10
You can see that I’m taking tconst only. Unfortunately, the execution time is the same (4.8 seconds). ChatGPT didn’t improve the query in this case. Obviously, I could add an index and ChatGPT even mentioned columns nconst and tconst. However, it also claimed that I should index startyear which I use in filtering, but that is not true at all. I order based on the column. Anyway, let’s ask how to configure indexes:

Let’s create these indexes and see the timings. It took nearly 4 minutes to create indexes. Running the query afterwards took 0.1 second. Clearly an improvement. Execution plan shown by Metis indicates that we used two indexes: idx_title_principals_nconst and idx_title_basics_tconst:

However, if we configure the index indicated by Metis:
CREATE INDEX IF NOT EXISTS title_principals_nconst_idx ON imdb.title_principals(nconst) INCLUDE (tconst);
We get the following plan:

We get the same query performance, but with fewer indexes.
For a given actor, find their ten most highly rated films
Let’s take another query and ask ChatGPT:

ChatGPT didn’t provide a query. Let’s ask for it:

Let’s try it out. The original query was running in 4.9 seconds. I tried the one suggested by ChatGPT
SELECT TB.tconst, TR.tconst -- Replace column1 and column2 with the actual column names needed
FROM name_basics AS NB
JOIN title_principals AS TP ON TP.nconst = NB.nconst
JOIN title_basics AS TB ON TB.tconst = TP.tconst
JOIN title_ratings AS TR on TR.tconst = TP.tconst
WHERE NB.nconst = 'nm1588970'
ORDER BY TR.averagerating DESC, TR.numvotes DESC
LIMIT 10;
This query has the same execution time. However, it changes the output! It uses INNER JOIN instead of a LEFT JOIN which results in returning just one row instead of two.
Based on the change above, it seems risky to use ChatGPT to optimize the query.
Find the ten top rated films with some number of votes

We can see that ChatGPT suggested a query that is exactly the same as the one I provided. You can verify with execution plans that there is no difference in the plan. Let’s see what indexes it would propose:

We can see this is the same index as the one Metis suggested.
Given two people, list what movies they appeared in together
Let’s carry on with the following:
Nothing big this time. Let’s ask for indexes:

We can see this is exactly the same index that Metis suggests.
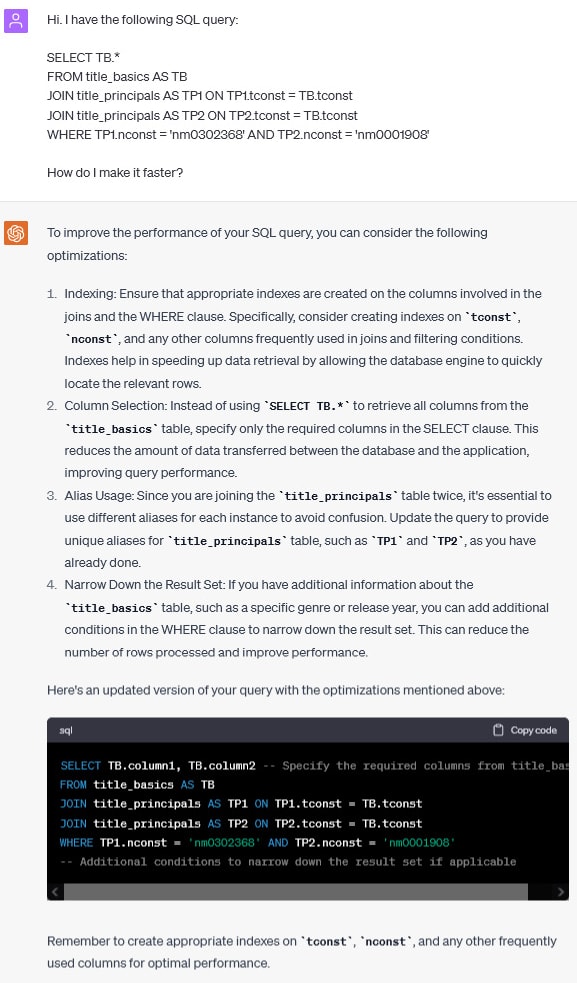
List all of the cast and crew in a given movie
Let’s do something fancier now.

Nothing specific yet. We can see ChatGPT suggests getting rid of OR conditions and using UNION instead. Let’s see if ChatGPT can suggest a better query.

Notice that ChatGPT didn’t realize that we don’t need the title_basics table. When it comes to the performance, my query works in around 86 seconds, ChatGPT’s one works in 84. Not much better.
Let’s see if we can hint ChatGPT to ignore the table:

Cool, ChatGPT figured out what we mean. However, the new query doesn’t work faster. It’s the same performance. Let’s see if UNION can do better:
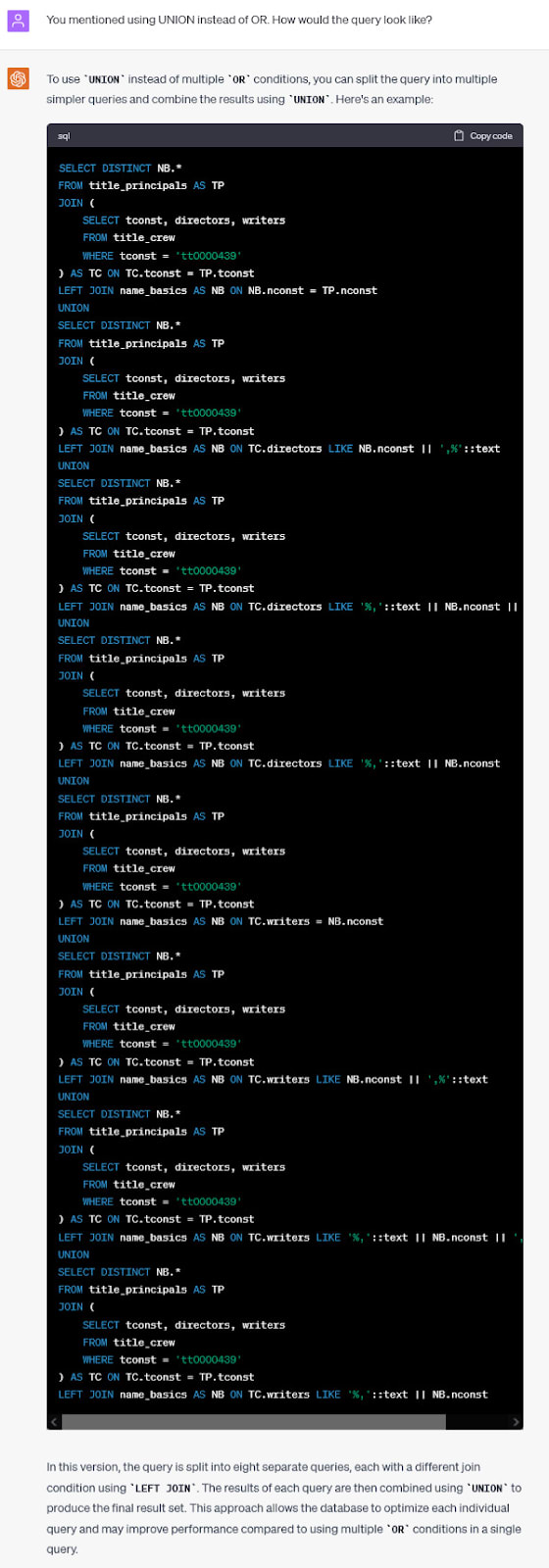
Looks promising. First, the query has no errors, it runs correctly. Second, it’s much faster than the previous one. It runs in 24 seconds vs nearly 90 before. However, the new query returns one additional row full of nulls. It works faster, but changes the behavior and may break the application.
Not to mention that we can do better. The query I rewrote manually runs in less than 0.1 seconds and returns the correct dataset. Therefore, relying on ChatGPT in this case gave significant speedups, but we can do much better.
Find the most prolific actor in a given period
Let’s carry on:
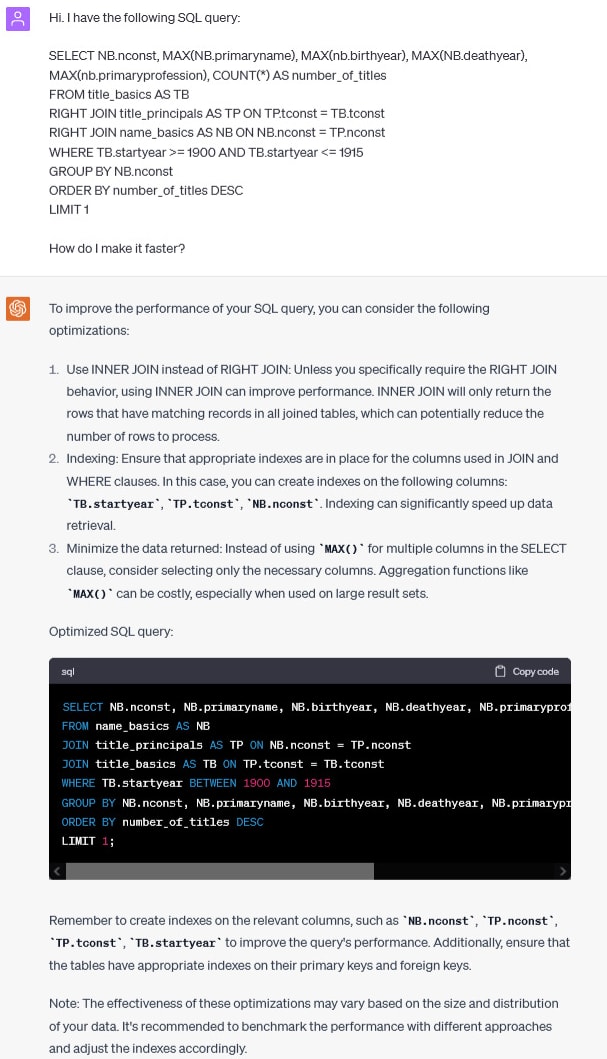
Let’s see how the new query performs. The original one runs in 21 seconds. The new one has the same performance. Removing aggregates didn’t help.
Again, the optimized query I wrote by hand in the other post was faster. It executes in 14 seconds.
Find most prolific actors in a given genre
Let’s carry one with genres now:
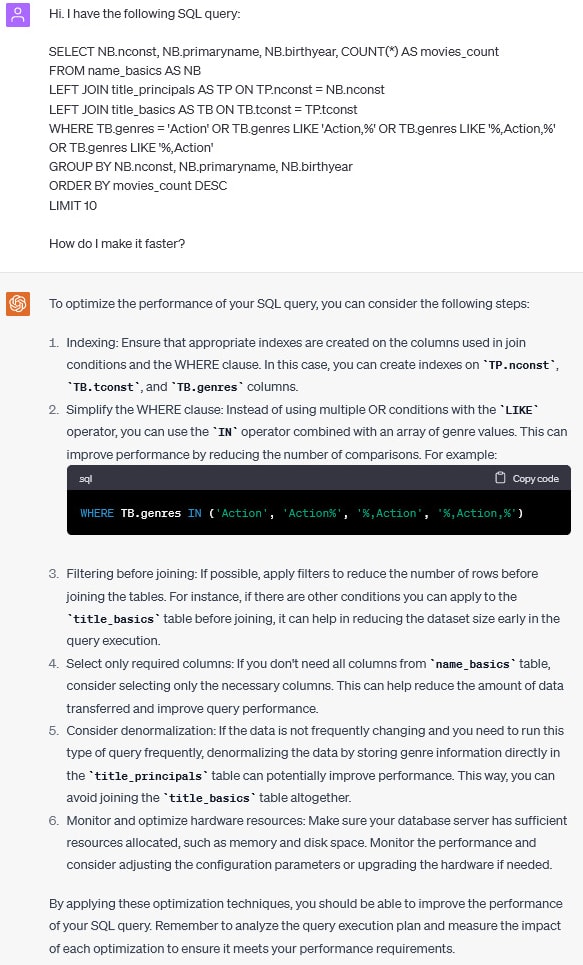
Let’s ask how the optimized query would look like:
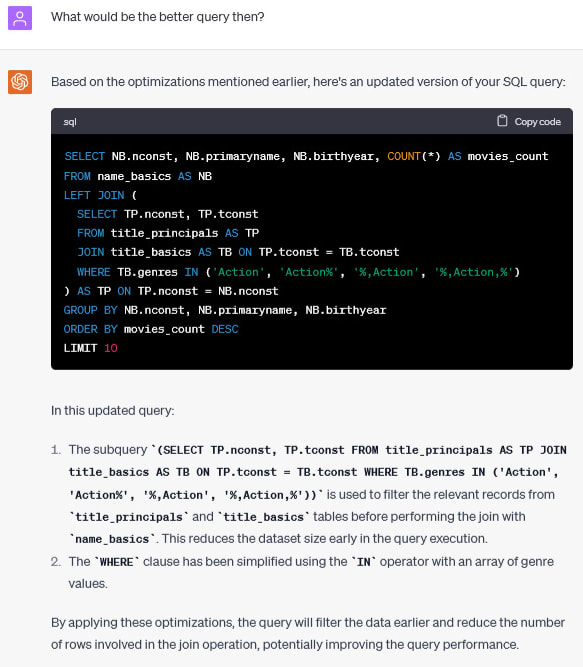
Let’s see how it worked. Original query runs in 42 seconds, the one proposed by ChatGPT runs in 27 seconds. That looks like a big win! However, the query provided by ChatGPT completely missed the point. One can’t replace LIKE operator with IN just like that. ChatGPT’s query returns completely different (and incorrect) results.
Let’s see if ChatGPT can realize that:

The second query provided by ChatGPT works in 52 seconds and returns the correct dataset. Therefore, it’s even worse than it used to be. The optimized query I wrote by hand runs in 34 seconds. Once again, I did better than ChatGPT.
Finding most common coworkers
Let’s now do something crazy.

Let’s ask for a query specifically:

My query runs in 9 seconds. The one provided by ChatGPT executes in 6 seconds, but it returns incorrect results. Again, let’s see if ChatGPT can fix that:
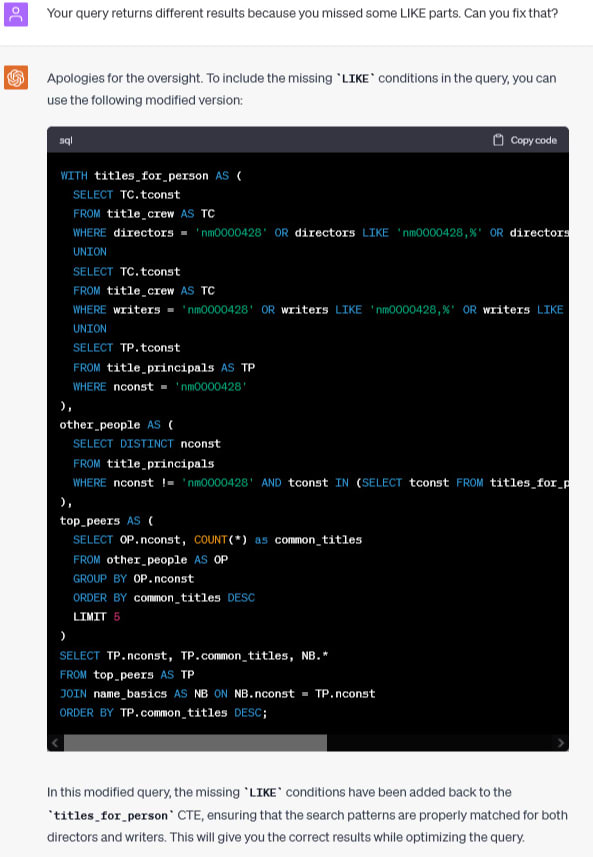
Query runs in 8 seconds, but still returns the wrong data. ChatGPT couldn’t make it better.
Summary
Database tuning is hard. ChatGPT can help with some simple queries and indexes, but can’t be trusted blindly. Queries may return wrong data, or just provide only partial performance improvement.
To improve query performance we need good tooling. Metis can give us all the insights we need to reason about queries and optimize them as needed.
Posted on September 26, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.