Advent of Code 2020: Day 08 using a whole computing cluster to do one CPU's job

Yuan Gao
Posted on December 10, 2020

It's time to get a little creative. This time I've made the world's most inefficient virtual CPU, by using a whole computing cluster to emulate one CPU that has a whole three instructions, at a speed of about 0.1Hz
But actually, the infrastructure to do this was originally intended for large data processing jobs, I've just given it a processing job of one CPU cycle per task, which wasn't the most efficient thing to do.
Things mentioned in this post: Fetch-execute cycles, DAGs, ETL, data pipelines, Apache Airflow, Redis, Kubernetes, CI/CD
The Challenge Part 1
Link to challenge on Advent of Code 2020 website
The challenge today is to basically make a CPU. It's a great little question as it teaches a little bit about how computers work.
The example gives the following program:
nop +0
acc +1
jmp +4
acc +3
jmp -3
acc -99
acc +1
jmp -4
acc +6
This kind of instruction listing is similar to how computer programs are stored in memory, each line is a CPU instruction, and under normal circumstances, each instruction is executed in turn before moving onto the next one. jmp commands directly jump the execution to another line. Each instruction consists of a mnemonic for what instruction it is, and a value to use.
The task is to follow the execution of the program and find the point at which it loops. The interesting thing about this question is it's actually quite an unusual task, most of the time when we're working with low-level CPU instructions, it's rare that we're asked to detect when looping happens because it's quite hard for a computer to introspect what instructions it's executing, and requires the help of an external debugger.
Anyways...
Loading Data
While I could use PEG another time, this one's simple enough to go back to just splitting the text. A quick readlines() followed by some split() followed by a little list-comprehension to format things correctly, and we can read the data right out:
instructions = [[inst, int(val)] for inst, val in [line.split() for line in open("input.txt").readlines()]]
Output
[['acc', 22],
['acc', 42],
['nop', 456],
['jmp', 5],
['acc', 31],
['acc', 49],
...
We have a list of lists, containing the mnemonic and value as an integer (which can be negative)
Virtual CPU
Here's the most stripped down possible virtual CPU: we simply start looping, and when we hit an acc command we add the value onto the accumulator (just a register/some memory in the CPU that can store a value, think of it as a variable that's inside the CPU and lets it remember numbers as part of calculations), and if it hits a jmp command, we jump the program counter (the program counter is another register in the CPU that keeps track of what instruction is being executed). nop doesn't do anything, in fact it's not handled at all here.
pc = 0
acc = 0
while True:
inst, val = instructions[pc]
if inst == "acc":
acc += val
pc += val if inst == "jmp" else 1
I've taken the liberty of shortening this code a bit, and instead compounded the program counter increment into a ternary, so that if the instruction is jmp the jump value will be added to the program counter, and every other instruction just adds 1.
This is all that is needed to create a virtual "CPU" to run this instruction set.
However, we're told explicitly that this code will loop, and that our job is to detect that loop, and get the value of the accumulator when it starts to loop. So we need to add in some record of what instructions were being executed. We can do this with a simple list:
visited = []
pc = 0
acc = 0
while pc not in visited:
visited.append(pc)
inst, val = instructions[pc]
if inst == "acc":
acc += val
pc += val if inst == "jmp" else 1
print(acc)
That was all that is required for Part 1.
The Challenge Part 2
The second part of the challenge tells us that in order to get out of the loop, one instruction somewhere in the code has to be switched. I think the easiest way to solve this particular problem is to brute-force it - try all the possible cases for an instruction being swapped, and see which one doesn't loop, and in fact executes all the way to the end.
It's not too much extra code, but let's take a moment to clean up the code and make it really nice. After all, what if we wanted to start making a fancier computer? What if we tried to lay the foundations of our own virtual computer, and do this in a way that would be more extendable in the future? Let's tidy up this code!
Firstly, pc and acc are registers. The job of a register is to store a number. Since this particular instruction set is very fond of relative numbers, we want to give our registers the ability to increase themselves by some value provided. So we define a class:
class Register:
def __init__(self):
self.reset()
def reset(self):
self.value = 0
def incr(self, amount):
self.value += amount
Now instead of just using a variable, our code actually looks like this now:
visited = []
pc = Register()
acc = Register()
while pc not in visited:
visited.append(pc)
inst, val = instructions[pc]
if inst == "acc":
acc.incr(val)
pc.incr(val if inst == "jmp" else 1)
print(acc)
Next, the loop prevention system is currently all over the place, let's clean that up with its own class, and we're going to use a custom exception to signal when a loop is detected, allowing us to break out of whatever it was that we were doing at the time.
class LoopDetected(Exception):
pass
class LoopPrevention:
def __init__(self):
self.reset()
def reset(self):
self.visited = []
def visit(self, value):
if value in self.visited:
raise LoopDetected
self.visited.append(value)
With that, the code looks like this now:
loop_prevention = LoopPrevention()
pc = Register()
acc = Register()
try:
while True:
loop_prevention.visit(pc)
inst, val = instructions[pc]
if inst == "acc":
acc.incr(val)
pc.incr(val if inst == "jmp" else 1)
except LoopDetected:
print("looped!", acc)
Now, let's define the program loader, just something to help us load instructions into our CPU. It's not really needed right now, but it helps us be more extensible in the future (foreshadowing foreshadowing). Let's also add an exception for detecting the end of a program.
class ProgramLoader:
def __init__(self):
self.reset()
def reset(self):
self.program = []
def load(self, instructions):
self.program = instructions
def fetch(self, idx):
try:
return self.program[idx]
except IndexError as err:
raise ProgEnd() from err
Our code now looks like this:
loop_prevention = LoopPrevention()
pc = Register()
acc = Register()
program_loader = ProgramLoader()
program_loader.load(instructions)
try:
while True:
loop_prevention.visit(pc)
inst, val = program_loader.fetch(pc)
if inst == "acc":
acc.incr(val)
pc.incr(val if inst == "jmp" else 1)
except LoopDetected:
print("looped!", acc)
Finally, let's put the above code into a CPU class, and also tidy up how the operations are resolved:
class CPU:
def __init__(self):
self.pc = Register()
self.acc = Register()
self.loop_prevention = LoopPrevention()
self.program_loader = ProgramLoader()
def reset(self):
self.pc.reset()
self.acc.reset()
self.loop_prevention.reset()
def load_program(self, instructions):
self.program_loader.load(instructions)
def fetch(self):
self.loop_prevention.visit(self.pc.value)
return self.program_loader.fetch(self.pc.value)
def execute(self, inst, val):
self.decode(inst)(val)
self.pc.incr(1) if inst != "jmp" else None
def fetch_execute_cycle(self):
inst, val = self.fetch()
self.execute(inst, val)
def run(self):
self.reset()
while True:
self.fetch_execute_cycle()
def decode(self, inst):
return self.__getattribute__(f"op_{inst}")
def op_nop(self, value):
pass
def op_jmp(self, value):
self.pc.incr(value)
def op_acc(self, value):
self.acc.incr(value)
It's long, but this makes it super easy to extend the CPU to have more registers, more instructions, and gives external controls over how the CPU is executing, including stepping instructions one at a time (by running fetch_execute_cycle()), and raising exceptions when things go wrong (like looping, or hitting the end of the program).
Notice the separation of fetch() and execute() (and decode()) this mirrors what real CPUs do, and so I've don this to mirror that slightly
The Part 1 solution using our new CPU class looks like this now:
cpu = CPU()
cpu.load_program(instructions)
try:
cpu.run()
except LoopDetected:
print(cpu.acc.value)
Part 2 however... simply requires us to iterate over all the instructions, and for each of them, try to run the CPU and see if it loops or completes
cpu = CPU()
for idx, (inst, _) in enumerate(instructions):
if inst == "jmp":
modified = copy.deepcopy(instructions)
modified[idx][0] = "nop"
elif inst == "nop":
modified = copy.deepcopy(instructions)
modified[idx][0] = "jmp"
else:
continue
cpu.load_program(modified)
try:
cpu.run()
except LoopDetected:
continue
except ProgEnd:
print("Complete!", cpu.acc.value, "idx", idx)
here, we're using deepcopy to make a full copy of the instructions so that we can change an instruction without affecting the original list. And we catch the LoopDetected and the ProgEnd exceptions to give us the answer.
That's all that's needed for Part 2.
Taking it too far
so... I didn't come here to make simple CPUs in python. I came here to do dumb things. Let's take this further. Notice how the CPU now doesn't require any variables to store data/state? We've moved those to register, program loader, and loop prevention classes.
That means we can change how the data is stored easily. We don't just have to store that data in variables, what if we stored them in files? or in databases?
Adding Redis
Let's go ahead and refactor these classes to store their data in a Redis database! Redis is a blazing fast and simple in-memory database, it's often used for caching, but has lots of interesting features.
The Register class now looks like this:
class Register:
def __init__(self, redis_conn, register_name):
self.redis_conn = redis_conn
self.key = register_name
self.reset()
@property
def value(self):
return int(self.redis_conn.get(self.key))
def reset(self):
self.redis_conn.set(self.key, 0)
def incr(self, amount):
self.redis_conn.incrby(self.key, amount)
We're using a regular redis value, which comes with the incrby command, which allows us to avoid having to read the value, increment it, and then write the value. The database will just do the increment by the amount we tell it to.
The LoopPrevention class now looks like this:
class LoopPrevention:
def __init__(self, redis_conn, name):
self.redis_conn = redis_conn
self.key = name
self.reset()
def reset(self):
self.redis_conn.delete(self.key)
def visit(self, value):
if self.redis_conn.sismember(self.key, value):
raise LoopDetected
self.redis_conn.sadd(self.key, value)
Here, we use a Redis Set. a Set in redis lets us do easy "is member" checks to see whether a value already exists in the set. Since we will not have any duplicate values and the order doesn't matter, this is the right data type to use.
The ProgramLoader class now looks like this:
import json
class ProgramLoader:
def __init__(self, redis_conn, name):
self.redis_conn = redis_conn
self.key = name
def reset(self):
self.redis_conn.delete(self.key)
def load(self, instructions):
encoded = [json.dumps(instruction) for instruction in instructions]
self.redis_conn.rpush(self.key, *encoded)
def fetch(self, idx):
encoded = self.redis_conn.lindex(self.key, idx)
if encoded is None:
raise ProgramEnd()
return json.loads(encoded)
We have to do a bit of json serialization here because our instructions come in two parts. and redis can only store strings. Here we're using a Redis list, which is your typical array. We can add stuff into the array, and read parts of the array using their index.
Finally, some modification to CPU is needed to pass connections and register names:
import redis
class CPU:
def __init__(self, name):
redis_conn = redis.Redis(host=os.environ.get("REDIS_HOST", "localhost"))
self.pc = Register(redis_conn, f"{name}-pc")
self.acc = Register(redis_conn, f"{name}-acc")
self.loop_prevention = LoopPrevention(redis_conn, f"{name}-loop")
self.program_loader = ProgramLoader(redis_conn, f"{name}-program")
def reset(self):
self.pc.reset()
self.acc.reset()
self.loop_prevention.reset()
def load_program(self, instructions):
self.program_loader.load(instructions)
def fetch(self):
self.loop_prevention.visit(self.pc.value)
return self.program_loader.fetch(self.pc.value)
def execute(self, inst, val):
self.decode(inst)(val)
self.pc.incr(1) if inst != "jmp" else None
def fetch_execute_cycle(self):
inst, val = self.fetch()
self.execute(inst, val)
def run(self):
self.reset()
while True:
self.fetch_execute_cycle()
def decode(self, inst):
return self.__getattribute__(f"op_{inst}")
def op_nop(self, value):
pass
def op_jmp(self, value):
self.pc.incr(value)
def op_acc(self, value):
self.acc.incr(value)
So, we now have a virtual CPU that doesn't store its registers or memory in your python script. It stores it in a database. That database doesn't even have to be in your computer, it could be on the internet somewhere! We have a virtual CPU whose memory is elsewhere.
The interesting property of this CPU is that it is stateless! You can load some instructions, quit the python script, and launch another script to execute one clock cycle.
So... let's do that. Let's make a python script that executes one thing on the CPU per execution.
Add convenience scripts
Let's start by adding some conveniences to help us with setting up the right CPU, and printing statuses. Note that exit_with_json() also writes out a json file. We'll need this later for airflow, so it's commented out for now
import sys
import json
import argparse
from enum import Enum
from .cpu import CPU
# return values
class Statuses(Enum):
ok = 1
invalid = 2
end = 3
loop = 4
# arguments
parser = argparse.ArgumentParser(description="CPU loader")
parser.add_argument("cpu_name", help="Name of this CPU")
parser.add_argument("mod_line", type=int, metavar="N", nargs="?", default=None, help="Name of this CPU")
args = parser.parse_args()
def get_cpu():
return CPU(args.cpu_name)
def exit_with_json(status, **kwargs):
result = dict(status=status.name, **kwargs)
print(result)
# with open("/airflow/xcom/return.json", "w") as fp:
# json.dump(result, fp)
sys.exit()
Now let's make a separate python file to load instructions (including the modified instructions needed in part 2)
import os
from .common import get_cpu, args, exit_with_json, Statuses
cpu = get_cpu()
program_file = os.path.join(os.path.dirname(__file__), "input.txt")
instructions = [[inst, int(val)] for inst, val in [line.split() for line in open(program_file).readlines()]]
if args.mod_line is not None:
if args.mod_line >= len(instructions):
exit_with_json(Statuses.invalid)
inst = instructions[args.mod_line][0]
if inst == "acc":
exit_with_json(Statuses.invalid)
if inst == "nop":
instructions[args.mod_line][0] = "jmp"
elif inst == "jmp":
instructions[args.mod_line][0] = "nop"
cpu.load_program(instructions)
cpu.reset()
exit_with_json(Statuses.ok)
As can be seen, this prepares the modified instruction, and loads them into a CPU whose name is provided by command-line arguments. For example this:
python load.py "abc" 10
Would cause a new CPU with the Id of "abc" to be created, and the instructions with line 10 swapped out loaded into the CPU (actually causes the program to be stored in Redis database)
Next, a file to run the CPU:
from .common import get_cpu, ProgEnd, LoopDetected, Statuses, exit_with_json
cpu = get_cpu()
try:
cpu.fetch_execute_cycle()
except LoopDetected:
exit_with_json(status=Statuses.loop)
except ProgEnd:
exit_with_json(status=Statuses.end)
else:
exit_with_json(status=Statuses.ok)
To run it, running this file and providing the CPU name as an argument will cause the CPU to execute one cycle and quit.
python exec.py "abc"
Finally, to read the register, we need one last script:
from .common import get_cpu, exit_with_json, Statuses
cpu = get_cpu()
exit_with_json(Statuses.ok, acc=cpu.acc.value)
Running it returns the value in the accumulator:
python read.py "abc"
Great! We can now run our CPU one cycle at a time just by running python scripts. But... what's the point of that? Bear with me....
Add dependency management and Dockerfile
Now that we have the python scripts as separate scripts to run, I'm going to add a Pipfile, this is my preferred dependency management. The Pipfile (which was actually generated from the command line, rather than being written by hand) looks like this:
[[source]]
name = "pypi"
url = "https://pypi.org/simple"
verify_ssl = true
[scripts]
load = "python -m src.load"
exec = "python -m src.exec"
read = "python -m src.read"
[packages]
redis = "*"
[requires]
python_version = "3.8"
This just allows me to easily run pipenv run load "abc" 10 to invoke the load script at src/load.py
Next... I add a Docker file:
FROM python:3.8-alpine
RUN pip3 install --no-cache-dir pipenv==2020.11.15
WORKDIR /workdir
COPY Pipfile* ./
RUN pipenv install --deploy
COPY . .
ENTRYPOINT ["pipenv", "run"]
This docker file, when built, takes all of our CPU stuff and generates a docker image with it.
Next... I add a Gitlab CI script and push to my gitlab registry, where the CI/CD automatically takes this docker file, builds it, and pushes it to a docker registry.
Add Airflow DAGs
Next... I write this DAG file:
import random
from datetime import timedelta
from airflow.utils import timezone
from airflow.utils.dates import days_ago
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.api.client.local_client import Client
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": days_ago(2),
"retries": 0,
"wait_for_downstream": False,
}
dag = DAG(
"cpu_start",
default_args=default_args,
catchup=False,
description="A really awful CPU",
schedule_interval=None,
)
def _task_spinup(**context):
""" spin up all the tasks """
run_id = timezone.utcnow()
airflow_client = Client(None, None)
for idx in range(0, 612:
ex_date = timezone.utcnow() + timedelta(seconds=idx - 230)
cpu_name = f"cpu-{idx}"
airflow_client.trigger_dag(
dag_id="cpu",
run_id=f"{cpu_name}-{run_id}",
conf={"cpu_name": cpu_name, "step": None, "idx": idx},
execution_date=ex_date,
)
task_spinup = PythonOperator(
task_id="task_spinup",
python_callable=_task_spinup,
dag=dag,
)
This is an Airflow DAG file. Airflow is used for building data pipelines/workflows. We use it for big data processing tasks, or ETL tasks. It helps schedule and run multi-step workflows. The above DAG's task is to spin up 611 other DAGs, each one is a separate run of our CPU, and each one has a different idx provided, which we'll use to swap a different instruction.
Now, the second DAG:
import sys
import os
import logging
from datetime import timedelta
from airflow.utils import timezone
from airflow.utils.dates import days_ago
from airflow import DAG
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
from airflow.operators.python_operator import PythonOperator, BranchPythonOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.api.client.local_client import Client
from airflow.exceptions import DagRunAlreadyExists
from airflow.utils.trigger_rule import TriggerRule
# pylint: disable=wrong-import-position
sys.path.append(os.path.join(os.path.dirname(__file__), "../"))
from scripts.slack_notify import notify_success
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": days_ago(2),
"retries": 0,
"wait_for_downstream": False,
}
dag = DAG(
"cpu",
default_args=default_args,
catchup=False,
description="A really awful CPU",
schedule_interval=None,
)
image_name = <snip>
def _task_check_new(**context):
step = context["dag_run"].conf.get("step", None)
if step is None:
return "task_load"
return "task_execute"
task_check_new = BranchPythonOperator(
task_id="task_check_new",
python_callable=_task_check_new,
provide_context=True,
dag=dag,
)
class LoadOperator(KubernetesPodOperator):
def execute(self, context):
cpu_name = context["dag_run"].conf["cpu_name"]
idx = context["dag_run"].conf["idx"]
self.arguments = ["load", cpu_name, str(idx)]
return super().execute(context)
task_load = LoadOperator(
namespace="airflow-jobs",
image=image_name,
task_id="task_load",
name="cpu_load",
get_logs=True,
do_xcom_push=True,
dag=dag,
)
class ExecOperator(KubernetesPodOperator):
def execute(self, context):
cpu_name = context["dag_run"].conf["cpu_name"]
self.arguments = ["exec", cpu_name]
return super().execute(context)
task_execute = ExecOperator(
namespace="airflow-jobs",
image=image_name,
task_id="task_execute",
name="cpu_exec",
get_logs=True,
do_xcom_push=True,
dag=dag,
)
def _task_check_result(**context):
""" Load instructions onto CPU """
return_value = context["task_instance"].xcom_pull(task_ids="task_load", key="return_value")
logger.info(return_value)
if not return_value:
return_value = context["task_instance"].xcom_pull(task_ids="task_execute", key="return_value")
logger.info(return_value)
if return_value["status"] == "end":
return "task_start_read"
if return_value["status"] == "ok":
return "task_next"
return "task_end"
task_check_result = BranchPythonOperator(
task_id="task_check_result",
python_callable=_task_check_result,
provide_context=True,
trigger_rule=TriggerRule.ONE_SUCCESS,
dag=dag,
)
class ReadOperator(KubernetesPodOperator):
def execute(self, context):
cpu_name = context["dag_run"].conf["cpu_name"]
self.arguments = ["read", cpu_name]
return super().execute(context)
task_start_read = ReadOperator(
namespace="airflow-jobs",
image=image_name,
task_id="task_start_read",
name="cpu_read",
get_logs=True,
do_xcom_push=True,
dag=dag,
)
def _task_read(context):
""" Read results """
result = context["task_instance"].xcom_pull(task_ids="task_start_read", key="return_value")
logger.info(result)
notify_success(
context=context,
message=f"The answer is {result['acc']}",
)
task_read = PythonOperator(
task_id="task_read",
python_callable=_task_read,
provide_context=True,
dag=dag,
)
def _task_next(**context):
""" spin up all the tasks """
cpu_name = context["dag_run"].conf["cpu_name"]
step = context["dag_run"].conf["step"]
if step is None:
step = 0
else:
step += 1
airflow_client = Client(None, None)
for idx in range(1000):
ex_date = timezone.utcnow() + timedelta(seconds=idx)
try:
airflow_client.trigger_dag(
dag_id="cpu",
run_id=f"{cpu_name}-{step}",
conf={
"cpu_name": cpu_name,
"step": step,
},
execution_date=ex_date,
)
except DagRunAlreadyExists:
continue
else:
break
else:
raise Exception("Failed to schedule, exceeded retries")
task_next = PythonOperator(
task_id="task_next",
python_callable=_task_next,
provide_context=True,
dag=dag,
)
task_end = DummyOperator(task_id="task_end", dag=dag)
# pylint: disable=pointless-statement
task_check_new >> task_execute >> task_check_result >> task_start_read >> task_read
task_check_new >> task_load >> task_check_result >> task_next
task_check_result >> task_end
What a mouthfull. So... this is the DAG that actually performs the execution of the CPU. What it is actually doing is firing off the image we just built inside a kubernetes cluster, meaning we can easily orchestrate and scale how many CPUs we're running in there, whether it's 4 at a time, or 400 at a time.
Without walking through this DAG line by line, the main thing to look at is the last chunk of code
task_check_new >> task_execute >> task_check_result >> task_start_read >> task_read
task_check_new >> task_load >> task_check_result >> task_next
task_check_result >> task_end
This weird looking structure defines the workflow. In graph form it looks like this:

We check if it's a new tasks, then either load it, or execute a cycle. Then we pick up the results and based on the output, either end the task (usually because it's an invalid run for the purposes of our task); run the next cycle; or start a read of the accumulator because we found the answer.
Running the pipeline
When the pipeline runs, the first thing it does is to start loading up the (modified) instruction for each named CPU. Since we only swap "jmp" and "nop" commands, any time an instruction that we swap was "acc", we instead report back that this was "invalid", and this causes that CPU run to not go any further. The loading phase looks a bit like this on the left:

Different CPUs will either hit the "task_end" it was "invalid" and no further runs will be called, or it will hit the "task_next", which will cause further cycles for that CPU to run.
Over on the right hand side of this chart of DAG runs, you can see the CPUs start to run their task_execute jobs. Each vertical column is one CPU cycle of a CPU!
Over on our Kubernetes dashboard, we start seeing thousands and thousands of cpu-exec containers start to be spawned. This takes a while, since each CPU, and each instruction, end up running as a separate Kubernetes pod, which includes the docker container we built (or had our CI system build) previously.

Officially we are running our CPU at a very very slow rate of probably fractions of a Hz, and it's taking a whole lot of processing power to do it!
Then at some point, our CPU will hit that one correct value, and return the accumulator to us...

There it is! And what's more, since we have a slack notification set up, we get a slack message about it
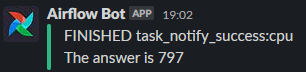
There you have it, my totally overboard solution to Part 2. While this is a dumb use of Airflow, the actual infrastructure is hugely useful for any data processing tasks that must be automated. The ability to run containers in a Kubernetes cluster means it is very easy to scale the processing power up and down. If today I had
a task to run data processing on a million items, I could easily scale the cluster up to several hundred machines, and let Kubernetes and Airflow take care of spreading the jobs across the cluster to quickly process them, no additional setup needed.
Onward!
Posted on December 10, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
December 10, 2020