4 Key Design Principles and Guarantees of Streaming Database

avital trifsik
Posted on October 18, 2022

Real-time data processing is a foundational aspect of running modern technology-oriented businesses. Customers want quicker results than ever and will defect at the slightest opportunity of having faster outcomes. Hence organizations these days are in a continuous hunt to shave off milliseconds from their responses.
Real-time processing is taking over most aspects that were earlier handled using batch processing. Real-time processing requires executing business logic on an incoming stream of data. This is in stark contrast to the traditional way of storing the data in a database and then executing analytical queries. Such applications can not afford the delay involved in loading the data first to a traditional database and then executing the queries. This sets the stage for streaming databases. Streaming databases are data stores that can receive high-velocity data and process them on the go, without a traditional database in the mix. They are not drop-in replacements for the traditional database but are good at handling high-speed data. This article will cover the 4 key design principles and guarantees of streaming databases.
Understanding Streaming Databases
Streaming databases are databases that can collect and process an incoming series of data points (i.e., a data stream) in real-time. A traditional database stores the data and expects the user to execute queries to fetch results based on the latest data. In the modern world, where real-time processing is a key criterion, waiting for queries is not an option. Instead, the queries must run continuously and always return the latest data. Streaming databases facilitate this.
In the case of streaming databases, queries are not executed but rather registered because the execution never gets completed. They run for an infinite amount of time, reacting to newer data that comes in. Applications can also query back in time to get an idea of how data changed over time.
Compared to a traditional database, a streaming database does all the work at the time of writing. Accomplishing this comes with a lot of challenges. For one, there is minimum durability and correctness that one expects from a traditional database. Maintaining that kind of durability and correctness requires complicated designs when the data is always in motion. Then there is the challenge of how to enable the users to query the data in motion. SQL has been the standard for a long time now for all querying requirements. It is natural that streaming databases also support SQL, but implementing constructs like windowing, aggregation, etc are complex when the data is always moving.
A persistent query is a query that operates on moving data. They run indefinitely and keep churning out output rows. Persistent queries pose unique challenges in updating the logic. The key question is about the behavior when replacing the query with an improved one – Does it operate on all the data that arrived till then or only on the next set of data? The name of the first mode of operation is backfill and the latter is exactly-once processing. To implement exactly-once processing, the execution engine must have a local store. At times, the queries can feed to other data streams. Such an operation is called cascading mode.
Now that the concepts are clear, let us spend some time on the architectural details of a streaming database. A streaming database is typically built on top of a stream processing system that works based on the producer-consumer paradigm. A producer is an entity that creates the events. A consumer consumes the events and processes them. The events are generally grouped into logical partitions of topics to facilitate business logic implementation.
There is a broker that sits between them who ensures the reliability of the streams and format conversions that require for the producers and consumers. Broker is usually distributed on a distributed platform to ensure high availability and robustness. A stream query engine resides on top of the processing platform. An SQL abstraction layer that converts SQL queries to stream processing logic is also present. Stitching together everything, the architecture looks as below.
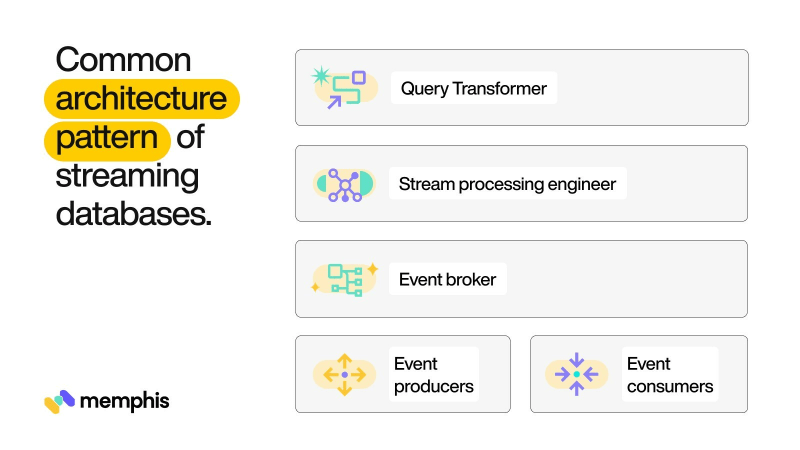
Now that we understand the concept of streaming databases and persistent queries, let us spend some time on the typical use cases for them.
IoT Platforms
IoT platforms deal with a large number of events being pushed from devices across the world. They need to spawn alerts based on real-time processing and have strict SLAs with respect to reaction times. IoT platforms also need to store all the events received forever and require window-based aggregations on streaming data for analytics. Streaming databases and persistent queries are a good fit here.
Event Sourcing
Event sourcing is a paradigm where application logic is executed in terms of events that happened over time rather than the final state of entities. This helps in improving the durability and reliability of the application since the application state can be recreated anytime by replying to the events. This is useful in cases where an audit trail is a mandatory requirement. Event sourcing is possible through an event sourcing database. A traditional relational database might not be suitable due to the rigid nature. A more suitable system is a message broker like Memphis.dev.
Click Stream Analytics
Clickstream analytics platforms deal with click events generated as part of application usage. The data from click events are at times directly fed to machine learning models that provide recommendations and suggestions to the customers. Persistent events and real-time processing on click streams are an important part of running a business like eCommerce.
Trading Systems
Trading systems process millions of trade requests per second and match them against the demand and supply equation to settle the transactions. An audit trail is a mandatory requirement in such cases where even the slightest of delays can cause huge monetary losses to parties involved.
Fraud Detection Systems
Fraud detection systems need to act immediately once detecting the scenarios that closely match the typical beginning of fraud. They also have to keep a record of triggered the alerts and the subsequent events after the incident. Consider a financial system fraud detection system that detects fraud based on the spending patterns of the rightful owner. It needs to feed the features of events to a fraud detection model on a real-time basis and act immediately when flagging a possible breach. Real-time databases are excellent solutions to implement such use cases.
IT Systems Monitoring
Centralized monitoring helps organizations to keep their IT systems always running Streaming databases are often used to collect logs from systems and generate alerts when specific conditions are met. The real-time alerts and audit trails generated through event storage are key elements of observable system implementation.
The streaming database market is not a crowded one and there are only a handful of databases that are battle-hardened to handle production workloads. Kafka, Materialize, Memgraph, etc are a few of the stable ones. Choosing one that fits a use case requires an elaborate comparison of their features and use case dissection.
Let us now shift our focus to learning the key database design principles and guarantees behind streaming databases.
4 Key Streaming Database Design Principles and Guarantees
The completeness of a database system is often represented in terms of whether the database is ACID compliant. The ACID complaince forms the foundation of good database design principles. ACID compliance stands for Atomicity, Consistency, Isolation, and Durability. Atomicity refers to the guarantee that a group of statement part of a logical operation will fail gracefully in case one of the statements have an error. Such a group of statements is called a transaction. In the earlier days of streaming databases, transaction support and hence atomicity was often missing. But the newer versions do support transactions.
Consistency refers to adhering to the rules enforced by the database like unique key constraints, foreign key constraints, etc. A consistent database will revert the transaction if the resultant state does not adhere to these rules. Isolation is the concept of separate transaction execution such that one transaction does not affect the other. This enables parallel execution of transactions. Databases like KSQLDB support strong consistency and parallel execution of queries. Durability is about recovering from failure points. The distributed nature of the architecture ensures strong durability for modern streaming databases.
Guarantee in the case of a streaming database refers to the assurance on handling the events. Since data is continuously moving, it is difficult to ensure the order of processing of events or avoid duplicate processing. Ensuring that all data get processed exactly once is an expensive operation and requires state storage and acknowledgments. Similarly ensuring that messages get processed in the same order that they were received requires complex architecture in the case of a distributed application
Let us now look into the core design principles and how they are accomplished in streaming databases.
Auto Recovery
Auto recovery is one of the most critical database design principle in case of a streaming database. Streaming databases are used in highly regulated domains like healthcare, financial systems, etc. In such domains, there are no excuses for failures and incidents can result in huge monetary loss or even loss of life. Imagine a streaming database that is integrated as a part of a healthcare IoT platform. The sensors monitor the vital parameters of the patients and send them to a streaming database hosted in the cloud. Such a system can never go down and the queries that generate alerts based on threshold values should run indefinitely.
Since failure is not an option for streaming databases, they are often implemented based on a distributed architecture. Streaming databases designed based on a cluster of nodes provide great fault tolerance because even if a few of the nodes go down, the rest of the system stays available to accept queries. This fault tolerance must be incorporated into the design of streaming databases early in the development cycle. Let us see the key activities involved in the auto recovery of streaming databases now.
Auto Recovery in the distributed streaming database involves the below activities:
Failure Detection
Rebalancing and Intelligent Routing
Final recovery
Failure detection is the first step of auto recovery. The system must be self-aware enough to detect failure conditions so that it can take necessary steps for recovery. In distributed systems, failure detection is usually done through a heartbeat mechanism. A heartbeat is a periodic lightweight message that the nodes sent each or to the master of the cluster. This lets others know that it is alive and kicking. If the heartbeat message from a node is not received, the system assumes, it is dead and initiates recovery procedures. The size of heartbeat messages, the information bundled in them, and the frequency of heartbeat messages are important in optimizing the resources. A very frequent heartbeat will help detect failures, that much earlier, but it also uses up processing time and creates overheads.
When a node failure occurs in distributed systems, the resources owned by that node must be rebalanced to other nodes. Distributed systems use controlled replication to ensure that data is not lost even when a few of the nodes go down. Once a node goes down, the system ensures that data gets rebalanced across other nodes and maintains a replication strategy as much as possible to reduce the risk of data loss.
To maintain a highly available streaming database, rebalancing during partial failures is not enough. Since the queries are always running in the case of streaming databases, the system needs to ensure they keep running. This is where intelligent routing comes in. intelligent routing helps to ensure that the query keeps running and returns the result. The queries using resources on the failed node are routed to other nodes seamlessly. This requires careful design and is part of the foundational requirements for a streaming database.
The final recovery involves recovering the state stores that have been lost during the incident. State stores are required to ensure the system meets the user-configured constraints exactly once, at most once, or at least processing guarantees. Distributed databases often use an infinite log as the source of truth. They also use separate topics where they keep the time offsets as a recovery mechanism. In case of a failure, this time offset topic can be used to recreate the timeline of events.
Exactly Once Semantics
In the case of streaming databases, auto recovery in failure cases is not enough. Unlike traditional database design, streaming database design should ensure that the results lost during the time of failure do not affect the downstream consumer. There are several aspects to accomplishing this. First, the system needs to ensure no records miss processing. This can be done by reprocessing all the records, but there are risks involved. For one, reprocessing without adequate consideration can lead to records being processed more than once. This causes inaccurate results. For example, consider the same health care IOT platform where alerts are life-deciding ones. Duplicate processing can lead to duplicate alerts and thereby the waste of resources. Duplicate processing will also lead to aggregated results like averages, percentile calculations, etc.
Depending on the requirements, at times, some errors in event processing may be acceptable. Streaming databases define different message processing guarantees to support use cases with different requirements. There are three types of message guarantees that are available – at most once, at least once, and exactly once. Utmost once guarantee defines the case where messages will never be processed more than once, but at times may miss processing. The At-least-once guarantee defines the case where duplicate processing is allowed, but missing records is not acceptable.
Exactly once semantics guarantees that a message will be processed only once and the results will be accurate enough so that the consumer is oblivious to the failure incident. Let us explore this concept with the help of a diagram.

Let’s say the system is processing messages that are coming in order. For representation, messages are ordered starting 1 here. The processor receives the messages, transforms or aggregates it according to the logic, and passes them to the consumer. In the above diagram, green denotes the messages that are yet to be processed and red denotes the ones that are processed. Every time a message is processed, the processor updates a state store with the offset. This is to enable recovery in case of a failure. Now let’s say, the processor goes through an error after processing the second message and crashes. When the processor comes back up, it must restart processing from 3 and not from message 2. It should avoid making a duplicate update to the state store or feeding the result form message 2 again to the consumer.
In other words, the system masks failures both from a result perspective and an inter-system communication perspective. This requires the producer, messaging system, and consumer to cooperate based on agreed contracts. A message delivery acknowledgment is the simplest guarantee that can help the streaming database accomplish this. The contract should be able to withstand a broker failure, a producer-to-broker communication failure, or even a consumer failure.
Handling Out Of Order Records
Good database design considers handling out of order records as a critical aspect. Streaming database encounter out of records due to many reasons. The reasons include network delays, producer unreliability, unsynchronized clocks etc. Since they are used in highly sensitive applications like finance and healthcare where order of processing is very important, streaming databases must handle them graciously. To understand the problem better, let us consider the example of the same IOT healthcare platform. Let’s say due to a momentary internet connection failure one of devices failed to send data for a short window of time. When it resumed, it started sending data from the resumption time. After a while, the firmware in the device sent the rest of the data that it had failed to send earlier. This leads to out of order records arriving at the streaming database.
For better context, let’s explain this problem using a diagram now. The below diagram has a producer that sends messages with numbers starting from 1. The green blocks represent the events that are yet to be sent and the red ones represent the already sent events here. When messages. 1,2 and 3 arrive in the order of their timestamps, everything is fine. But if one of messages is delayed on the way or from the source itself, it will cause corruption to the results from streaming platform. In this case, the messages 1 and 3 arrived earlier than 2. The streaming platform receives 2 after 1 and 3, but it must ensure that the downstream consumer receives the messages in the actual order.

The streaming database that processes the records will provide inaccurate results to down stream systems if out-of-order records are not properly addressed. For example, lets say, the messages denote a temperature value and there is a persistent query that finds the average temperature for the last one minute. A delayed temperature value can result in an erroneous average value. Streaming databases handles these cases in two methods. The first method involves a configuration parameter that defines the amount of time the processor will wait for out of order records to arrive before each micro batch starts. Micro batch is a group of records that are part of a real time query. The concept of microbatch is the foundation of persistent queries.
The second method to address out-of-order records is to allow processor to update already computed results. This requires an agreement with the consumer. This concept directly conflicts with the concept of transactions and hence requires careful design while implementation. This works only in cases where the down stream consumers is capable of producing the same output even if it received the input in a different order. For example, if the downstream consumer’s output is a table that allows revisions, then streaming databases can use this strategy.
Consistent Query Results
Implementing streaming databases is typically based on distributed architecture. Traditional database design principles consider atomicity and consistency as key pillars of good database design. But in case of streaming database, It is tough to accomplish consistency in writes because the distributed nature. Consider a streaming database that uses the concept of replicated partitions and deployed on a cluster of nodes. The incomes streams will be going to different partitions or nodes based on the storage pattern. To ensure tru write consistency, one needs to ensure the stream is confirmed only when all the partitions reflect it as successful. This is difficult when there are multiple messages as part of a logical transaction. Tracking separately and confirming each of the messages is essential prior to marking the transaction as successful.
The difficulty in ensuring write consistency trickles to read consistency as well. Returning consistent query results are possible only if reads are consistent. Consider a stream that acts as a data source for multiple persistent queries that aggregates the stream according to different business logic. A streaming database must ensure that both the queries act on a single source of truth and the results from the queries reflect non-conflicting values. This is an extremely difficult proposition because in order to handle out-of-order records, most databases operate in a continuous update mode often changing the results that they previously computed. In case of concatenated queries, such updates trickle down to downstream stream at different times and some derived query state may reflect a different source data state.****
There are two ways of solving the problem of consistent query results. The first method deals with this by ensuring that writes are not confirmed till the time, all queries originating from that stream completes. This is expensive in the side of the producer. Because to satisfy the exactly once processing requirement, most streaming databases rely on aknwoedlegemtns between the broker and the producer. If all the writes are confirmed only after query completion, then producers are kept in the dark for that much longer. This approach is the block-on-write approach.
The second approach to solving consistency is to do it at the querying engine level. Here, the querying engine delays the results of the specific queries that requires strong consistency guarantees till all the writes are confirmed. This is less expensive than the first approach because the write performance of input streams is not affected. Rather than delaying the confirmation of the input stream that acts as foundation of a query, this approach operates at query level. So if a query does not require strong consistency guarantees, the results for that will be emitted earlier than other queries that depend on the same input stream. Hence, different queries operate on different versions of the same input stream depending on their consistency configuration. This requires the streaming database to keep a linearized history of all the computations so that it can easily conclude about the versions on data on which multiple queries were executed.
Streaming databases have to balance between staleness of the data and levels of consistency in order to optimize the performance. Going up through the levels of consistency may result in reduced speed of processing and vice versa.
Conclusion
Streaming databases are the foundation of real time processing applications. They are not a replacement for traditional databases but helps satisfy unique requirements that need always-on processing on never-ending streams of data. Designing a streaming database is a complex task because of the constraints involved in handling streaming data. Achieving read consistency, handling out-of-erder data, ensuring exactly-once processing and auto recovery are the typical design principles in consideration while designing a streaming database.
Thanks to Idan Asulin Co-founder & CTO at memphis.dev for the writing.
Join 4500+ others and sign up for our data engineering newsletter
Posted on October 18, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related