
Matthew DesEnfants
Posted on January 19, 2023

Overview
A new generation of tools is giving nontraditional techies the chance to build cool stuff. Software engineering is not their day job, but they are effective none the less. These are citizen developers.
If you want to make an app with PowerApps, Airtable, or Monday.com, this will help you think critically about building software for internal use. In some cases, you'll learn when to consult an expert.
Why I'm writing this
I've been a software engineer and engineering lead for over a decade. In that time, I've pitched, built, and inherited several no-code/low-code (NCLC) solutions.
These are often sold to people who work in operational roles like finance, law, communications, and human resources. NCLC apps span some kind of technology gap where budgets are limited.
NCLC platforms are often included in some major consulting pitch to a business group. These pitches promise timely implementation and simple/cheap maintenance. This is rarely true, but we'll get to that in a minute.
More often, I'll find that an intrepid, scrappy individual learned NCLC on her own to solve her own problem. If that's you, high five! I got into this career because there's nothing more empowering than making the computer to do the boring stuff. You're among the chosen.
The thing is... low code tools are not yet very good at revealing fundamental problems with your app. Professional software engineers can find it difficult to implement simple scenarios in a NCLC environment because we find gaps that the platform might not let us fix. Most of these gaps wouldn't even occur to someone without the proper training. Groups that deploy NCLC apps often employ junior engineers don't have the experience to identify these deficiencies. This can lead to a very long, expensive maintenance tail for people who rely on these tools to do business. Building is easy, fixing is hard.
In this article, I hope to bring you up to speed on some common pitfalls when building an app, how you can avoid them, and how you might fix them if you're already stuck. These pitfalls are independent of any one NCLC framework. Rather, they're just good hygene practices translated from my discipline to yours.
Reliability
Software engineers spend a lot of time thinking about failure.
- Connection failure: "It says zombo.com cannot be reached."
- Hardware failure: "The red light started flashing."
- Human failure: "I put all the zeroes before the dot on the wire transfer."
- Malicious failure: "I need to pay bitcoin to some guy in Lithuania to unlock my PC."
When programmers first learn how to write programs, we're taught the simplest approach to data management: CRUD.
- Create
- Read
- Update
- Delete
Basically, if you have access to the program and its records, you can do all four of the actions above. It is the most obvious approach to structure a program. Millions of apps are built this way. NCLC practically beckons you to this approach.
This also happens to make a lot of people very angry and is widely regarded as a bad move*.
Basic CRUD assumes that computers never break, humans don't make mistakes, history doesn't matter, and changes don't ever need to be reversed.
Luckily, there are some simple approaches that can make your NCLC solution a lot more trustworthy.
Write/fail vs. Retry
It is safe to assume that an app will not do what you tell it to do on the first attempt. There are a million reasons, but usually some back-end data service is just too busy or busted to take your call right now.
By expecting failure to happen and letting the user know when it does, you can give them a way to try again later. Do this, and you're already ahead of the average NCLC citizen developer.
A lot of tools like Power Automate have some built-in features for retry. If a workflow fails, there will be a log entry saying when and why it failed. A user can then hit the "retry" button and see if it works the second time. If you're aware of this feature in your NCLC platform, you can take full advantage of it without much extra effort.
⚠️ Warning: Watch out for retries that are automatic or too frequent. If the back-end service is already busy, 100 retries across your business team will not help. You can add a timer between attempts to make sure the server has some room to breathe.
Sometimes you might want to avoid repeating a task. Sometimes an application throws an error even though the task secretly succeeded behind the scenes. Imagine paying a bonus to Jerry 300 times because each attempt just looked like the payment failed. We'll talk about that kind of problem in more detail below.
Autonomous vs. Human-in-the-loop
We are discovering that when factories use robots and people together, those factories are more productive than ones that exclusively use either robots or people. Robots can do a lot of dangerous, tedious, and precise work, but they don't have the critical thinking to adjust their approach on the fly. It's also much easier to train a human to do a new job where robots need to be retooled by a specialist for each new task.
The same is true for NCLC apps.
Say you want to write a payments tool that sends wire transfers to your vendors. For safety's sake, you might want to find the sender's supervisor in the company directory and automatically ask for an approval before the wire is sent.
If you want to get more sophisticated, your second pass could look at details of the payment to see if it is statistically unusual, then send it for approval only if it looks strange. NCLC tools do have some interesting fraud prevention tools you can incorporate, even if they are challenging to understand. Again, it's best to combine automation with human intervention.
It's amazing how many problems disappear just by having a human take a second look.
CRUD vs. Commands and Events
With CRUD, we talked about the disadvantages of updating a record directly. What's better?
One good way is to make your app event driven. This simply means that you have your main record (like a salary in a database) and a separate kind of record called a command or event in a separate database.
In CRUD, you would change Jerry's salary directly: set salary to 80,000.
But now we don't know what his salary was before the change. What if we applied it by mistake? What if we want to reverse it?
Consider this alternative workflow:
Create an Update_Salary command record.
Set the values on the command record:
employee: Jerry
current_salary: 60,000
new_salary: 80,000
timestamp: today
requester: you
Justification: He knows too much.
completed: no (or empty)
Add this Update_Salary record to your command database.
A separate process...
- Picks up each command on a timer or a trigger.
- Makes the change in the payroll database.
- Marks the "done" field as "yes" (or sets a timestamp)
What you've effectively done is remove the RUD from CRUD.
Now you can reverse any change by creating a new command that swaps the current salary with the new salary values in the original command. You still have the original change, but now you're just adding a new record to undo it.
To be clear, you now have two separate command records -- the first change and the reversal. You have the whole history. It's a feed-forward system of change. If you are an accountant, you know exactly how this works. This is just like your general ledger.
If you're not an accountant, think about your bank account. Your statement doesn't just list a balance every month. Your balance is the product of a sequence of transactions that took place since your last statement.
TIP: Reversals are extremely important in finance. Every error correction must be done as a new entry in your ledger. Directly modifying ledger entries can put you in accounting or legal trouble.
You can create some very useful reports for your leadership if you have the full history of your data. Utilization statistics, workflow diagrams, and process efficiency statistics all emerge naturally from a list of actions taken. You might find out that Jerry is a star performer, completing various tasks in half the average time.
Exactly Once vs. At Least Once
We talked about retries earlier, but we didn't talk about how they come in a few flavors.
- At least once: Get today's latest bank account balance.
- Exactly once: Pay Jerry's salary
- At most once: Test the building's fire alarm
You'll mostly be dealing with at least once or exactly once scenarios.
At least once is the approach you take when you want to guarantee something happens, and it doesn't hurt to try again. In the salary example above, you're doing a straight update operation on Jerry's payroll in a way that's reversable. You can set your program to retry the change over and over. The only check you might want to do is whether his existing salary record is different from the current salary in the command record. Current salar is just telling your app what to expect, which means it can stop and call for help if the target value is unexpected.
Exactly once is used when you definitely don't want a change to apply twice. This usually happens when your command has some side effect in a system you don't control (like the bank's payment system). Repeating a command will drain your account very quickly.
Implementing exactly once is a little more challenging. For starters, each command must have a unique ID so your app can tell each one apart. The app that processes your commands must maintain its own database of completed IDs. It uses that list to prevent commands that were mistakenly retried from actually being run twice. Some NCLC platforms assign IDs like this automatically to each discrete record. Some make you do that work.
Let's build a paycheck workflow.
Your app sends the Send_Paycheck command to the processing app.
The processing app checks its list of completed pay command IDs.
If no completed record matches this command:
1. Send the paycheck request to your bank
2. Set the original Send_Paycheck command's status to "done"
3. Insert the ID for this message into the list of complete commands
Otherwise:
Skip running this command, but mark it as complete
The bank submits the payment.
Sometimes we call this a "journaling" operation. Hard drives in your computer work this way. They mark somewhere that it's going to write data, writes the data, then marks the data as written. If that final check is already marked complete when a retry is triggered, it just skips the retry.
You might notice that any one of these steps can fail, but the goal is to have a fail-safe check so the submitting application is not solely responsible for deciding when a task is complete. Just like human-in-the-loop, the task gets a second set of "eyes" before your app drains your bank account.
The final step to making something a exactly once operation is undoing all the previous steps when any step fails. SQL databases do this in what's called a transaction. The database will automatically keep track of each change and restore everything to its original state if one step fails. Some NCLC platforms support transactions for their databases, so it's wise to search around for this feature.
At most once is not as common. Why do something when nobody cares if it gets done?
But hey, there are always exceptions:
- Send a low-priority notification: "The cafeteria has lasagna today!"
- Test a system: Trigger the fire alarm when there's no fire.
- Optimize some data: Send an email summarizing the top ten action items for today.
None of these things strictly have to succeed, and you can always submit a new command to try again without breaking anything. If people learn about lasagna once, they're happy. If they learn about it twice+, they might mark you as spam. Otherwise, life moves on.
Regardless of you approach, it's always best think through the real-world consequences and have a fail-safe for humans to intervene.
Read-only vs. Read/Write
The simplest way to think about permissions in your application is this: most people can see the data, but some people can change it.
You may want to get more nuanced than that: some people can view some data while others can edit some data. Regardless, you always want to have at least two roles available.
NCLC platforms do wonders for managing this at the record and data field level, so take a look at whatever roles and permissions documentation your NCLC platform recommends.
Change management
For this segment, let's assume you have a working application. It's a hit. Suddenly you are "the guy who knows how the thing works."
That also means you're "the guy who knows how to change the thing." You will be getting a lot of change requests. Buildings apps might have been more of a hobby before. Now you're getting calls day and night to make it bigger and better in every way.
If that's the case... I'm sorry, and I hope you find some peace in your new role as a software engineer.
Change management is an exercise in meta-engineering. Just like how you don't just build a house without leveling the earth for a new foundation, you can't upgrade an app without thinking about the whole ecosystem.
Have separate environments
In professional software development, we almost always have two environments: one for testing, and one for real use.
Even better, you might find three environments:
- A development environment where you can break and fix anything
- A user acceptance testing environment where you test changes with your stakeholders before an upgrade
- A production environment where the real data runs
NCLC platforms usually only give you one by default, and extra environments can come with additional license fees.
The challenge with test environments is that you often have to "mockup" some downstream application. You don't actually want to move money or schedule nurses, but sometimes you can build a test service that acts like the real thing.
NCLC test environments do not handle this "mockup" scenario very well in many cases. Often, the only way to test it is through a real connection that might not have a test environment of its own. Sometimes you can mitigate this problem with something called a façade, where you make your test app dependent on something that simulates the back-end service without actually having to use it directly.
Test with pre-upgrade data
When updating your app, you will usually get caught on a very specific kind of bug: the old version expected your records to look one way, but the new version expects them to look another way. After the upgrade, your NCLC app is yelling at you because it can't read the payroll records when there's no "Is_Canadian" field. Sometimes it can't find that field because it's expecting that field to be misspelled, and somebody corrected the spelling.
I'll explain how to avoid this altogether, but a good start is to try your app against real production in a test environment before you roll it out more broadly.
Make upgrades reversible
Warning: This can be very hard. Some changes once done cannot be reversed. Think of multiplying two numbers together. Most of the time, figuring out which to numbers came together to make the third is an impossible task: there are just too many answers that could be correct.
When you change the structure of your records, it's best to have a back-out plan. Figure out how to upgrade your target data, but also have the "undo" process ready to go. Sometimes, building that "undo button" will even help you realize bugs you hadn't thought about before. Consider using a transactional upgrade process and making a backup before you publish a new version.
Prefer extension over modification
The easiest way to avoid an upgrade bug is to leave existing functionality completely unchanged. Don't so much as rename a misspelled field. This sounds counterintuitive, but it's very effective when making changes to your overall app.
Take a realistic example: If your job is to collection know-your-customer data for a new bank account, you might want to collect that data from your HR database. On the first pass, you might just have a field called "Is_US_Citizen" that you can use for filing FBAR reports later. This is totally fine.
Later, you find out the Canadian government is setting up their own FBAR. You realize your first field isn't flexible enough to distinguish between both countries.
Your first approach might be to replace the "Is_US_Citizen" field with a "Citizenship" field. Instead of true or false, now you store something like USA or Canada.
You change the fields on the database. Now your FBAR reporting app is broken because it wasn't expecting Is_US_Citizen to disappear. It doesn't know where to get the filter criteria for FBAR reports.
Instead, you can add Citizenship in addition to the existing Is_US_Citizen field. You're extending your records instead of modifying them. You can now update your database without breaking anything. Your app ignores the new field while using the old one.
Now you can update your app to take advantage of the new field. Better yet, you can leave the existing app untouched, clone it, and change the new app to use the new field. Now you have a better app, and one that you can use until it's no longer useful. Why would you do that? Maybe the upgrade is happening during the FBAR reporting period. US Citizens absolutely must file their reports right now, but your Canadians don't even know there's a new requirement yet. Canda can wait for Version 2 while you support Version 1.
At some point, you might want to clean up old fields so they don't accidentally get used for something new later, but for now, you can safely kick that can down the road.
De-bussing
The idea of "getting hit by a bus" is a pretty ubiquitous metaphor for sudden incapacitating change. I don't know if people outside software development refer to the act of mitigating this kind of risk as de-bussing, so if you've never heard that term before, welcome to the tech industry.
It can be hard to get someone to care about removing key person risk from an application she built. We assume someone else will handle it, or the app will figure things out on its own. Unfortunately, organizational change can happen suddenly, and NCLC solutions are terrible at handling this kind of situation.
For example, if you set up a Power App to connect to an OAuth API, it probably asked you for your personal credential. This means that if you wrote a payroll app, your credential might expire while you're on vacation. The app has no access to the data on its own, so payroll can't go out. You might say it feels like you just got hit by a bus. This makes for a very stressful vacation.
You should make sure there's at least one other person who understand how your app works and how to fix it. This can be as simple as resetting that human credential while you're out of office.
A better approach is to assign your application its own identity on the network. This can be more challenging in the NCLC world. Not all connections support an application credential (sometimes called a service principal). Your IT team might push back if it requires sharing an application password that doesn't expire and could get hacked. They'll want you to keep that on a need-to-know basis. That said, an application with its own credential usually continues working uninterrupted and without human intervention. You should rotate that credential on a regular basis so it can't be abused, but now you're in control of the schedule.
Security and accessibility are usually orthogonal goals. Speaking of which...
Security
Most NCLC tooling I've encountered is a mixed bag of good and bad security. Sometimes, the solution does a great job securing data by default. Most of the time, NCLC makes it really easy to use data in a very insecure way.
The app credential is a great example. Even if you set up a service principal to remove the expired human credential risk, that usually means managing a separate password according to your corporate compliance framework. I've worked with IT groups that won't even allow that kind of credential for this reason. It's just too scary to send a password to the HR team when it can be used to anonymously by anyone change data. It's a big risk.
I recall a time when a phishing attempt looked so realistic that my client asked me to share a connection string with a hacker thinking it was just another person in our organization. They sent a very simple email explaining they wanted to run some reports for an executive. Thankfully I caught the deception and reported it, but this kind of password sharing happens all the time in the real world.
Passwords can be managed securely using password managers or a cloud solution like Azure Key Vault. In NCLC tools, there is usually a carefully encrypted space where you can store passwords and your application can access them. They're kept in a way that only authorized humans and applications can see them. This also makes it easier to update a password -- changing the password in one place makes it available to all your apps at once.
It is a best practice to make each different person and app log in with a separate credential. This ensures that each operation is tied to a specific individual or process.
Considering which people actually need to modify data is crucial. In software engineering and IT, we follow what's called the principle of least privilege. We assume that each record and field is on a need-to-know basis, then we assign that field or record to a security group. If someone needs to see more, we can add her to the security group with more visibility. Your NCLC platform likely supports this out of the box.
I would advise against building NCLC apps as a public SaaS application for sensitive business data. Customers will want to have some guarantee that their data is not being stored in the same database as another customer, but this is challenging (if possible) to scale with NCLC tools. Most NCLC tools are designed on the assumption that you're building apps for internal use only. In the Power Apps world, you don't typically host your solution on everyone's behalf. You deploy that solution to the customer's own Power Platform subscription.
Performance
Your top priority is simple: get it working. Eventually, though, you might discover that your app is just too slow to be useful. How do you even start fixing it?
One of the main topics of a software engineer's education is around how to estimate the speed of her application. This is not measured in seconds or minutes, but using a technique we call Big O.
Big O is one of many tools we use for what we call complexity analysis. There are two main types: time complexity and memory complexity. Time complexity refers to how quick your process is, and memory complexity describes how much space on the computer you need to do it. These are often trade-offs, and you adapt your solution to meet the constraints of your computer.
Why estimate complexity instead of time? Because the same code can take longer to run on a wimpier computer or on a larger data set. Complexity is a constant, and we can compare one algorithm's complexity to another.
Big O can be visualized using graphs that draw the function relative to the number of records being processed.
Imagine you have a sorted list of employees by name. You want to find the first one. Checking the top of that list just takes one operation every time, so we call that O(1) or constant time.
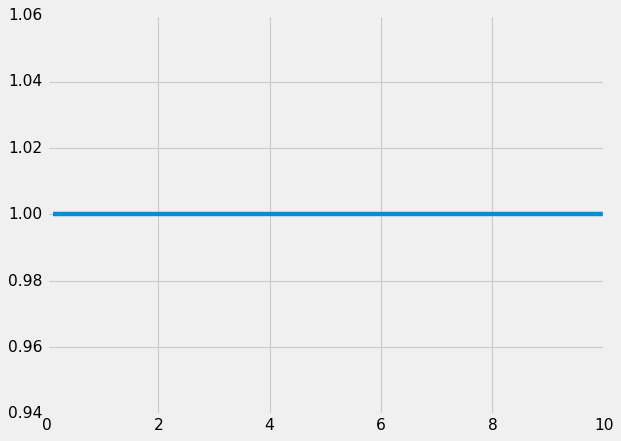
If instead you're sending a notification email to every employee in your HR database, that would be...
1 email x each employee = O(1 * n) = O(n).

Already, you can see the difference that is y = 1 vs. y = n. One is flat and the other is going up and to the right in a straight line.
For comparison, sending a personalized email to introduce each pair of employees to each other would be something like this...
(1 email * 1 employee * all employees except the first)
*
(all remaining employees)
---
O(1 email * (n employees * (n - 1) * (n - 2) * (n - 3)))
---
O(n!)
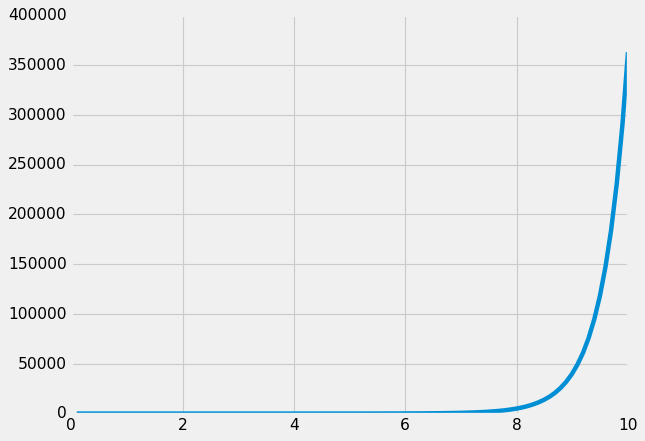
Looking at graphs for the functions y = n vs y = n!, the difference is obvious. Adding one new employee has very different effects on how many operations happen with each approach. Same data, very different complexity.
Sometimes, complexity analysis results in some surprises. Getting the fastest route from home to work (like you would on your smartphone) is a pretty quick algorithm. The complexity is O(E * log(V)) where E is the total number of paths on your map and V is the total number of destinations. This is harder to visualize mentally, but the graph is three dimensional with three axes: operations, destinations, and paths.
Knowing that, you might be surprised to find out that the fastest route between all destinations and back is incomprehensively slow. The traditional example is called the travelling salesman problem. Think Santa on Christmas Eve. We call this a nondeterministic polynomial class of problem, or NP for short. Even Santa can only run that kind of calculation once a year, and he's magic!
If Santa is ok with a close-enough solution, we can use algorithms like simulated annealing to get to a decent answer much faster. We call algorithms that are just good enough heuristics. Sorry to say, simulated annealing is probably not available to you on an NCLC platform. If you want it, you usually have to hire a data scientist to create a custom implementation for you.
Other heuristics are slow but easy to implement. An optimized algorithm for getting from Seattle to Florida will give you the shortest route, but you can also just tell someone to drive east until they hit an ocean, then start driving south. It's a bad heuristic -- but hey, any port in a storm.
Some problems literally can't be computed at all. These are called undecidable, a term we pull from mathematics. A common example is the halting problem, which seems simple: Can you write a program that can tell you if another program is going to stop or go on forever?
The answer is mathematically proven to be no. It is impossible to write a program that can tell, in general, if another program will stop (or halt). Good luck explaining that to your boss. Maybe try sending her the Halting Problem Wikipedia article.
In practice, most solutions in a function like HR or Finance are going to be between O(n) and O(n2). Examples include summing a list of transactions or combining a list of email addresses with a list of employee numbers. It's rare to solve an energy optimization problem like Santa, but it can happen. Keep that in mind if you work in logistics or some kind of scheduling role.
Most NCLC platforms will have some optimizations you can use to speed things up. Maybe your app will run a little faster if it's sorted. Maybe you can apply an index to make lookups quicker. Maybe you'll realize you're processing each record twice for no reason. Sometimes, you'll discover a new algorithm to do the same work in half the time.
In the end, you're not using an NCLC platform because it's the fastest way to run a program. You're using it because it's faster than Jerry (who quit last week.)
Other Bugs
Most bugs are the result of a difference between how the developer thinks the world works and how it actually works. Even if you happen to be a domain expert in finance, law, or medicine, you'll be surprised at just how many things can go wrong.
I can't do them all justice, but one of the most helpful resources I've found is this list of "awesome falsehoods". This is a curated list of articles describing everything from calendars to human identity.
Closing thoughts
If you've gotten this far, you're well on your way to making something really valuable for your team. No app is perfect, but some apps are useful. That's your goal.
I would love to hear what you're building and help any way I can. I'm not an expert on any platform, but I've been doing this a while and it brings me great joy to see people learn and build new things.
Further Reading
SOLID Principles
Awesome Falsehoods
Event-driven architecture
Image by Dominik Scythe via Unsplash.
Posted on January 19, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related