O que aprendi no meu primeiro projeto com análise exploratória de dados

Mariana
Posted on February 2, 2022
No final do mês de setembro de 2021, iniciei o curso de Data Analytics na Tera. Neste texto, vou contar um pouco sobre o primeiro projeto que desenvolvi durante o curso.
O projeto chama-se EDA: Análise exploratória de dados. Logo no título, já senti muita vontade de finalmente colocar a mão na massa e mexer nos dados, criar gráficos, olhar para os números. Confesso que essa ansiedade inicial atrapalhou um pouco, mas, a partir disso, tive um dos maiores aprendizados que este projeto poderia me trazer e que colocam os números como coadjuvantes. Adiante, falarei mais sobre esses aprendizados.
Esse projeto trazia três datasets previamente definidos, que continham dados do lançamento de jogos de videogame nos últimos 40 anos. O intuito era embasar a tomada de decisão de uma empresa que pretende lançar um novo jogo para dispositivos mobile (Android e iOS). Alguns aspectos que deveriam ser levados em consideração e analisados antes do lançamento: o gênero do jogo (esportes, luta, aventura), em qual plataforma havia sido lançado (Nintendo, Xbox, etc), o potencial de vendas por localização geográfica e a crítica que o jogo recebeu.
O dataset
Antes de limpar os dados, calcular média, mediana, desvio padrão ou conseguir plotar um gráfico em Python pela primeira vez, o entendimento do problema precisa estar bem evidente. Esta que é a primeira etapa parecia algo simples de compreender, entretanto, com o avançar das etapas e com o aumento da complexidade do projeto, esse entendimento vai se juntando aos insights e fica fácil esquecer qual é realmente o problema a ser resolvido. Tudo começou a se misturar na minha cabeça!
Para desenvolver o projeto eu possuía três datasets e nenhuma regra quanto a qual tecnologia utilizar para fazer a análise dos dados. Eu já havia estudado Python e a biblioteca Pandas antes do curso, então minha primeira decisão foi utilizar essa ferramenta para resolver o desafio. Seria um ótimo momento para praticar o que eu já havia estudado antes 🐼.
A aventura começou com a importação dos dados para o Google Colab. O que parecia um primeiro passo óbvio demais, não foi tão fácil assim. Utilizando Pandas, parecia simples assim abrir um arquivo csv:

Precisei pesquisar muito e até duvidei da qualidade dos dados que eu tinha — afinal, o roteiro do projeto me levou a crer que os dados do primeiro dataset não eram tão “bons” assim. Depois de várias tentativas erradas, de quase desistir logo no começo por não conseguir simplesmente importar o meu arquivo, de pensar que no Excel eu não estaria passando por esse perrengue, eu finalmente consegui importar o meu arquivo! Para isso, importei o arquivo do Drive, e não de uma pasta no meu computador, e também adicionei o encoding. A documentação oficial da biblioteca Pandas me auxiliou muito aqui.

Dados importados! Depois dessa primeira conquista, a vontade de mexer nos dados só aumentava. E aqui cada vez mais eu me distanciava do problema que eu precisava resolver, os dos insights que eu precisaria ter ao final da análise. Nessa empolgação, consegui utilizar alguns comandos do Pandas e continuei seguindo com o roteiro proposto.
Os datasets em questão traziam informações sobre games, data de lançamento dos jogos, e vendas ao redor do mundo (América do Norte, Europa, Japão e outros lugares).
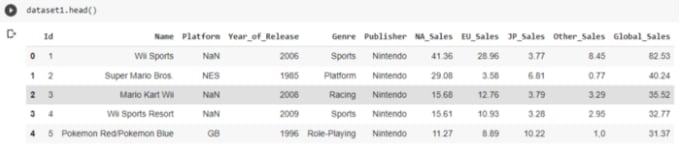
Ao olhar para os dados, a primeira dúvida que tive foi em relação às colunas de sales: aqueles números eram a quantidade em dinheiro dos jogos vendidos? Ou eram a contagem de jogos vendidos? Anotei essa dúvida e segui com o roteiro do projeto. Então, um importante passo foi construir um dicionário das colunas, e entender do que se tratavam aqueles valores. Entender o contexto é um passo fundamental para se fazer antes de qualquer análise de dados.
O dataset 3 possuí algumas informações diferentes, como a avaliação dos clientes sobre os games.
Alguns outros apontamentos que pude perceber: havia alguns valores nulos, algumas linhas repetidas, e valores em número mas com as colunas com tipo não numérico. Neste ponto ficou ainda mais evidente que, principalmente no dataset 1, havia vários problemas. No roteiro proposto para o projeto ainda viria a etapa de limpeza dos dados. Além disso, algumas dúvidas sobre a origem destes dados, pois como eu recebi o dataset pronto, não sabia quem tinha coletado esses dados, quem tinha respondido às avaliações sobre os games, de onde vinham as notas das críticas (de sites? das próprias empresas que publicam os jogos?).
A responsabilidade com a manipulação e limpeza dos dados foi aumentando conforme fui evoluindo com o projeto. Qual valor atribuir para a coluna de valores nulos? Eu poderia simplesmente apagar as linhas com valores duplicados? Quais inconsistências haviam nesses dados? Eu sabia que para que as análises tivessem valor, os dados deveriam ser os mais confiáveis possíveis. Como eu saberia que a limpeza que eu havia feito nos dados estava boa o suficiente para poder fazer análises? Apesar das incertezas e angústias, continuei com o roteiro, sempre tomando nota do que eu já havia observado.
Cheguei então na parte dos gráficos. Eu nunca tinha feito um gráfico no Python. Já tinha ouvido falar de algumas bibliotecas que serviam para isso, mas nunca tinha de fato construído os meus próprios gráficos. Decidi estudar a biblioteca Matplotlib, e cansei de me deparar com diferentes tipos de erros. Eu não entendia nem sequer o que estava acontecendo de errado, e decidi, então, que precisava estudar mais ainda sobre os tipos de gráficos e sobre outras bibliotecas. Nesse movimento, descobri as bibliotecas Seaborne e Plotly, e, finalmente, consegui fazer meu primeiro gráfico utilizando Python:
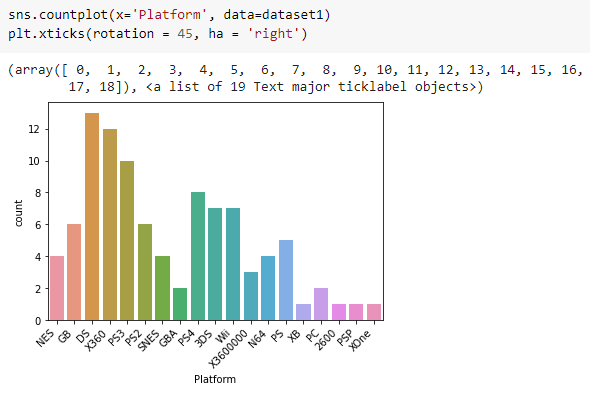
Até aqui
Depois dessa jornada, percebi que conseguia utilizar as ferramentas para mexer com os dados, que pesquisando e tentando executar comandos eu conseguiria fazer aparecer alguma coisa na tela. Mas este não foi o grande aprendizado aqui. Sem dúvidas melhorei o meu domínio sobre a biblioteca Pandas e adorei ter me desafiado e feito meus primeiros gráficos com Python. Sigo cada dia mais encantada com a potencialidade dessa linguagem de programação e como em poucas linhas de código muita coisa pode ser exibida.
Outro grande aprendizado foi o de compreender a importância de cada uma das etapas do ciclo analítico. Há diversas metodologias envolvidas quando se trata de ciclo analítico. Aqui, trarei o exemplo da CRISP-DM (Cross Industry Standard Process for Data Mining).
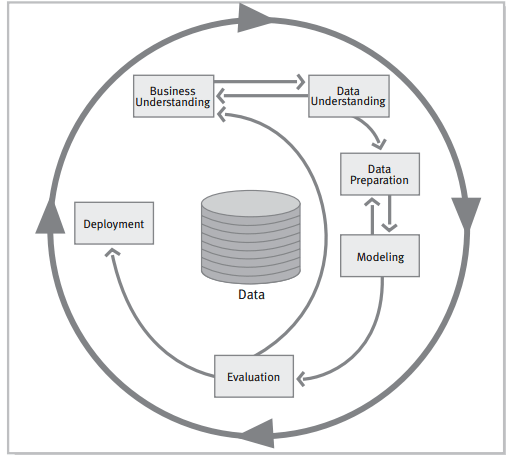
Fonte: Guide CRISP-DM 1.0 (https://the-modeling-agency.com/crisp-dm.pdf)
Os dados são o centro da imagem, e também o centro de todas as análises. Por conta disso, é importante que os dados tenham qualidade para que as análises possam ter algum valor. Essa também foi uma importante compreensão que veio com o desenvolvimento do projeto: aqui era minha a responsabilidade de garantir a qualidade, modelar e manipular, utilizar técnicas como o tidy data, antes de escrever qualquer linha de código no Python.
E o problema?
Depois de várias horas escrevendo comando no Colab e tentando fazer gráficos, eu precisei voltar ao início do roteiro do projeto e relembrar alguns pontos importantes. O que havia sido proposto era uma uma análise exploratória de dados dos lançamentos de jogos de videogame nos últimos 40 anos. E, a partir disso, tomar decisões para lançar um novo jogo mobile.
De acordo com o que eu havia observado dos dados até então, alguns pontos ficaram evidentes: a quantidade de jogos lançados havia aumentado consideravelmente em relação aos primeiros lançamentos, no início dos anos 1980. Os datasets compreendiam um período de tempo dos anos 1980 até 2016.
Outra questão que se destacou foi em relação ao domínio da Nintendo em relação às outras empresas que também lançam jogos. Dentre o gênero dos jogos, a maioria se encontra nos jogos de tiro, enquanto os jogos de aventura possuem os valores mais baixos. Com relação às vendas, a América do Norte tem os maiores números em relação aos outros lugares do mundo. Com isso, me pareceu uma boa sugestão a ser indicada focar nos lugares onde as vendas não são tão consolidadas quanto na América do Norte. E também diversificar para outras empresas que disponibilizam games, e não focar somente na Nintendo, que já possui um domínio das vendas. Contudo, lançar o jogo na América do Norte poderia garantir sucesso de vendas do novo game, e a partir daí novos mercados poderiam sem ganhos, pois o jogo já seria conhecido.
Porém, para melhor responder o desafio proposto, senti falta de algumas informações, que teriam sido bastante úteis para a análise. Os datasets traziam dados apenas referentes à mídias físicas, e não havia nenhum tipo de informações sobre games no formato mobile. Além disso, os dados não estavam no formato granular, portanto não havia como identificar o perfil dos usuários que consomem games e fazem avaliações. Também não há informações quanto à receita, como o quanto de dinheiro foi arrecadado com a venda dos games.
Conclusões
Foi bastante desafiador receber os datasets, fazer a limpeza dos dados e tirar insights a partir do que havia sido proposto. Juntar colunas, refletir sobre os valores nulos e compreender os erros nos valores foram os principais pontos onde senti alguma dificuldade.
Fazer um dicionário das colunas me ajudou bastante na compreensão do dataset. A coluna de sales gerou dúvida no começo, e compreendi que os números significavam a quantidade de vendas, e não a quantidade de dinheiro.
Aprendi também que mais perguntas vão surgindo ao longo do caminho, e que é importante anotar todos os insights para no final relembrar o que foi pensado e tentar fazer novas conexões.
Colocar em prática tudo o que eu já havia estudado até então foi muito interessante. Sem dúvidas, compreender o dataset e o contexto foram as partes mais importantes da resolução do desafio. Além disso, também foi fundamental ter responsabilidade no momento de limpar os dados, visando garantir qualidade para que as análises pudessem ser feitas em cima de dados corretos.
Pude vivenciar a responsabilidade ao tratar os dados, e, com base nas minhas análises, sugerir ou não o lançamento de um produto. Ficou evidente a importância de todas as etapas até chegar no momento da tomada de decisão. E pude ver na prática a importância do contexto, para que de maneira responsável eu pudesse olhar para a fonte dos dados, compreender os significados e garantir a qualidade. Acredito que estas etapas fazem parte da rotina de um analista de dados, e esta foi uma ótima oportunidade de treino!
Para acessar o projeto de análise de dados, clique aqui!
Posted on February 2, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
