10 Machine Learning Algorithms to Know in 2024

Manka Velda
Posted on February 29, 2024
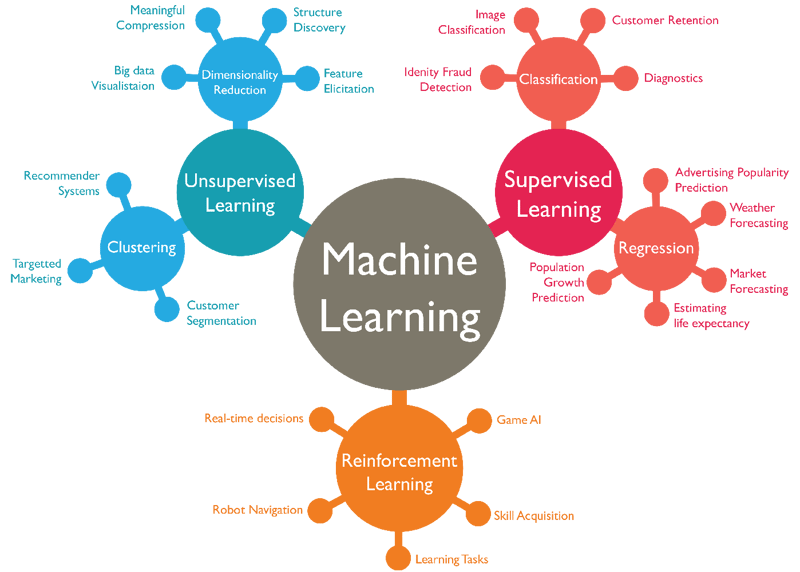
What is a machine learning algorithm?
A machine learning algorithm consists of rules or processes employed by an AI system to perform tasks, commonly to uncover new insights and patterns in data or predict output values based on a specific set of input variables. These algorithms empower machine learning (ML) systems to acquire knowledge.
Machine learning algorithms can be categorized into various types, including supervised learning, unsupervised learning, and reinforcement learning. Each type of algorithm is designed to tackle different types of problems and learning scenarios.
Supervised learning algorithms learn from labeled training data, where each data point is associated with a known output or target value. These algorithms aim to build a model that can map input variables to the correct output values.
Unsupervised learning algorithms, on the other hand, work with unlabeled data, where the algorithm explores the data's underlying structure and identifies patterns or clusters without predefined target values. These algorithms are useful for tasks such as data clustering, anomaly detection, and dimensionality reduction.
Reinforcement learning algorithms learn through interaction with an environment. They receive feedback in the form of rewards or penalties based on their actions. The algorithms aim to learn the optimal behavior or policy that maximizes the cumulative rewards over time.
How machine learning algorithms function
According to a research paper from UC Berkeley, the learning process of a machine learning algorithm can be divided into three key components.
1. Decision process: Machine learning algorithms are primarily employed to make predictions or classifications. Given a set of input data, which may or may not be labeled, the algorithm generates an estimation regarding patterns or relationships within the data.
2. Error function: An error function is utilized to assess the accuracy of the model's predictions. If there are known examples available, the error function compares the model's output to the actual values, determining the extent of any discrepancies.
3. Model optimization process: To enhance the model's alignment with the training data, the algorithm adjusts the weights associated with different features or parameters. By reducing the gap between the model's estimated values and the known examples, the algorithm iteratively refines its performance. This iterative process of evaluation and optimization continues until a predefined threshold of accuracy is achieved.
Types of machine learning algorithms
A. Supervised learning algorithms
Supervised learning can be separated into two types of problems: classification and regression.
- Classification
Classification uses an algorithm to accurately assign test data into specific categories. It recognizes specific entities within the dataset and attempts to draw some conclusions on how those entities should be labeled or defined. Common classification algorithms are linear classifiers, support vector machines (SVM), decision trees, K-nearest neighbor and random forest, which are described in more detail below:
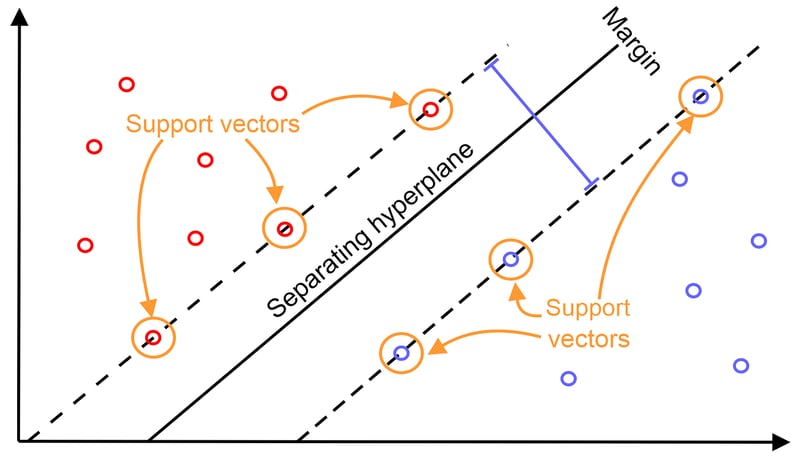
1. Support vector machine (SVM)
The support vector machine (SVM) is a supervised learning algorithm widely used for classification and predictive modeling tasks. One of the notable advantages of SVM is its ability to perform well even when the available data is limited.
SVM algorithms operate by constructing a decision boundary referred to as a "hyperplane." In a two-dimensional setting, this hyperplane resembles a line that segregates two sets of labeled data points. The primary objective of SVM is to identify the optimal decision boundary by maximizing the margin between these two classes. It seeks to find the widest gap or space that separates the data points.
Any new data point falling on either side of the decision boundary is classified based on the labels present in the training dataset. SVM can handle more intricate patterns and relationships in the data by utilizing hyperplanes that can exhibit diverse shapes when represented in three-dimensional space. This flexibility allows SVM to effectively handle complex classification scenarios.
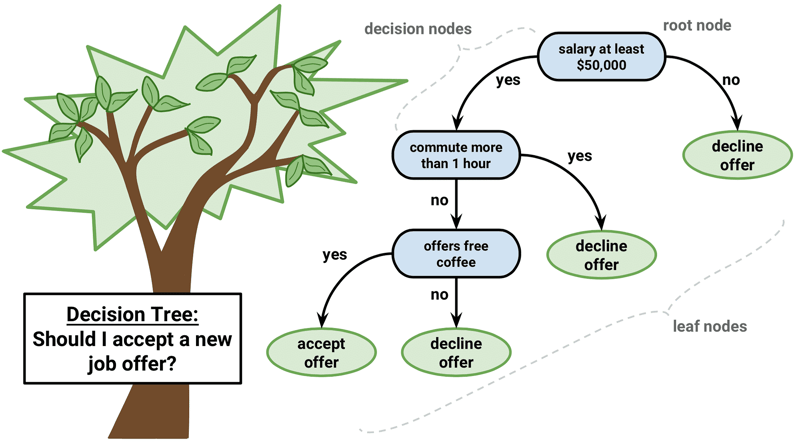
2. Decision tree
A decision tree is a supervised learning algorithm utilized for classification and predictive modeling tasks. It takes the form of a flowchart-like structure, beginning with a root node that poses a specific question about the data. Depending on the answer, the data is directed along different branches to subsequent internal nodes, which present further questions and guide the data to subsequent branches. This process continues until the data reaches a leaf node, also known as an end node, where no further branching occurs.
Decision tree algorithms are highly favored in machine learning due to their ability to handle complex datasets with simplicity. The algorithm's structure makes it easy to comprehend and interpret the decision-making process. By sequentially asking questions and following the corresponding branches, decision trees allow for classification or prediction of outcomes based on the data's characteristics.
The simplicity and interpretability of decision trees render them valuable in a wide range of machine learning applications, particularly when dealing with intricate datasets.
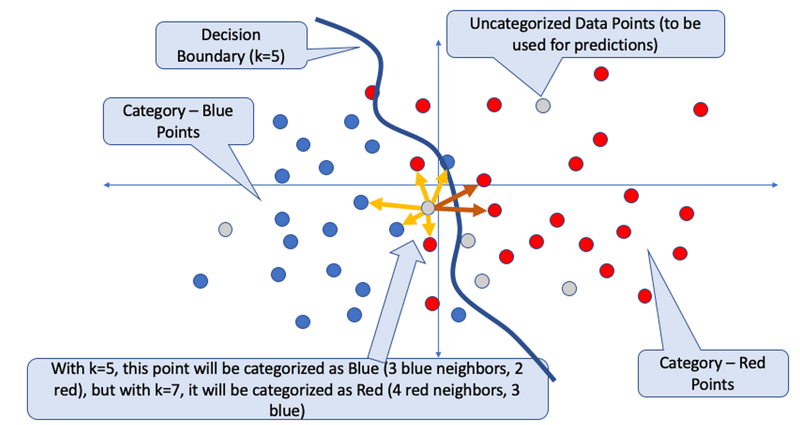
3. K-nearest neighbor (KNN)
The K-nearest neighbor (KNN) algorithm is a type of supervised learning method commonly used for tasks like classification and predictive modeling. It determines the classification of a data point by considering its proximity to other points on a graph.
Let's imagine we have a dataset with labeled points, some marked as blue and others as red. When we want to classify a new data point, KNN examines its closest neighbors on the graph. The value of "K" in KNN represents the number of nearby neighbors taken into account. For example, if K is set to 5, the algorithm considers the 5 closest points to the new data point.
By looking at the labels of the K nearest neighbors, the algorithm assigns a classification to the new data point. If most of the closest neighbors are blue points, the algorithm classifies the new point as belonging to the blue group.
Moreover, KNN can also be utilized for prediction tasks. Instead of assigning a class label, it estimates the value of an unknown data point by calculating the average or median value of its K nearest neighbors.
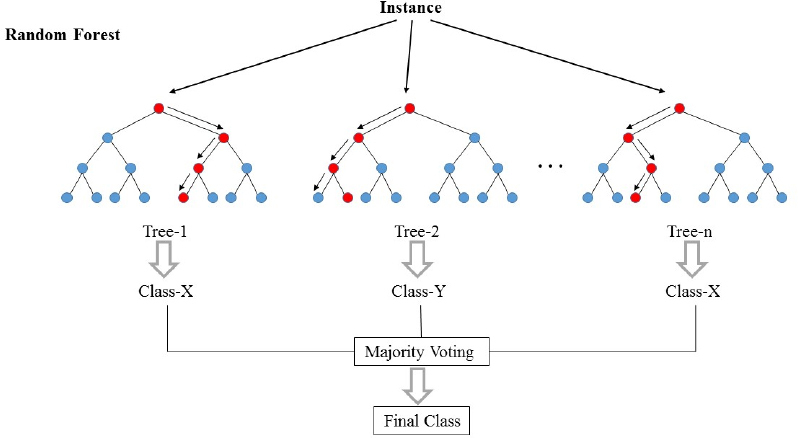
4. Random forest
A random forest algorithm is a collection of decision trees used for classification and predictive modeling. Instead of relying on a single decision tree, a random forest combines the predictions from multiple decision trees to enhance accuracy.
In a random forest, numerous decision trees (sometimes hundreds or even thousands) are trained individually using different random samples from the training dataset. This sampling technique is known as "bagging." Each decision tree is trained independently on its own random sample.
After training, the random forest takes the same data and inputs it into each decision tree. Each tree generates a prediction, and the random forest counts the results. The prediction that appears most frequently among all the decision trees is chosen as the final prediction for the dataset.
Random forests address a common challenge called "overfitting" that can occur with individual decision trees. Overfitting happens when a decision tree becomes too closely aligned with its training data, causing reduced accuracy when presented with new data.
5. Naive Bayes
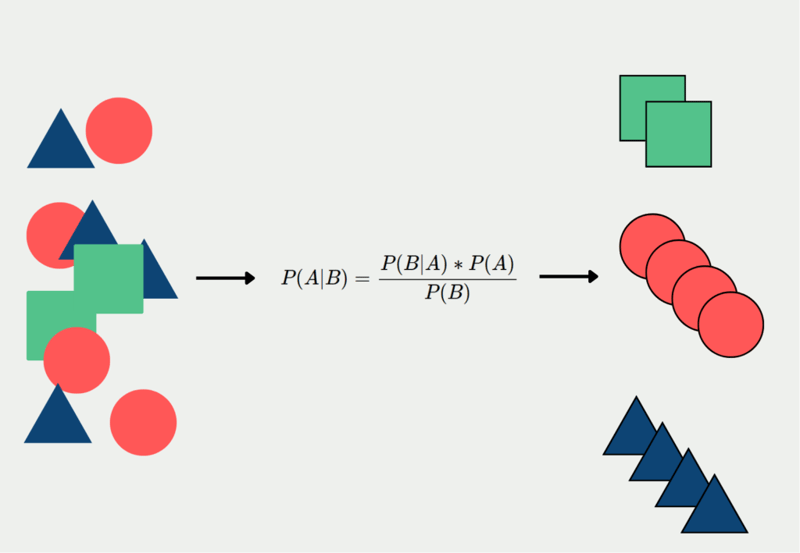
Naive Bayes is a group of supervised learning algorithms utilized for creating predictive models in binary or multi-classification tasks. It is based on Bayes' Theorem and operates by using conditional probabilities to estimate the likelihood of a classification, assuming independence between the factors involved.
To illustrate, let's consider a program that identifies plants using a Naive Bayes algorithm. The algorithm takes into account specific factors such as perceived size, color, and shape to categorize images of plants. Although each of these factors is considered independently, the algorithm combines them to assess the probability of an object being a particular plant.
Naive Bayes exploits the assumption of independence among the factors, simplifying the calculations and enabling efficient processing of large datasets. It is particularly effective for tasks like document classification, email spam filtering, sentiment analysis, and various other applications where the factors can be evaluated separately but still contribute to the overall classification.
- Regression
Regression is used to understand the relationship between dependent and independent variables. It is commonly used to make projections, such as sales revenue for a given business. Linear regression and logistical regression are popular regression algorithms.
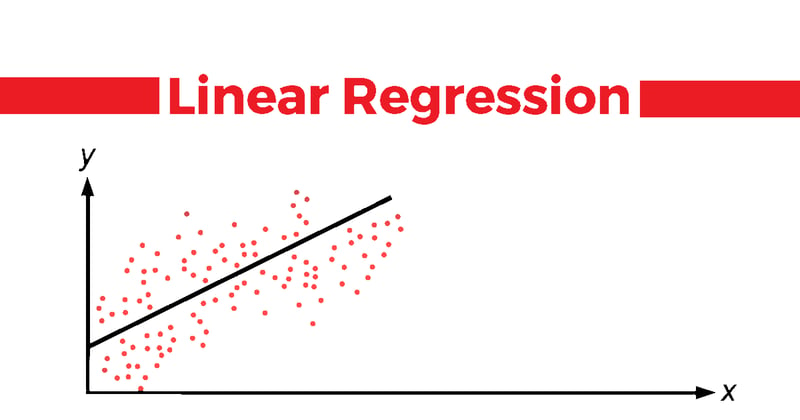
6. Linear regression
Linear regression is a supervised machine learning technique employed for predicting and forecasting values that fall within a continuous range, such as sales numbers or housing prices. It is a statistical technique that establishes a relationship between an input variable (X) and an output variable (Y) that can be represented by a straight line.
In simpler terms, linear regression takes a set of data points with known input and output values and determines the line that best fits those points. This line, called the "regression line," serves as a predictive model. By utilizing this line, we can estimate or predict the output value (Y) for a given input value (X).
Linear regression is primarily used for prediction purposes rather than classification. It is valuable when we want to comprehend how changes in the input variable impact the output variable. By examining the slope and intercept of the regression line, we can gain insights into the relationship between the variables and make predictions based on this understanding.
7. Logistic regression
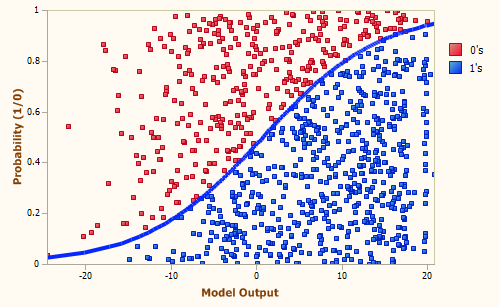
Logistic regression, also known as "logit regression," is a supervised learning algorithm primarily utilized for binary classification tasks. It is commonly applied when we need to determine whether an input belongs to one class or another, such as determining whether an image is a cat or not a cat.
Logistic regression predicts the probability that an input can be classified into a single primary class. However, in practice, it is often used to divide outputs into two categories: the primary class and not the primary class. To achieve this, logistic regression establishes a threshold or boundary for binary classification. For instance, output values between 0 and 0.49 might be classified as one group, while values between 0.50 and 1.00 would be classified as the other group.
As a result, logistic regression is commonly employed for binary categorization rather than predictive modeling. It enables us to assign input data to one of two classes based on the probability estimate and a predefined threshold. This makes logistic regression a powerful tool for tasks such as image recognition, spam email detection, or medical diagnosis, where we need to categorize data into distinct classes.
B. Unsupervised learning algorithms
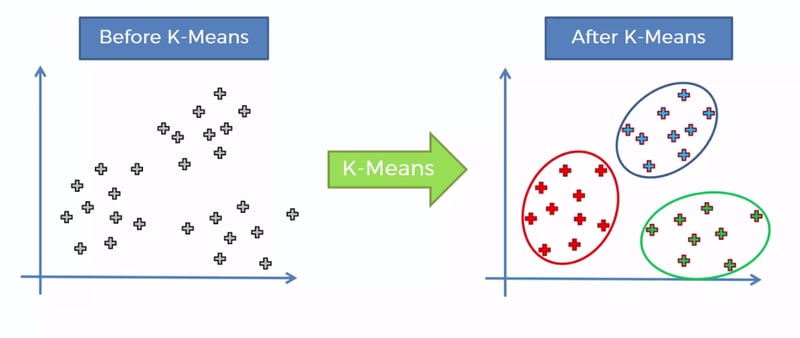
8. K-means
K-means is an unsupervised learning algorithm that is commonly used for clustering and pattern recognition tasks. Its objective is to group data points based on their proximity to one another. Similar to K-nearest neighbor (KNN), K-means clustering relies on the concept of proximity to identify patterns in the data.
In K-means clustering, the algorithm partitions the data into a specified number of clusters, where each cluster is defined by a centroid. A centroid represents the center point of a cluster, either real or imaginary. The algorithm iteratively assigns data points to the cluster whose centroid is closest to them and updates the centroids based on the newly assigned points. This process continues until convergence, where the centroids stabilize and the clustering is considered complete.
K-means is particularly useful for large datasets as it can efficiently handle a large number of data points. However, it can be sensitive to outliers, as they can significantly impact the position of the centroids and the resulting clusters.
Clustering algorithms, such as K-means, provide valuable insights into the inherent structure of the data by grouping similar points together. They have various applications in fields like customer segmentation, image compression, anomaly detection, and more.
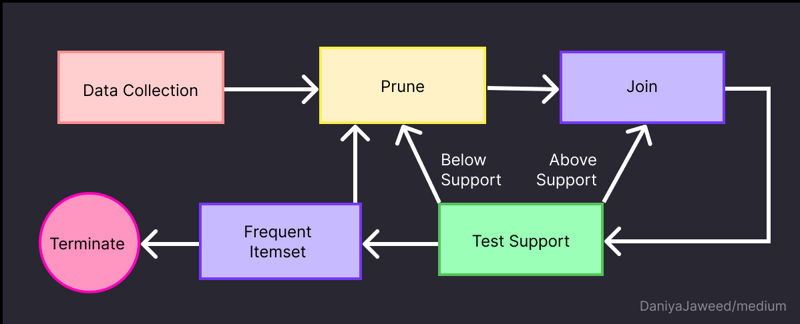
9. Apriori
Apriori is an algorithm primarily used for association rule mining, which is a branch of unsupervised learning. It is commonly employed in pattern recognition and prediction tasks, particularly for understanding associations between different items in a dataset.
The Apriori algorithm was first introduced in the early 1990s as a method to discover frequent itemsets and generate association rules. It operates on transactional data stored in a relational database. The algorithm identifies sets of items that frequently co-occur together in transactions, known as frequent itemsets. These itemsets are then used to generate association rules that describe the relationships between items.
For instance, if customers often purchase products A and B together, the Apriori algorithm can mine this association and generate a rule that suggests "If a customer buys product A, they are likely to buy product B as well."
By applying the Apriori algorithm, analysts can gain valuable insights from transactional data and make predictions or recommendations based on the observed patterns of itemset associations. It is commonly used in various domains, such as market basket analysis, customer behavior analysis, and recommendation systems.
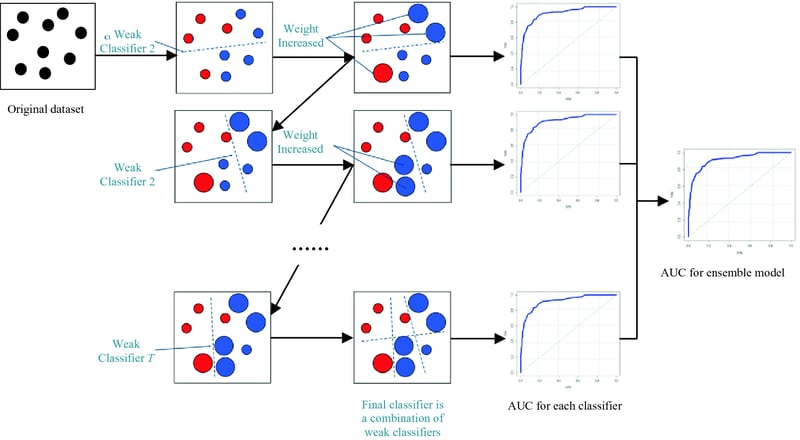
10. Gradient boosting
Gradient boosting algorithms employ an ensemble method, where a sequence of "weak" models is created and iteratively improved to form a strong predictive model. This iterative process gradually reduces errors and leads to the generation of an optimal and accurate final model.
The algorithm begins with a simple, naive model that may make basic assumptions or predictions, such as classifying data based on a simple threshold or rule. This initial model acts as a starting point for the ensemble.
In each iteration, a new model is built to focus on correcting the mistakes made by the previous models. The algorithm identifies the patterns or relationships that were not adequately captured before and incorporates them into the new model. The new model is trained to predict the remaining errors or residuals from the previous models.
By iteratively adding new models and adjusting their predictions based on the errors of the previous models, gradient boosting effectively addresses complex problems and large datasets. It has the capability to capture intricate patterns and dependencies that may be missed by a single model. By combining the predictions from multiple models, gradient boosting produces a powerful predictive model that can make accurate predictions on unseen data.
ML Algorithm Snapshot
| Algorithm | Type | Main Application | Key Features |
|---|---|---|---|
| Support Vector Machine (SVM) | Supervised Classification | Image Recognition, Predictive Modeling | Creates a hyperplane to separate labeled data, effective with small datasets, handles complex patterns. |
| Decision Trees | Supervised Classification | Predictive Modeling, Decision Making | Flowchart-like structure, handles complex datasets, easy to interpret. |
| K-nearest Neighbor (KNN) | Supervised Classification | Classification, Predictive Modeling | Classifies based on proximity to neighbors, flexible and simple. |
| Random Forest | Supervised Classification | Predictive Modeling, Classification | Ensemble of decision trees, reduces overfitting, high accuracy. |
| Naive Bayes | Supervised Classification | Text Classification, Spam Detection | Probability-based, assumes independence of features, efficient processing. |
| Linear Regression | Supervised Regression | Sales Forecasting, Prediction | Establishes a relationship between variables, simple and interpretable. |
| Logistic Regression | Supervised Regression | Binary Classification, Medical Diagnosis | Predicts probability of input belonging to a class, effective for binary tasks. |
| K-means | Unsupervised Clustering | Customer Segmentation, Anomaly Detection | Groups data points based on proximity, useful for large datasets. |
| Apriori | Unsupervised Association | Market Basket Analysis, Recommendation | Discovers frequent itemsets, generates association rules. |
| Gradient Boosting | Ensemble Method | Predictive Modeling, Large Datasets | Iteratively improves weak models, effective for complex problems and patterns. |
To Conclude,
Machine learning algorithms are crucial tools in the field of artificial intelligence and data science. The top 10 algorithms we explored in this article offer a diverse range of capabilities and applications. From linear regression to decision trees, support vector machines, random forests, and gradient boosting, these algorithms enable us to analyze complex data, make predictions, and gain valuable insights. Staying updated with advancements in machine learning is crucial to harnessing its potential for solving real-world problems and driving innovation in various industries. With the power of these algorithms, we can make informed decisions and shape a smarter, data-driven future.😃
Posted on February 29, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



November 29, 2024
