HDFS - Hadoop Distributed Filesystem

maninekkalapudi
Posted on July 23, 2022
Hello! Hope you're doing well. In my last post I've shared a 10,000 feet overview of Data Engineering with Spotify as an example. From that post we understood that storage is a very crucial component in the Data Engineering world. Now, in this post we'll discuss about Hadoop Distributed Filesystem (HDFS) and understand how a distributed system works on a very high level as a developer. Alright, Let dive in!
Topics covered in this post
- What is HDFS?
- Why do we need a cluster of machines?
- HDFS Concepts
- HDFS Architecture
- DataNode Failure
- Standby NameNode and NameNode Failure
- NameNode- High Availability
- Rack Awareness
- HDFS Commands
- Conclusion
1. What is HDFS?
HDFS is a distributed storage with a cluster of machines working together and it is meant to store huge data in the form of files. The cluster is made up of commodity hardware and can be obtained by any of the vendors like any cloud providers.
Now, let's understand each of the terms mentioned above one by one:
- Distributed- As the data grew exponentially in recent times, there is no way we could store all of it on a single machine. To store the massive data, we need a group of machines which are connected over the network, and they will work together in coordination.
- Huge data- The data in the order of terabytes or more.
- Commodity hardware- The cluster will be made of inexpensive hardware and individual machines in the cluster are prone to failure. HDFS is built to carry on without any interruption to the users and a new node will be created in case of a failure.
2. Why do we need a cluster of machines?
Because we cannot store ever increasing data on a single machine. So, why not a very large machine? Here is a simple fact.
In monolith systems (single machine), when we double the amount of resources (CPU, RAM etc.) of a machine the performance will only double up to a certain point and then it diminishes. Whereas in distributed systems when we double the amount of resources the performance will increase roughly by two times.
In pioneer days they used oxen for heavy pulling, and when one ox couldnt budge a log, they didnt try to grow a larger ox. We shouldnt be trying for bigger computers, but for more systems of computers. Grace Hopper
The above quote will provide the best idea of what we discussed earlier. The conclusion here is we need a cluster to store and process massive data. But how are going to manage the cluster? This well be fully managed by the Hadoop out of the box, and we'll discuss about the specifics of cluster management in a later post. On to the storage now.
3. HDFS Concepts
a. Blocks
The HDD/SSD in a typical computer stores the data in blocks. A block is the minimum amount of data that the HDD/SSD can read or write at a time. Usually, it is 512 bytes for a drive. HDFS also has the concept of blocks. The default block size in HDFS is 128MB.
Every file, regardless of its size, will be broken down into chunks of 128 MB. This is as shown below:
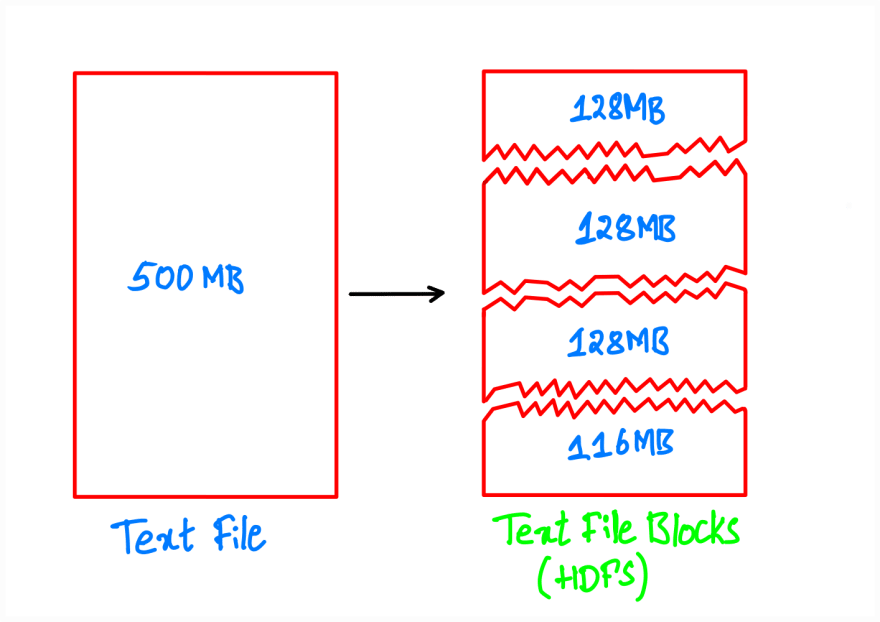 Blocks in HDFS
Blocks in HDFS
As seen in the above image, each file will be divided into blocks of 128MB. For example, 500MB file will have 4 partitions (3x128MB+116MB). Later each block will be stored on a different machine in the cluster to avoid the data loss in case of a machine failure.
This model helps us to manage the files in terms of blocks and are easy to store and manage across machines in the cluster.
b. NameNode
The HDFS cluster has a Master-Worker architecture. NameNode is the master node and DataNodes are the worker nodes in cluster. The NameNode manages the filesystem namespace and the metadata for the cluster. A namespace is nothing but hierarchical filesystem with directories and files. The metadata of the cluster is the information about the location of each block within the cluster.
Since the location of each block is stored in NameNode, if the NameNode goes down we cannot use the filesystem causing downtime of the whole filesystem.
 Filesystem Namespace in Linux. Source: https://blog.selectel.com/containerization-mechanisms-namespaces/
Filesystem Namespace in Linux. Source: https://blog.selectel.com/containerization-mechanisms-namespaces/
c. DataNodes
DataNodes are the workhorses of the HDFS cluster. They store and retrieve the data upon a request from and HDFS client (an app) or Namenode. They send a periodic report to the NameNode with the information about the block that they store and about their own health.
DataNodes are easy to fail and upon failure the NameNode replaces all the blocks in the failed node using the metadata.
4. HDFS Architecture
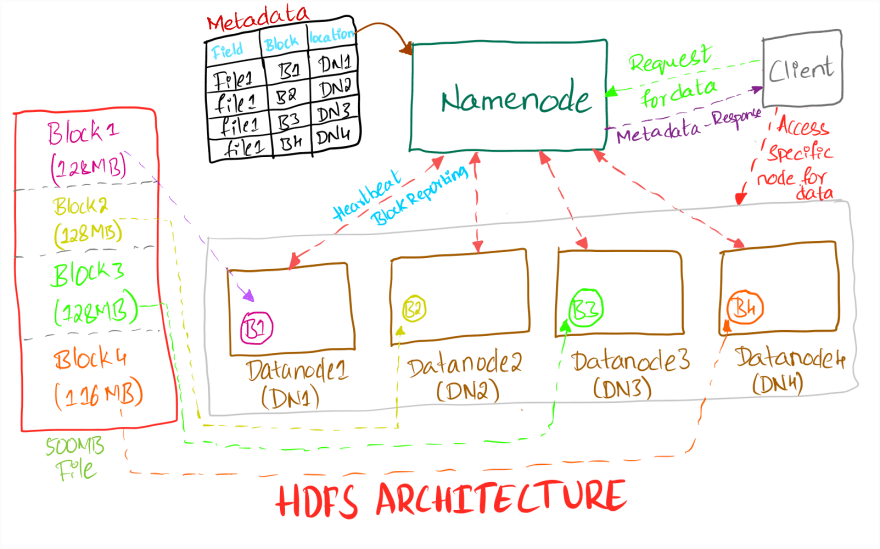 HDFS Architecture
HDFS Architecture
We've got ourselves familiar with some commonly used terms in HDFS in the above section. Now, we'll see how all of these will work together.
- A typical HDFS cluster has one NameNode and multiple DataNodes. Each DataNode is connected to the NameNode over the network. A 4-node cluster is shown in the above diagram. A HDFS cluster follows Simple Coherence Model which means a file once created, written, and closed need not be changed
- Every file in HDFS will be split into blocks of 128MB (block size) by default in Hadoop v2 (64MB in Hadoop v1). The block size can be increased or decreased by the Hadoop admin. There is a trade-off between block size and performance.
- If the block size is too small, then every large file will have millions of blocks, and it will put unnecessary strain on NameNode to store the location of all the blocks. Thus, affecting the performance of the filesystem. The default block size is suitable for most scenarios. Conversely, If the block size is too high, only few nodes in the cluster will store all the data and rest of the nodes will be idle leading to underutilization of the cluster.
- Each block will be stored on a different DataNode to avoid any data loss in case of node failure. Suppose we stored all the blocks on the same DataNode and if that node goes down, all the blocks of the file will be completely lost. So, storing blocks on different nodes will reduce the risk of data loss
- HDFS also maintains two more replicas of the blocks to reduce the risk of data loss further. Each block and two replicas of it will be stored on different nodes. This is handled by the property called " Replication Factor". By default, the Replication Factor in HDFS is "3"
- Every DataNode sends a " Heartbeat" signal to the NameNode to indicate that it is alive. The default heartbeat is 3 seconds. If a DataNode fails to send the heartbeat signal to the NameNode either due to network latency or node failure, the node will be replaced along with all the blocks it had before failure. The information about the blocks will be available in the NameNode metadata
- The metadata in the NameNode consists of the location of each block of every file across the cluster, permissions to access the file and more. A typical metadata is as mentioned below:
HDFS Metadata
| File Name | Block | Location |
| File1 | Block1 | DataNode 1 |
| File1 | Block2 | DataNode 2 |
| File1 | Block3 | DataNode 3 |
| File1 | Block4 | DataNode 4 |
Metadata of the cluster is a very important piece of information like a map to a new city we visit and without the map we're lost. The cluster is useless without the metadata. The metadata is stored in the memory (RAM) of the NameNode for low latency and the NameNode also persists the metadata to avoid the risk of losing the metadata in the event of failure. It is done using:
An fsimage represents the state of the file system at a point in time. Every file system modification like write, edit, and delete is assigned a unique, monotonically increasing transaction ID. fsimage represents the file system state after all the modifications up to a specific transaction ID
An editLog contains a log of each filesystem change (create, update, and delete) that was made after the latest fsimage. The editLog will be merged with the fsimage to create the latest state of the filesystem called " Checkpointing" and it can be triggered automatically or manually by the Hadoop admin
If a client wants to access the data from the cluster, first send a request to the NameNode for the location of files on the cluster. The client will receive the location of the data (Ex: DataNode1) from the NameNode when the permissions are resolved for the request for the client, and the client can access the data directly from the DataNode(s)
An HDFS cluster will go to a great length to ensure the data stored is not corrupted. Every DataNode will send the report with health of every block. This is called as " Block Reporting". If a block is flagged as corrupted, the Namenode will replace the block with its replica from a different node
In summary, the HDFS saves the files in terms of blocks and replicas of the blocks across a cluster of machines. Each machine will send the health report of itself and the data in it periodically to ensure both are operational all the time. Every edit made to the file system is logged and the state of the filesystem is always maintained in the NameNode.
5. DataNode Failure
Typically, the DataNode sends a Heartbeat every 3 seconds to NameNode. In case of any delay or failure to receive the Heartbeat, NameNode will wait for 10.5 minutes by default until it marks a datanode as dead(fail).
Once a DataNode is marked as failed, the replication factor for the blocks that are in that node goes below the default which is 3. The following happens:
- NameNode determines which blocks were on the failed node from the metadata.
- NameNode identifies the DataNodes with the copies of those blocks
- NameNode orders the DataNodes with those block replicas to copy to other nodes in the cluster to maintain the default replication factor. The replicas are directly copied to the nodes without any data passing through Namenode
Once the blocks are copied from the available nodes the replication factor of those blocks will be back to the default value. This is shown in the below diagram:
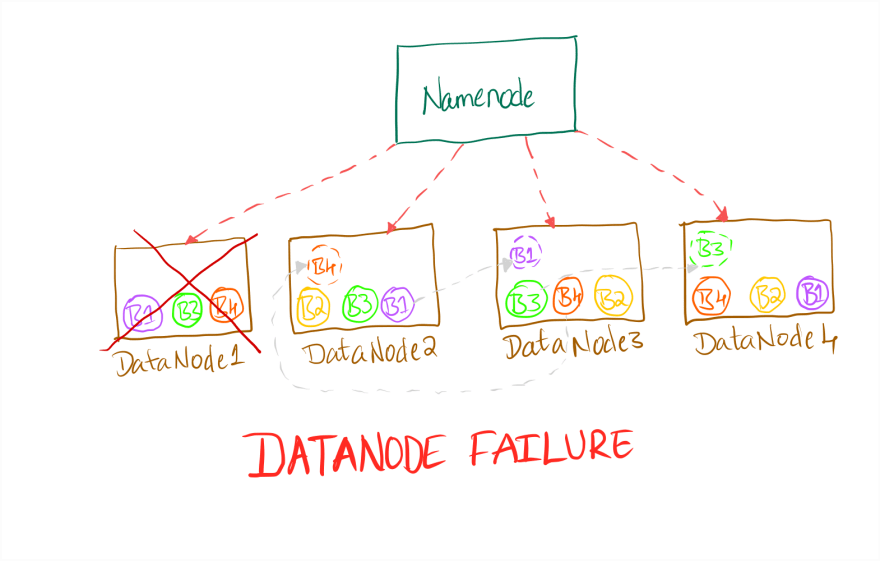 DataNode Failure in HDFS
DataNode Failure in HDFS
6. Secondary NameNode and NameNode Failure
The NameNode was a single point of failure in Hadoop v1. NameNode failure means the whole cluster is useless since the metadata is lost. In Hadoop v2 and later this is no longer the case. The filesystem state(fsimage) and the editLogs are persisted to the storage. This mitigates the risk of permanent failure to a great extent. We can restart the NameNode with the last available fsimage and editLogs and have less downtime rather than a catastrophe.
The above procedure still has one problem. The NameNode will merge the editLogs with the fsimage only on startup. The editLogs can be huge over time for a busy cluster and every restart later will take significant time and it will add to the cluster downtime.
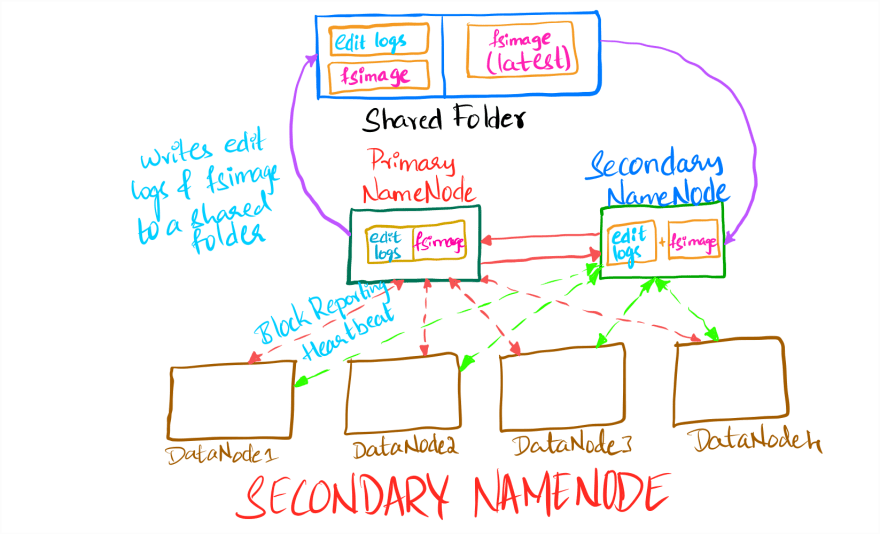
Currently, the NameNode performs activities like Heartbeat, maintaining metadata and block reporting and other background activities. Performing activities like Checkpointing (merging fsimage and editLogs) will hamper its performance severely. So, we need another node which will perform necessary activities of NameNode called Secondary NameNode. At a given time, only one NameNode will be in active state, and other NameNode will be in standby mode.
The Secondary NameNode runs on a different machine than the primary NameNode and the hardware requirements and the directory structure will be quite similar to the primary NameNode. It will be in a passive (hot standby) state, and it will perform checkpointing periodically and keeps the editLog size within a limit. The following image will show the above process.
- The primary NameNode will write the fsimage and editLogs to a shared folder periodically
- The secondary NameNode will access the editLogs from the shared folder and perform Checkpointing
- Only when the merge process is successful the editLogs will be removed from the shared folder (an NFS mount) and the new fsimage will be written there. The primary NameNode will get the updated fsimage from the shared folder. Merging fsimage and editLogs is a very resource intensive process, and it is carried out by the secondary NameNode only because the primary NameNode will be busy serving the clients and monitoring the cluster.
In case of NameNode failure, the secondary NameNode will be promoted to active state as the new primary NameNode. A new secondary NameNode is created which will take care of checkpointing as mentioned in the below image.
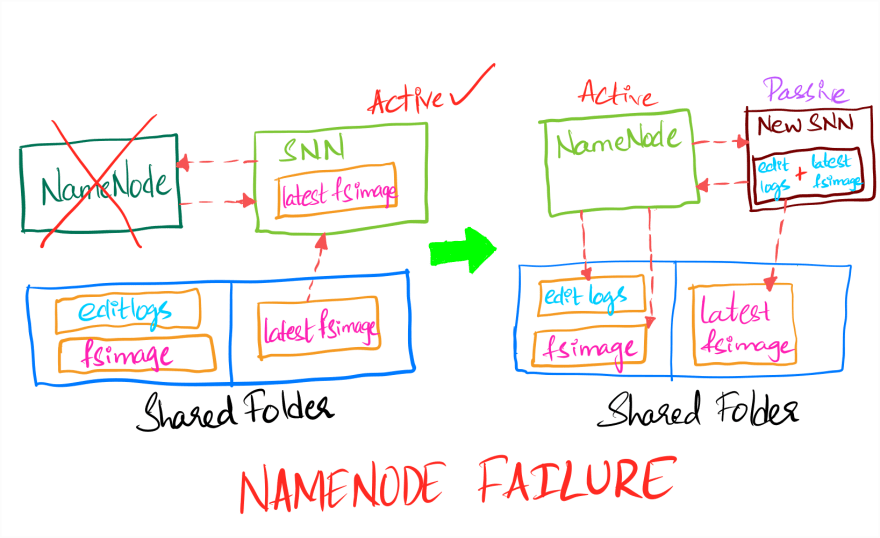 NameNode Failure in HDFS
NameNode Failure in HDFS
8. NameNode- High Availability
The NameNode High Availability (HA) takes the idea of standby NameNode + shared storage for editLogs and fsimage further. Instead of writing the editLogs and state to one shared folder, those are written to Quorum (group) for Journal Nodes (JNs).
The HDFS NameNode High Availability feature enables you to run multiple NameNodes in the same cluster in an Active/Passive configuration with a hot standby. This eliminates the NameNode as a potential single point of failure in an HDFS cluster [3].
Architecture
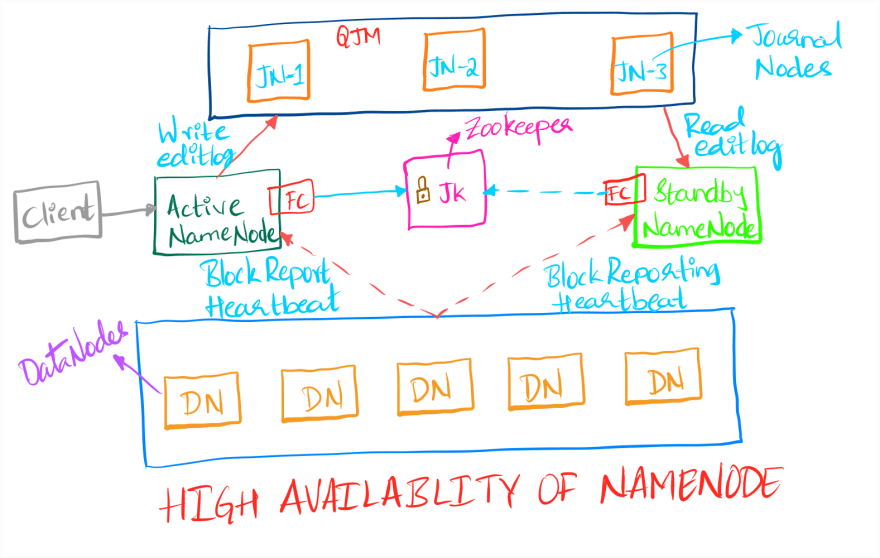
- In a typical HA cluster, two NameNodes are created in the same cluster, and one will be Active state while the other will be in Standby state. The Active NameNode is responsible is responsible for all the client operations on the cluster. The Standby just acts as a slave
- Only Active NameNode can write the editLogs, like Namespace modifications, file changes to Journal Nodes to avoid corruption. It writes to majority of JournalNodes at once. The Standby Namenode will constantly look for the changes in the active NameNode from the editLogs. It will read all the editLogs from the JounalNodes and applies the same changes in its namespace as well
- The DataNodes will send the Heartbeat and the block reports to both the active and the standby NameNodes.
- ZooKeeper(ZK) is a centralized service which monitors the state and synchronization between different systems in a distributed environment. It monitors the state of both NameNodes using "ZKFailoverController"(ZKFC or FC)
- ZK periodically pings the NameNode periodically and if it responds then it'll be marked as healthy. When the active NameNode is healthy it will hold a special "lock"(ZKFC). If the active NameNode fails to respond to the ZK's pings, the ZKFC lock will be deleted. Now, ZK will elect the standby Namenode as the active NameNode
- In a failover event, the Standby ensures that it has read all the edits from the JounalNodes before promoting itself to the Active state. (This mechanism ensures that the namespace state is fully synchronized before a failover completes.)
9. Rack Awareness
A Rack is group of nodes on a server connected to a using a single network switch. If the network goes down, the whole rack will be unavailable. Typically, a large Hadoop cluster is deployed in multiple racks.
Rack awareness means HDFS will choose the DataNodes close to each other in the rack formation for the cluster. This will ensure less network bandwidth is used during read/write operations. Communication between the DataNodes on the same rack is more efficient than DataNodes residing on different racks.
When placing the data blocks in the cluster HDFS considers the rack formation as well. If all the blocks and replicas of a file are placed on different DataNodes within a single rack, then in the event of rack failure all the data will be lost. So, two replicas of a block will be stored in a rack and other replica will be stored a different rack (considering the default replication factor is 3).
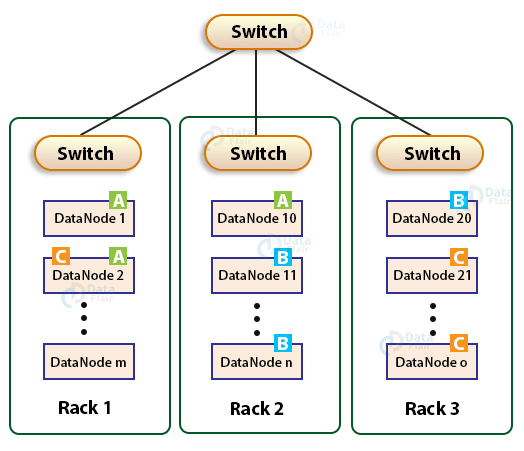
Source: https://data-flair.training/blogs/rack-awareness-hadoop-hdfs/
10. HDFS Commands
A typical Hadoop cluster is nothing but a cluster of Linux machines working together and interacting with the cluster is very similar to that of a typical Linux machine. To simplify each Linux command like ls, mkdir, rm, rmdir and etc. will be prefixed with hadoop fs or hdfs dfs.
For example:
hadoop fs -ls <hdfs_path> # This command will list all the files/directories at <hdfs_path>
hadoop fs -mkdir <hdfs_path>/<dir_name> # This command create a new directory at <hdfs_path>
I've added rest of the commonly used HDFS commands with examples here. Please do check it out!
Conclusion
HDFS is still one of the major technologies used by many enterprises to store very large datasets. It is the key to understand how big data is stored and processed in a distributed environment. It also offers very key features like data governance, data locality, access control and many more.
Sources
- Big Data course by Sumit M. All drawn pictures are courtesy of the course
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
- https://docs.cloudera.com/runtime/7.2.0/data-protection/topics/hdfs-files-and-directories.html
- https://docs.cloudera.com/HDPDocuments/HDP2/HDP-2.5.0/bk_hadoop-high-availability/content/ch_HA-NameNode.html
- https://data-flair.training/blogs/rack-awareness-hadoop-hdfs/#:~:text=Rack Awareness enables Hadoop to,in terms of network topology.
Books
Hadoop: The Definitive Guide (4th Edition) by Tom White
Thanks,
Mani
Posted on July 23, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



