Serverless Event Driven AI as a Service

Martyn Kilbryde
Posted on November 4, 2022

I'm going to discuss and go through a full application that was built to explore:
Serverless - Serverless is clearly still running on a server, but put simply it's using resources on demand, with AWS taking care of the infrastructure and servers.
Event Driven Architecture - Going hand in hand with serverless is being an event driven architecture - because we only pay for what we use, having an application that has absolutely nothing running until it has to reactively process a message. We also will also see how separate components, or Microservices, can be separated by the Event Bus and could theoretically be developed by whole separate teams and Code Bases.
Cloud Native Patterns - I've tried to include lot's of different use cases to show different patterns that can be used when building Cloud Native applications - from analytics, orchestration, etc
The vehicle for this journey will be a Twitter Bot; an application that can be fully reactive but something that isn't bound by specific domain behaviours, and not complex to understand.
The important part that you need to know is that Twitter has an API called the Account Activity API (Assuming Musk doesn't remove it) which can be configured to fire webhooks when any activity happens with a particular account. This means we will be sent events when receiving a mention for example - which is an ideal way to explore these technologies that has an internal and external domain.
As everything should be built in my opinion, the infrastructure is specified with code, so the whole application from the actual code, to the setting up of infrastructure is from a single application built using the AWS Cloud Development Kit. This means you can pull the code, and with a single command deploy the whole application, including infrastructure, to AWS and be in production within minutes. As it is all code and in one location then it is fully version controlled.
This whole application is open source, which can be found on GitHub. We'll be dipping into code samples throughout but it will be light touch - so I would recommend checking out the full code to see more detail.
Ingress Microservice
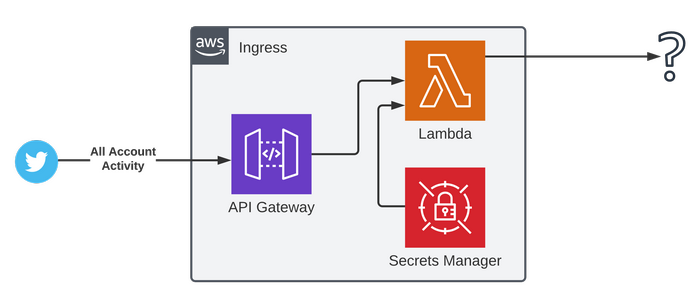
In the CDK project, this is it's own distinct Stack, and could therefore be pulled out into it's own repository; it's a boxed off Microservice in the cloud Native sense of that word. And whilst this scenario is for Twitter, we could extend this to have a poller pulling comments from Reddit, driven from Slack, and even setup a system using Amazon SES as an email server that can then fire an event when an email is received - which is something I have used for handling CCTV alerts.
Twitter communicates via HTTP requests, therefore the logical solution here is to use API Gateway; a fully managed API service from AWS which gives you a public endpoint and they handle all scaling and infrastructural management. You can directly integrate with many services so you can have no-code API that pushes to a SQS Queue for example, and then suck in vast amounts of requests to process through in a manageable way.
Twitter communicates to any registered webhooks with a few requests, one is a GET purely for authentication on the Twitter side, and the other is the actual webhooks for activity, which is up to us to authenticate if we want to make sure it came from Twitter.
The typical solution here would be to use a Lambda Authoriser which API Gateway would execute to authenticate each request. API Gateway could then potentially push the request direct to the downstream services.
Due to the fact a Lambda needs executing anyway, and some minor transformation logic is required as a Anti-corruption Layer, then a good solution here is to use a Lambda Proxy integration where the requests are proxied fully into a Lambda for it to process - it can then do authentication and processing all in one and return the correct response that Twitter desires.
The Lambda needs an API secret to calculate a hash for hash checking, so Twitter API details are stored encrypted in Secrets Manager (outside of the Git repository) and Lambda can pull these due to permissions granted with IAM.
Assuming these checks pass then the Lambda can then push the request to the next service, the details of which I go through below.
This is all that is needed in CDK to define the API Gateway for this app:
const twitterSecret = secretsmanager.Secret.fromSecretAttributes(this, 'TwitterSecret', {
secretPartialArn: `arn:aws:secretsmanager:${cdk.Aws.REGION}:${cdk.Aws.ACCOUNT_ID}:secret:TwitterSecret`,
});
// This contains the lambda that we will proxy to from API Gateway
const construct = new TwitterConstruct(this, 'TwitterActivity', {
twitterSecret,
plumbingEventBus: props.plumbingEventBus,
twitterIdOfAccount: props.twitterIdOfAccount,
});
// Proxy to false so we can define the API model
const api = new apigateway.LambdaRestApi(this, 'ingress-api', {
handler: construct.lambda,
proxy: false,
});
const twitterEndpoint = api.root.addResource('twitter');
twitterEndpoint.addMethod('GET');
twitterEndpoint.addMethod('POST');
First we pull a reference to the manually created secret so we can push that ARN reference around. Then we are constructing a custom Construct, in CDK a Construct is simply a "cloud component" - one of the patterns used in this repo is that each Lambda sits within it's own construct where the IAM permissions, lambda definition and lambda code can all be grouped together. At this point, construct.lambda is a reference to the lambda itself.
Then we create an API using a built in CDK Construct that will create a Lambda backed proxy API. We set proxy to false so that we can define the API model here - this means API Gateway will enforce a specific type of request, and avoid the Lambda being hit by any type of random request. Typically with Proxy based integrations you wouldn't define the model and have the lambda handling everything through something like Express for Node - but for a simplistic API like this, this definition is simple and keeps noise down.
And with that, after deploy we get a Public API that can be hit on a /twitter endpoint with a GET or a POST and our code will execute.
Plumbing Microservice
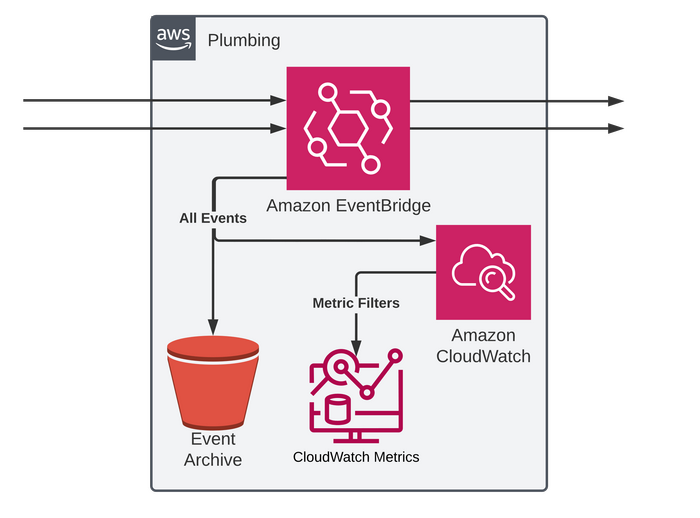
This is the plumbing microservice; it's effectively the hub or bus. This is a separate stack in CDK and can be managed and deployed separately. It doesn't care about what data is flowing through it, as long as it adheres to the basic JSON schema that EventBridge defines.
The key part here is the EventBridge Event Bus - An event bus allows a kind of publish/subscribe-style communication between Microservices without requiring the components to explicitly be aware of each other. EventBridge is the AWS Serverless managed service for Event Buses.
AWS themselves eat-there-own-dogfood because for a lot of AWS services they will publish events through EventBridge that you can use - such as EC2 status changes, scaling event, Code Builds and even if AWS find credentials in public repo's.
In this case, we have a custom EventBus for this application, defined in one line of code
new events.EventBus(this, 'bus', { eventBusName: 'Plumbing' });
At this point any service that has the IAM permissions can push an event into this Bus. The pattern here is that any Microservice can deploy a rule onto the EventBus to catch any events that they care about.
On top of the EventBus itself, something that I've personally found very useful is to deploy a catch-all rule and set the target as a Cloudwatch Log Group (which can be encrypted by KMS if required too). This means all events are logged (and thus can be queried in CloudWatch too) . If you've ever setup an Event Bus then you can find it quite frustrating if you are sending events and "nothing" is happening as maybe your rule is wrong, or you just don't know what is being sent.
As well as this we want some archiving that works generically no matter the type of event (as this service doesn't care). First we enable archiving which in our case is configured to catch all events. This is stored encrypted by default. You cannot see the events themselves though. The key part here is that you can replay events from a specific time-frame.
Once started it'll take all events from between then dates and push them back through the Event Bus. Which means all downstream services will get them again, and any newly added targets. That's obviously a very key point. When replaying, it will send events from the first minute of that frame first, then the second, and so on, they won't necessarily be in the same order as they were received.
And that is a key part of Event Driven Architecture, events are not guaranteed to arrive in order, or to arrive only once. Any consumers need to take this into consideration and rules need putting in place in the organization around using Idempotence keys for example and how to deal with events properly.
But saying that, the ability to replay can be useful for the when adding new Microservices, or Microservices that had downtime, to keep the application consistent. They can be a Get Out Of Jail free card if somebody runs a delete without a where for example.
Going back to the rule to push all events to CloudWatch, you can also use Metric Filters for getting metrics from the messages themselves. A Metric Filter in CloudWatch can be a great way to create metrics without needing to build in application support for them. For example, I once used them to build a dashboard of requests successfully or failed inserting to a DB, just based on logs in that one Lambda.
They work off of filter patterns which can just be a string, but as we log our events which are JSON then we can use a property selector to drive off of values to the detail-type property present in all EventBridge events. Worth noting that they are case sensitive. These are setup in CDK quite simply like:
private createMetricFilter(catchAllLogGroup: cdk.aws_logs.LogGroup, metricName: string) {
new logs.MetricFilter(this, `MetricFilter${metricName}`, {
logGroup: catchAllLogGroup,
metricNamespace: 'ServerlessMessageAnalyser',
metricName,
filterPattern: logs.FilterPattern.stringValue('$.detail-type', '=', metricName),
});
}
We can use a method like this to add as many as we want based on the different detail-types we want metrics on, they are all under the same namespace and then we can setup alerts and build dashboard such as:
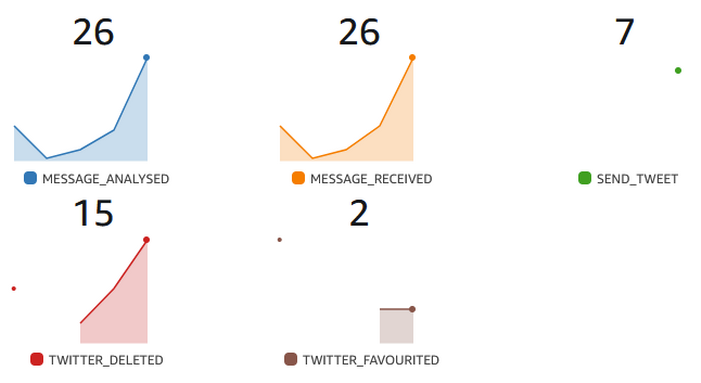
Now we have a simple way of seeing the different events flowing through the Bus, where all events are ultimately derived from external Webhook calls.
Let's take a look at an example event:
{
"version": "0",
"id": "2bea8c88-c241-d3ff-396f-d600c815599a",
"detail-type": "TWITTER_TWEETED",
"source": "TWITTER",
"account": "401252200999",
"time": "2022-09-21T12:56:22Z",
"region": "eu-west-1",
"resources": [],
"detail": {
"created_at": "Wed Sep 21 12:56:21 +0000 2022",
"id": 1572570427880538999,
"id_str": "1572570427880538999",
"text": "@makitdev https://t.co/rEghWG3W3c",
"source": "Twitter Web App",
"truncated": false,
"in_reply_to_status_id": null,
"in_reply_to_status_id_str": null,
"in_reply_to_user_id": 19985099,
"in_reply_to_user_id_str": "19985099",
"in_reply_to_screen_name": "makitdev",
"user": {
"id": 1498961531635122999,
"id_str": "1498961531635122999",
"name": "Harry",
"screen_name": "harry11",
"location": null,
"url": null,
"followers_count": 3,
"friends_count": 12,
...
This is an example of an Event we have created on the Bus based on a Mention from Twitter being web-hooked into our gateway. The Lambda on the Ingress microservice will first publish any webhook received as an event. This is a EDA tenet that make sense, publish an event for everything as it may be useful later
There are a few fields we must fill in when publishing an event, first we set the source as TWITTER so we know where this originated. The second part is the Detail Type, which specifies what will be in the detail field and should be consistently set as it will be used for matching later.
In this scenario our lambda takes the type of data from the JSON Twitter sent and dynamically makes the Detail Type TWITTER underscore and then the type. In all Uppercase. Such as TWEETED, DELETED, FOLLOWED, etc
Detail is an "any" type in EventBridge, for this event we simply push the raw JSON from twitter in here and then we can use whatever we want from there in any downstream service.
The one issue with this is that the schema for this event is defined by Twitter now, and we ideally want a system which can handle more than Twitter messages. So it makes sense to have an Anti-Corruption Layer. This is a Domain Driven Design pattern to protect our internal application from being dependent on an external systems model.
This is a very simple example of that, because our Ingress Lambda also publishes a second event that has an simplified Schema with the key parts in for a received message:
{
"version": "0",
"id": "3647243d-1243-1c79-55d5-e1d07be9d658",
"detail-type": "MESSAGE_RECEIVED",
"source": "TWITTER",
"account": "401252200102",
"time": "2022-09-21T12:56:22Z",
"region": "eu-west-1",
"resources": [],
"detail": {
"Text": "@makitdev https://t.co/rEghWG3W3c",
"ImageUrls": [
"https://pbs.twimg.com/media/FdLkdCPWIAQqRkc.jpg"
],
"Author": "harry11",
"Twitter": {
"TweetId": "1572570427880538999",
"UserId": "1498961531635122999"
}
}
}
At this point any activity on my Twitter account, whether that is Tweets I send, delete, favourites, follows or mentions - we will get an event on the Bus, and 2 events in the case of a mention specifically to us.
This means we can move on to start analysing the messages.
Analysis Microservice
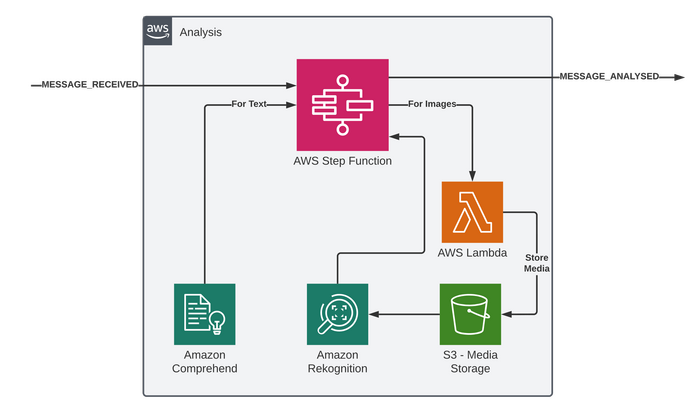
The job of the analysis microservice is to use multiple AI services for analysis of the text and images.
Due to the fact that we wish to hit multiple services, and multiple different APIs on them services, all to derive a single piece of analysis then Orchestration is key here. If we went of a more Choreography approach then we could have separate services for analysis of text vs images for example, but we would need to join up the result later.
The AWS Serverless service of choice for Orchestration are Step Functions, they allow defining a workflow and the service will control the flow and the handling of the integrations to do the precise defined steps. Nowadays Step Functions can integrate into the majority of AWS services directly without code and so a lot can be achieved in a no-code style.
We're going to use Comprehend for text analysis here, and Rekognition for Image analysis.
The output of the analysis will be another event fired into the Plumbing Event Bus of MESSAGE_ANALYSED
Below shows the workflow:
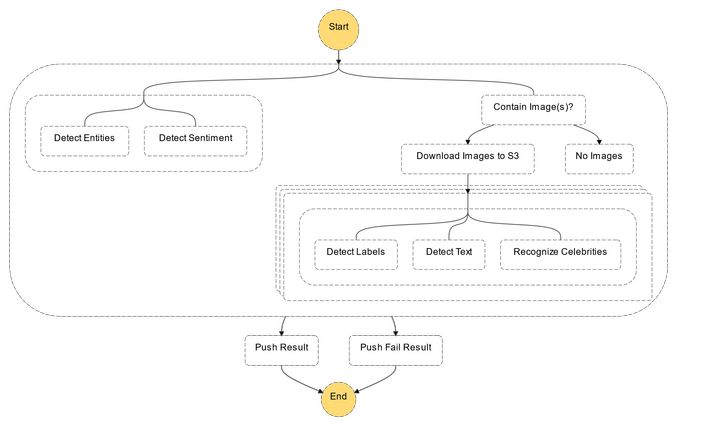
We have got a few patterns going on in this workflow. Luckily one of the biggest benefits to Step Functions is the visual nature of the tool, you can show the workflow and it's simple to understand exactly what will happen, and you can even build them visually with drag-and-drop in the Console. You could therefore sit with Domain experts and design flows together for example.
Starting from the top we first split into parallel activities as these aren't dependent on each other. On the left we have some direct to Comprehend Integration tasks which will pass the text through for Entity and Sentiment detection. Whilst on the right we first have a choice as not all tweets will have images, but if they do then we need to download them into S3 so Rekognition can access them. We use a Lambda for that. Once downloaded we use a Map to loop, in parallel, the images and have three direct to Rekognition integrations to detect objects in the image, text and look for celebrities.
The result from all the calls will go into a step with a direct-to-EventBridge push. Let's look at these AI services in more detail
Comprehend is a natural-language processing (NLP) service using machine learning to get insights from text & documents.
Highlight of it's capabilities:
- Custom Classification
- Entity Recognition
- Sentiment Analysis
- Targeted Sentiment
- PII Identification and Redaction
- Language Detection
- Topic Modelling
- And more...
In this case I have added Entity recognition and sentiment analysis, which was added in the Step Function using CDK like:
const detectEntities = new tasks.CallAwsService(this, 'Detect Entities', {
service: 'comprehend',
action: 'detectEntities',
iamResources: ['*'],
parameters: {
'Text': stepfunctions.JsonPath.stringAt('$.Text'),
'LanguageCode': 'en',
},
});
const detectSentiment = new tasks.CallAwsService(this, 'Detect Sentiment', {
service: 'comprehend',
action: 'detectSentiment',
iamResources: ['*'],
parameters: {
'Text': stepfunctions.JsonPath.stringAt('$.Text'),
'LanguageCode': 'en',
},
});
These add tasks into the workflow against them specific services and APIs, with the specific parameters needed - such as sending the Text from the input event and hardcoded EN for this example (although we could use language detection to first figure out that).
And that is it, we have NLP processing added to our application with a few lines of code. So what about images?
Rekognition can do Image and Video analysis. This includes:
- Object and Scene Detection
- Facial Recognition
- Facial Analysis
- Celebrity Recognition
- Text In Image
- PPE detection
- Unsafe Image Detection
- And more...
In this application I have integrated into Object detection (Labels), Text in image and some of the facial analysis. Adding one of these to the Step Function in CDK is as simple as:
const detectLabels = new tasks.CallAwsService(this, 'Detect Labels', {
service: 'rekognition',
action: 'detectLabels',
iamResources: ['*'],
parameters: {
'Image': {
'S3Object': {
'Bucket': this.analyseBucket.bucketName,
'Name': stepfunctions.JsonPath.stringAt('$.Key'),
},
},
},
resultSelector: {
Labels: stepfunctions.JsonPath.stringAt('$.Labels'),
},
});
Here we need to pass a reference to the image in the bucket and Rekognition will then pick it up and do the analysis.
Here's a cut-down compressed output of all these AI services:
...
"TextSentiment": "NEUTRAL",
"CelebrityFaces": [ {
"Face": {
"BoundingBox": { "Height": 0.1132516, "Left": 0.19861165, "Top": 0.13658012, "Width": 0.085628614 },
"Emotions": [ { "Confidence": 59.62892, "Type": "SAD" }, { "Confidence": 39.235394, "Type": "CALM" }],
"Landmarks": [ { "Type": "eyeRight", "X": 0.25121698, "Y": 0.18415646 }, { "Type": "mouthRight", "X": 0.2510353 } ],
"Pose": { "Pitch": -31.584389, "Roll": 4.0039296, "Yaw": -14.885307 },
"Quality": { "Brightness": 88.59461, "Sharpness": 53.330048 },
"Smile": { "Value": false }
},
"Name": "Keanu Reeves" }
],
"UnrecognizedFaces": [],
"Labels": [
{ "Name": "Shoe", "Parents": [ { "Name": "Footwear" }, { "Name": "Clothing" } ] },
{ "Name": "Fowl", "Parents": [ { "Name": "Bird" }, { "Name": "Animal" } ] } ],
"TextDetections": [ {
"DetectedText": "VAN",
"Geometry": { "BoundingBox": { "Height": 0.05679034, "Left": 0.80430186, "Top": 0.53000635, "Width": 0.055198133 } }
}],
"TextEntities": [
{ "BeginOffset": 0, "EndOffset": 9, "Score": 0.74110556, "Text": "@makitdev", "Type": "PERSON" },
{ "BeginOffset": 10, "EndOffset": 33, "Score": 0.99794835, "Text": "https://t.co/rEghWG3W3c", "Type": "OTHER" }
]
...
This is an example from a message containing an image. You can see the face it recognised, along with bounding boxes and landmarks of the specific face; this includes the emotions they are showing, quality of the image and whether they are smiling.
Labels shows the different objects or types of things within the image, this is hierarchical so you get generic labels like Clothing and then more specific like Dress.
Right at the bottom is Text that has been found in the image and where it was found.
This is all part of the detail of the output event which is pushed direct to Event Bridge.
Alerting Microservice
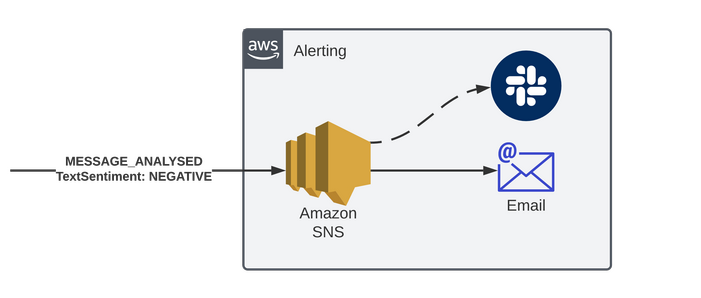
Say we want to send an alert for any negative messages received, this microservice can add a rule to match only for MESSAGE ANALYSED detail type and where the sentiment is NEGATIVE, and then target an SNS topic.
That topic can be subscribed to from Email - or we could build integrations into destinations like Slack.
And this whole service is as simple as:
const negativeMessagesRule = new events.Rule(this, 'NegativeMessages', {
eventPattern: {
detailType: ['MESSAGE_ANALYSED'],
detail: {
Analysis: {
TextSentiment: ['NEGATIVE'],
},
},
},
eventBus: this._eventBus,
});
negativeMessagesRule.addTarget(new targets.SnsTopic(alertTopic, {
message: events.RuleTargetInput.fromText(`You have received a Negative Message: ${events.EventField.fromPath('$.detail.Text')}`),
}));
We define a rule in CDK on the bus matching on Detail Type and where the detail contains the sentiment we are looking for. We then add the SNS target to that rule, and can specify the text which is effectively a little transformer taking the supplied message text and sending just that defined message to SNS (otherwise it would send the whole JSON blob).
And that only takes one SNS topic and one rule, and an understanding that the schema of MESSAGE_ANALYSED won't break compatibility. Nothing upstream knows about this.
Analytics Microservice
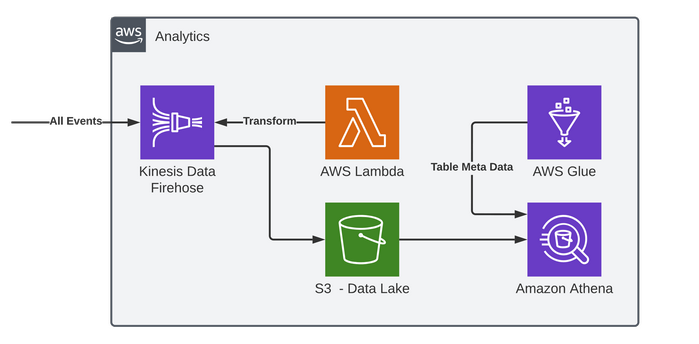
A very useful benefit of having a central Event Bus for communication is that events can be grabbed for analytic purposes without impacting any other part of the system, true observability.
As you can see in the diagram, we are feeding all events from Event Bus via a catch-all rule into Kinesis Data Firehose. Firehose is a fully managed service that streams into specific destinations like Data Warehouses or Data Lakes. Unlike it's bigger brother of using Kinesis Data Streams directly, there are no setting up of shards and it's mostly configuration free. We are only defining a buffer interval which is part of how Kinesis works by delivering messages from the stream into the bucket every 60 seconds or if it hits a configured size (1MB).
A Data Lake is a dump of raw data unlike a warehouse, but by adding an extra parameter in this CDK construct pointing to a data transformation Lambda we can do some processing on the data before it is stored. You can also use a Table defined in Glue (If you are sure of the schemas) and enable Firehose to convert JSON into Parquet; which is more efficient for querying. Our processing in this example is simply to add a newline after each event JSON so that we can query against it.
Once it's in a Data Lake then you have different options depending on the analytics you need. For more advanced constant analytics then you could look into Amazon Kinesis Data Analytics instead of Firehose to S3, but for Ad-Hoc queries then this is where Glue and Athena come in.
For this we are defining table in Glue using CDK. Glue is a fully managed ETL Service -it can crawl data, suggest schemas and can transform and load into other destinations.
One a table is defined, then we can use Athena. Athena is a serverless query service, it lets you use SQL to query data in S3 and then you pay for only the data is scans for the query. It's surprisingly performant for something that is querying files directly. It's simply a table definition in Glue and then SQL running against raw data. For this reason it's for Ad-Hoc usage, for more intense query's then you would be better off running Glue to ETL into a Warehouse.
Example of a query:
SELECT labels.name, COUNT(1) as Count
FROM "analysed-messages-table"
CROSS JOIN UNNEST(detail.analysis.images) as t(images)
CROSS JOIN UNNEST(images.analysis.labels) as t(labels)
WHERE "detail-type" = 'MESSAGE_ANALYSED'
GROUP BY labels.name
ORDER BY COUNT(1) DESC
This outputs data like:
| name | Count |
|---|---|
| Person | 25 |
| Human | 25 |
| Apparel | 15 |
| Smile | 12 |
If you aren't already using a data lake, then it's something to consider as the cost of storing text in S3 is very small and it allows you to start looking at the data with these Ad-Hoc queries before jumping straight into warehousing or potentially wasting money of storing vast amounts of data in a DB if it's never really used.
Responding Microservice
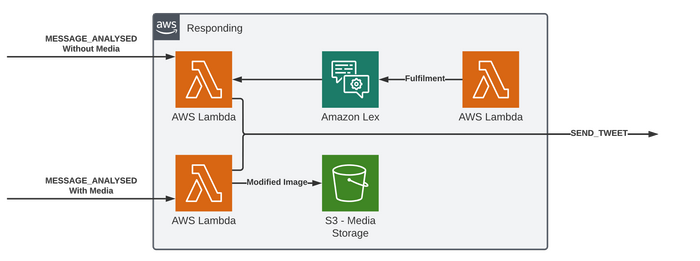
The final service using AI is one that figures out a response to the message based on the analysis.
That means we kick it off with two rules in the Bus to capture ANALYSED messages with and without images. Our bot will either reply to text or images, but not both at the same time (lets just call that a weird business decision that came from a CEO).
The image scenario at the bottom is relatively simple, as we are going to send a message about what celebrities were found. This data is already present in the Event so here we target a lambda that processing the image and adds the celebrity name over the top of the face using the bounding box data given before saving back to S3. It then outputs a Command Event to send a TWEET which contains some text with the list of celebs and a reference to the image.
The text processing is a bit more interesting, as we have the original text and some insights into the content and sentiment, but we need a response. So for this application Amazon Lex has been configured to do this.
Lex uses the same technology as Alexa for Natural Language Processing, but it's boringly devoid of life. It needs configuring for your specific use cases, and it'll use it's ML models to fulfil that purpose. But ultimately you get a conversational AI.
It can work with text or Voice, including a phone voice, and integrates into Polly, which is the AWS Text to Speech engine.
It will manage context and effectively will hold a session per conversation for gathering information etc. There are tools for building up the model, as well as ways to train it from your existing chat logs if you have them.
It supports using Lambdas for fulfilling specific duties, such as placing orders, as well as integrating into Kendra which is a ML powered search service. You can effectively have a conversation asking for information and it can intelligently look through your business domain and respond with answers in a naturally conversational way.
Ultimately Lex is a much deeper topic then I can show in this example application, where using Lex is very overkill in reality. It can be configured in CDK, but only using lower level CloudFormation constructs.
In a nutshell the way to configure it is with what are called intents, which are actions a user would like to perform. Such as Order a Pizza, or Return a Product. These are setup with sample phrases a user might say, this one demonstrates how a user might want to hear a joke:
const jokeIntent: lex.CfnBot.IntentProperty = {
name: 'Joke',
sampleUtterances: [
{
utterance: 'please tell me a joke',
},
{
utterance: 'I would like to hear a joke',
},
{
utterance: 'make me laugh',
},
{
utterance: 'tell me something funny',
},
],
fulfillmentCodeHook: {
enabled: true,
},
};
Lex can then use it's NLP to figure out what intent the user is trying to do before driving them down that path. You can then have things called Slots which are parameters that need to be gathered from customers, such as address, pizza topping, etc.
Once an intent has all the slots then the intent becomes ready for fulfillment and it can then call an integration, such as a Lambda. The lambda receives these values and then does the appropriate action.
Our fulfillment lambda in this application simply checks if the Intent is for a Joke or Fact, then it will pull a random one from different APIs and return them to Lex for response. Calling Lex is as simple as a API call, or SDK function that will do this for you.
Egress Microservice
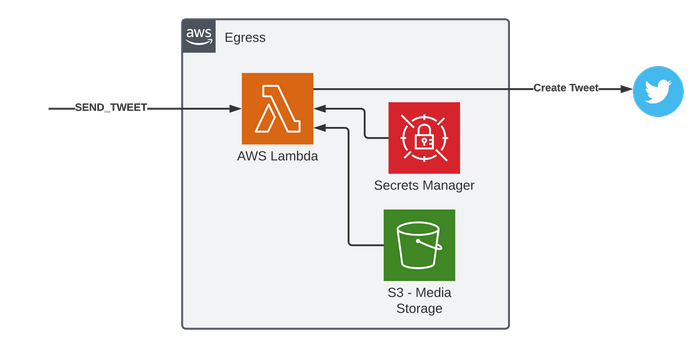
This service is very simple and doesn't need much explanation, we need to effectively call an API at Twitters which could potentially be done directly from EventBridge using an API Destination. Unfortunately in this scenario we need to pull images from S3 and upload them to Twitter before sending a Tweet, therefore a Lambda is used to perform this logic.
Full System Diagram
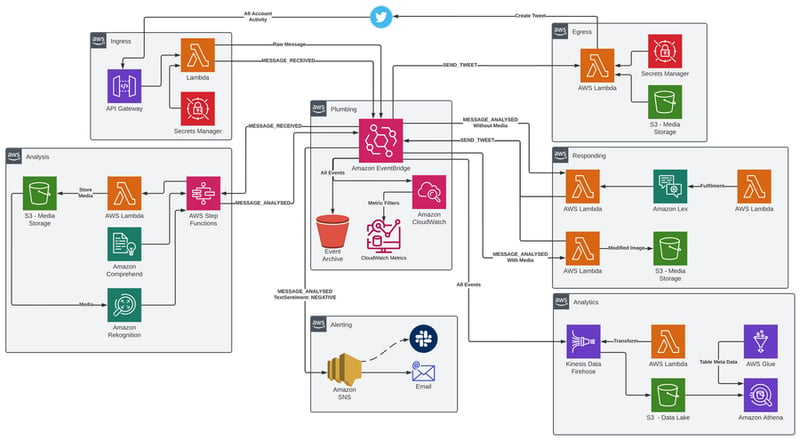
Whilst this may seem very overkill for a simple bot... I hope you can now see that it demonstrates a decoupled architecture which works for the very small and the very large application. A large enterprise can easily have a full squad on each of these Microservices and only need to share documentation using the Event Schemas. EventBridge has the Event Schema Registry to help in this regard. The business logic of that application can then be situated in each service and could potentially use some of the patterns I have discussed here.
Please take a look at the GitHub Repo for more information and to try it out.
Posted on November 4, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


August 22, 2021