
Uroš Štok
Posted on February 3, 2024
When it comes to automating signups, verification codes are almost always used. These codes serve as an additional layer of security, ensuring that the user signing up is genuine and has access to the email associated with the account.
Verification codes range from only digits to mixed characters; it all depends on the platform.

How do we go about parsing and extracting these codes?
There’s two ways: we either focus on the text and search based on that, or we look for html elements in the email that contain the said code. Sometimes, a bit of both is required. In this post, we’ll explore both methods and show some common examples.
If you're looking for a more general guide on how to automate the verification flow, check out Email verification with Cypress
Searching with Regex
If our verification code consists solely of digits, we can write a simple regex that searches for a digit string of a certain length. If the verification code is 6 digits, we can use the following regex:
\b(\d{6})\b
it("Should verify email", () => {
let code;
cy.mailiskSearchInbox(Cypress.env("MY_NAMESPACE"), {
to_addr_prefix: "testuser",
subject_includes: "verification code",
}).then((response) => {
const emails = response.data;
const email = emails[0];
// we search the text version of the email
const match = email.text.match(/\b(\d{6})\b/);
expect(match.length).toBeGreaterThan(0);
code = match[1];
expect(code).to.not.be.undefined;
});
console.log("Your code is: " + code);
...
});
In the above code, we used the text version of the email. This doesn't contain a lot of the HTML clutter like styles, tags and classes, making it less likely we'd match the wrong content.
But what if the code contains both digits and letters? In this case, the Regex method isn't quite enough unless there's a prefix before the code that we can use. In the above example, the text version looks like this:
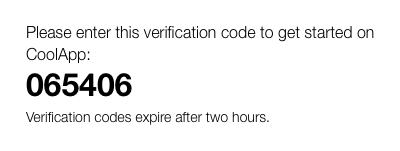
Please enter this verification code to get started on CoolApp: \n> \n> 065406 \n> \n>
Let's modfiy the code so it includes both numbers and letters, making it harder to extract:
Please enter this verification code to get started on CoolApp: \n> \n> A3G56L \n> \n>
Since we know that the code is after verification code to get started on CoolApp: we can include this in our regex, modifying it like so:
verification code to get started on CoolApp:.\*([A-Z0-9]{6})
it("Should verify email", () => {
let code;
cy.mailiskSearchInbox(Cypress.env("MY_NAMESPACE"), {
to_addr_prefix: "testuser",
subject_includes: "verification code",
}).then((response) => {
const emails = response.data;
const email = emails[0];
// we search the text version of the email
const match = email.text.match(/verification code to get started on CoolApp:.*([A-Z0-9]{6})/);
expect(match.length).toBeGreaterThan(0);
code = match[1];
expect(code).to.not.be.undefined;
});
console.log("Your code is: " + code);
...
});
We constructed our regex in three parts. First the prefix which ends on CoolApp:, then any characters .* and finally the format of our code [A-Z0-9]{6}.
Of course, in this example, simply using \b[A-Z0-9]{6}\b would have been enough. However, this can fail depending on the text content and lenght of the code, which is why we used the prefix.
Searching with HTML
Using HTML is usually a surefire way to easily extract verification codes. The reason is that most codes are marked differently (e.g., bolded), making them easy for the user to see and for us to extract.
Let's use the cheerio package. This will allow us to use selectors to fetch certain parts of the HTML.
In this example the email's html contains the following:
...
<tr>
<td class="h1 black" align="left" dir="ltr" style="...">065406</td>
</tr>
...
This is quite convenient, as in this example there is only one td element with h1 black. If there were more then we'd have to filter from higher in the hierarchy (e.g. tr, table, etc.).
it("Should verify email", () => {
let code;
cy.mailiskSearchInbox(Cypress.env("MY_NAMESPACE"), {
to_addr_prefix: "testuser",
subject_includes: "verification code",
}).then((response) => {
const emails = response.data;
const email = emails[0];
// we load the email html into cheerio
const $ = cheerio.load(email.html);
// we find the element using the selector
const nodesText = $("td.h1.black").text();
// since there's one element and it only contains the code we can extract it directly
const code = nodesText;
expect(code).to.not.be.undefined;
});
console.log("Your code is: " + code);
...
});
And there we have it – two ways verification codes can be parsed and extracted from emails.
Posted on February 3, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.