Data Cleaning - Filter

Mage
Posted on March 25, 2022

TLDR
In this lesson from Mage Academy, we’ll look at one method of data cleaning, filter. Learn how to filter numbers, words, and just about anything in order to reduce bias in your dataset.
Glossary
- Introduction
- Detecting what to filter
- How to code
- Magical Solution ✨🔮
Introduction
Filtering through data is a very common transformation; it takes in a conditional and checks through all the data to keep only the data that meets the condition. By filtering you can improve your machine learning models by training on a specific subset of data to specialize the model, remove incorrect data and outliers, or prune biased features.
 With all that data you’re going to need a filter! (Source: xkcd)
With all that data you’re going to need a filter! (Source: xkcd)
To start off with what filtering does, it takes in a pile of data and turns it into something smaller and (hopefully) easier to work with. When you create a filter, you start from what will stay, not what will go.
Detecting what to filter
Understanding how to create the best filters are based around 2 things: Where the data comes from and how we apply each filter to our data.
 Start from square one by filtering all the flawed data. (Source: xkcd)
Start from square one by filtering all the flawed data. (Source: xkcd)
Where does the data come from?
First, we need to assess where our features are coming from and whether they’ll be relevant to our use case. Filtering can be applied to all data, and can therefore be used for many different use cases. It’s best to do this to avoid bias and the situation below.
 A biased judgment call will be bad, or very bad. (Source: xkcd)
A biased judgment call will be bad, or very bad. (Source: xkcd)
These bad cases occur when a lot of mathematical transformations were done to manipulate the data too much. We’ll want to throw away this as it can lead to data leakage. This could be training a model to predict a user’s location, but your data contains the lat/long coordinates. Or in the very bad case, when the samples have been cherry picked instead of being entirely random.
How do we apply filters to our data?
Next, we’ll take a look at three different possible data types. For more information on how to spot each one read our guide on data types.
The conditional values do a different thing depending on the data types. For an input of numbers you can filter using the logical operators to set ranges for the data. Otherwise, when given textual data like words, or “strings”, it’ll follow an ASCII Table to determine the order, usually leading to an alphabetized range from A-z.
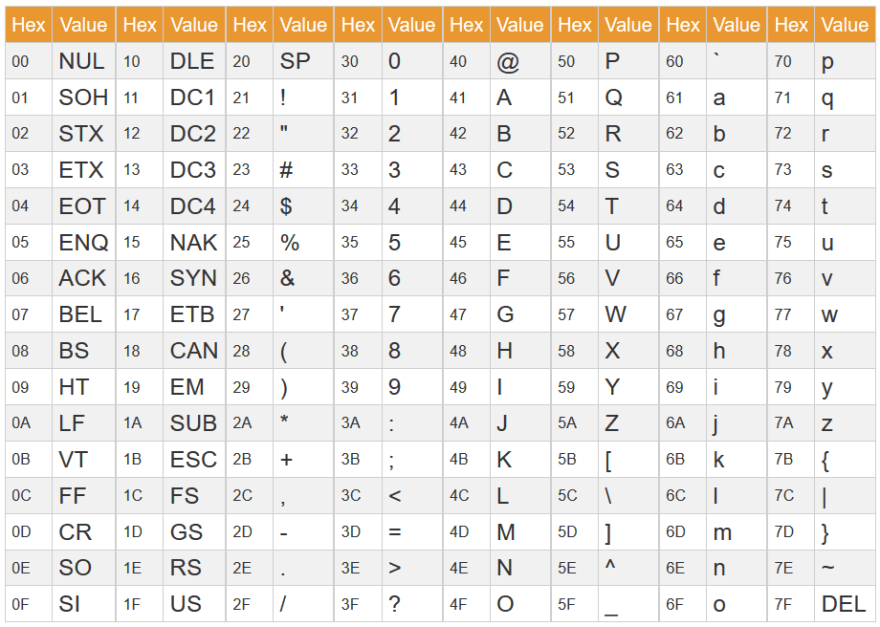 ASCII Table of all Symbols (Source: ScienceBuddies)
ASCII Table of all Symbols (Source: ScienceBuddies)
Finally, we get to the datetimes, in another article called ditching datetimes we go over how to format and reformat them to meet specifications. For filtering through datetimes, it’ll be in chronological order, so “<” means dates before, “>” is dates after, “==” is dates equal to, and so on.
How to Code
To begin with, we will look at a simplified version of a census conducted for the Annual Survey of Entrepreneurs. This data contains information on all demographics related to companies from 2016. From this we’ll want to analyze companies. To begin with we’ll want to filter down this data to exclude firms, and show only companies that are at most two years old. Finally, in order to make a good investment we want to follow startups that are looking into a particular market niche.
 Ride that rocketship of growth! (Source: Entrepreneur)
Ride that rocketship of growth! (Source: Entrepreneur)
Pandas
We’ll begin by using the Python Pandas library to import our census data and begin filtering it to find the up and coming startups of 2016. We’ll break down our criteria into 3 conditional statements.
First, we want to identify the startup companies so we’ll filter all companies that have been running for two or more years. Then we’ll exclude all firms to get the parent companies only. Finally, we’ll look at their success by filtering out those which have an annual spend of 1 million dollars or more.
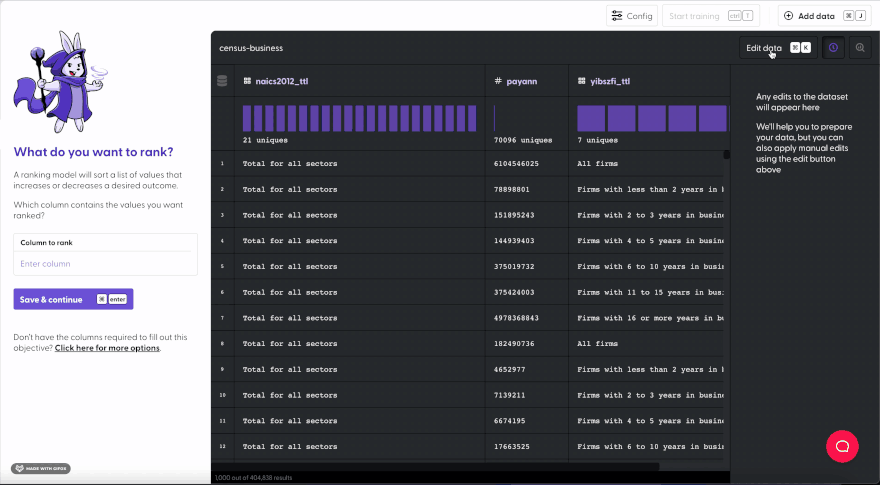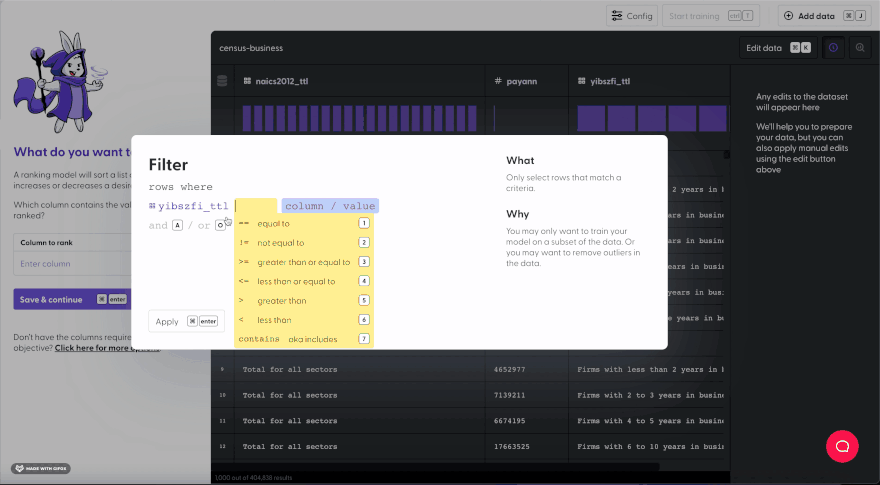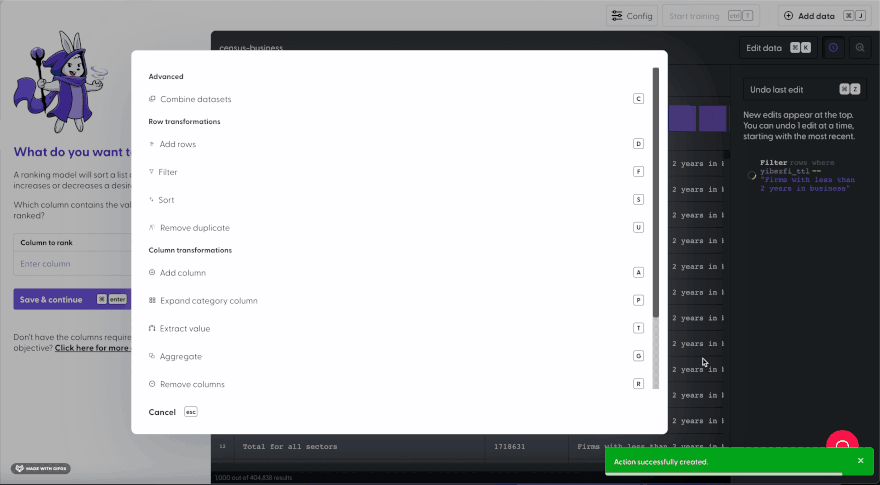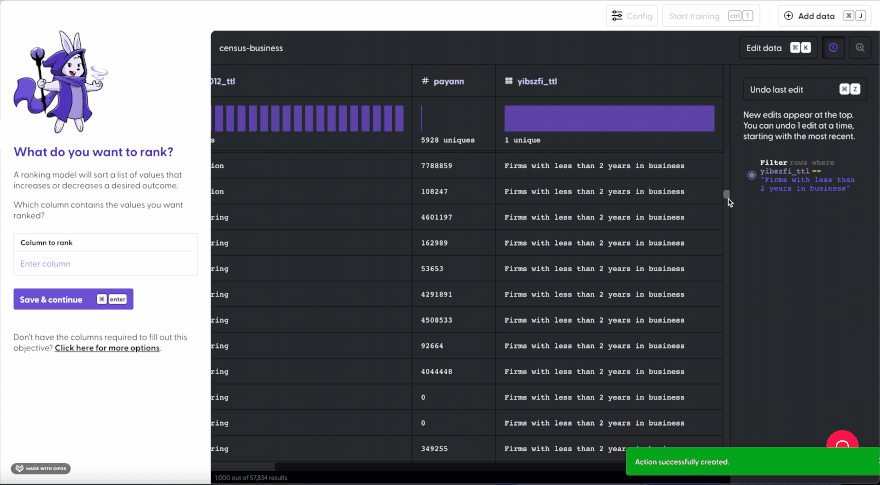
According to the census, the YIBSZFI_TTL represents the “Years in business from initial founding”. Here we’ll see if there’s an exact match for our value “Firms with less than 2 years in business.” Our conditionals that we’ll want to start off with is to filter out all the firms that aren’t startups. Next we’ll want to get the firms that don’t make over $1 million.
We covered many of the ways filter works in a more comprehensive guide on “surfing through dataframes”, but here we’ll write a simple conditional statement using == to check for an exact match.
![]()
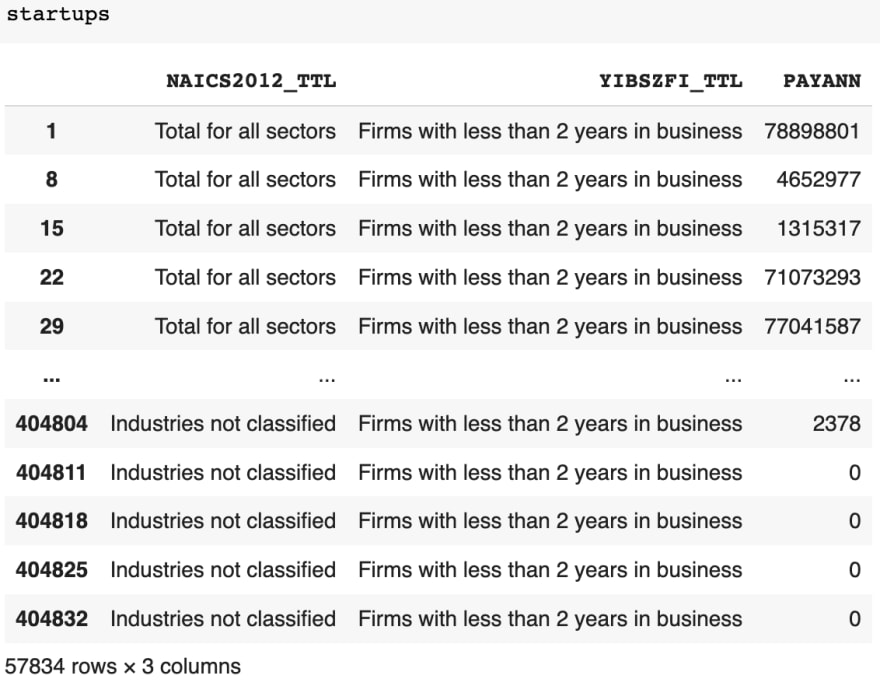
Then, we’ll keep only the companies that didn’t have an annual spending of 1 million dollars. Here we’ll create a filter for annual pay, PAYANN, to determine if a company was profitable. By our definition of profitable, we’ll be checking if the value was greater than or equal to a million dollars.
1 profitable = data[(data['PAYANN']>=1000000)]

Finally, because we want companies that are specialized and have a niche in the market, we’ll filter out companies that are more generalist. This is represented by the North American Industry Classification System (NAICS). For a generalist company, it will have a value of "Total for all sectors".
1 niche = data[(data['NAICS2012_TTL'] != "Total for all sectors" )]
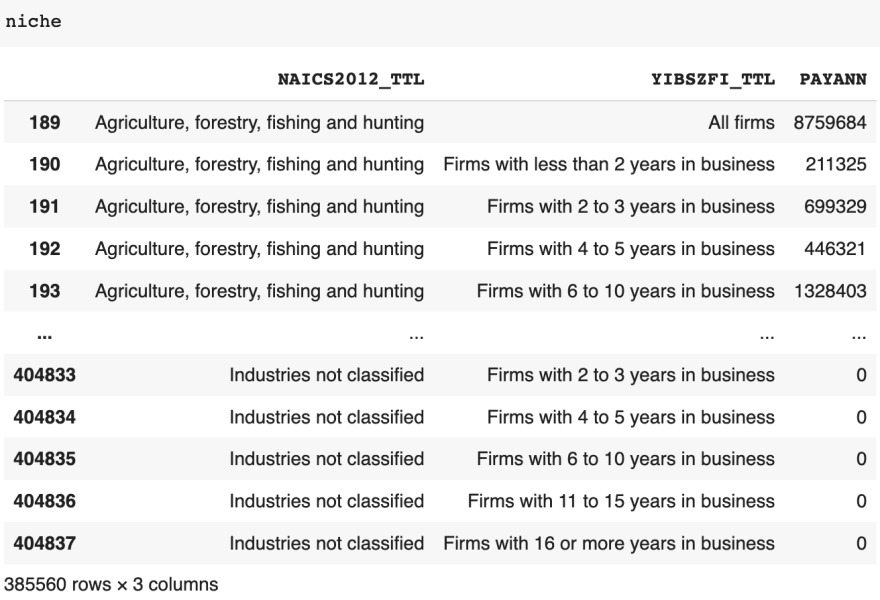
As a one liner, you can combine all the statements together with the use of the & (and).
1 top_startups = data[(data['PAYANN']>=1000000)
2 & (data['YIBSZFI_TTL] == 'Firms with less than 2 years in business')
3 & (data[' NAICS2012_TTL'] != "Total for all sectors" )]

Now that we’re done, we have a list of all companies that have an annual spending of 1 million dollars, so they’ve got to be making quite some bank or have investors who believe in them. That’s the end of filtering our dataset, we now have a good amount of data that can be used to answer your questions on what companies you should invest in. With this data, we can develop a ranking model to create a model to rank the top 100 startups and create predictive models for the generations to come.
 Now that’s a pitch! (Source: Shark Tank)
Now that’s a pitch! (Source: Shark Tank)
Magical Solution ✨🔮
But now with Mage, you can create a model to demonstrate your pitch by comparing yourself to the competition. Here, we’ll recreate our dataset and apply the same filter in less than a minute. You don’t need to know how to code Python, but some basic understanding of logic is required such as conditionals.
Want to learn more about machine learning (ML)? Visit Mage Academy! ✨🔮
Posted on March 25, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related