How Neural Networks work: activation functions

Madeline
Posted on April 11, 2021
In my post Deep learning: when and why is it useful?, I discussed why a neural network uses non-linear functions. In this article we will see an example of how to use those non-linear functions in a neural network. We'll be considering classification problems for the sake of simplicity. We'll also look at a few different kinds of non-linear functions, and see the different effects they have on the network.
What actually is an activation function?
A neural network can have any number of layers. Each layer has a linear function followed by a non-linear function, called an activation function. The activation function takes the output from the linear function and transforms it somehow. That activation becomes the input features for the next layer in the neural network.
Here's a 3 layer neural network to help us visualize the process:
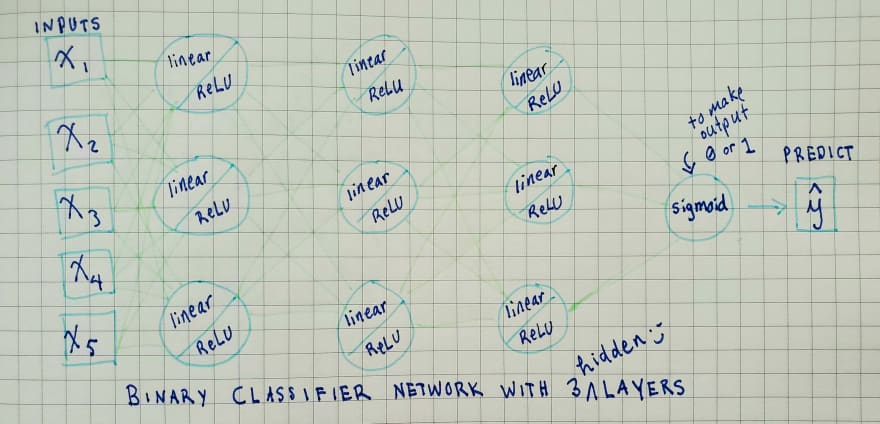
- We have features (x1, x2, x3, x4, x5) that go into the first hidden layer
- this layer calculates the linear functions (y=wx+b) on each input and then puts the result from that calculation through the activation function ReLU(max(0, x)
- the activations output from layer 1 becomes the inputs for layer 2 and the same calculations happen here
- the activations output from layer 2 become the input for layer 3 and then layer 3 does the same linear function-activation function combo
- the last set of activations from layer 3 go through a final activation layer, that will be different depending on what your model is trying to predict: if you have only two classes (a binary classifier), then you can use a sigmoid function, but if you have more than two classes you will want to use softmax
- those final activations are your predicted labels
Why would we want to do that?
Linear models are great, but sometimes non-linear relationships exist and we want to know what they are. Consider the example below.
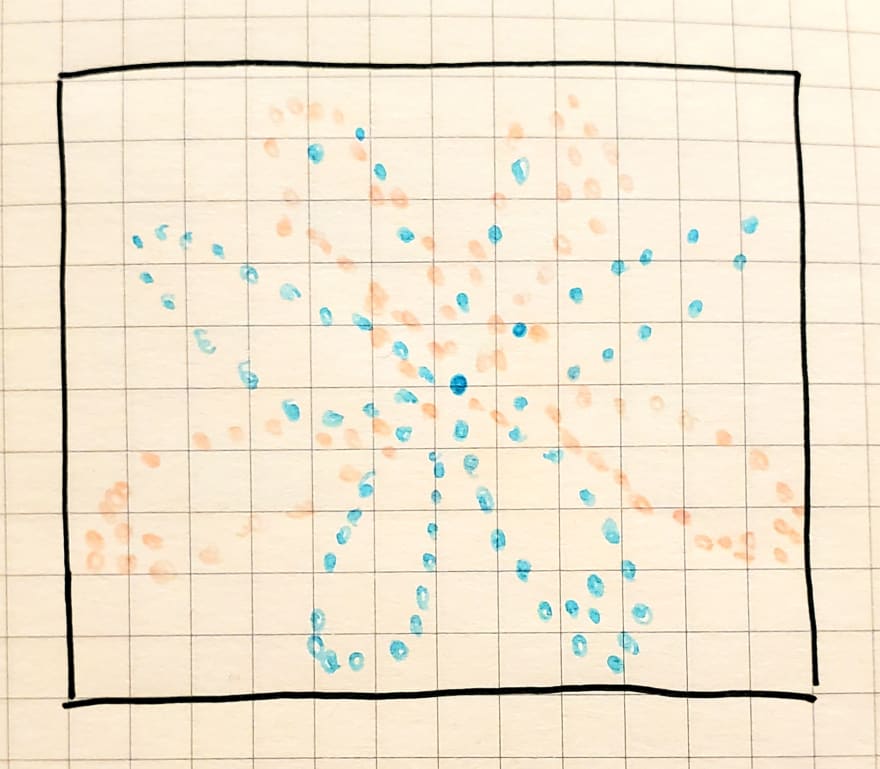
We want to predict the boundary line between the blue and pink dots (fascinating, I know!).
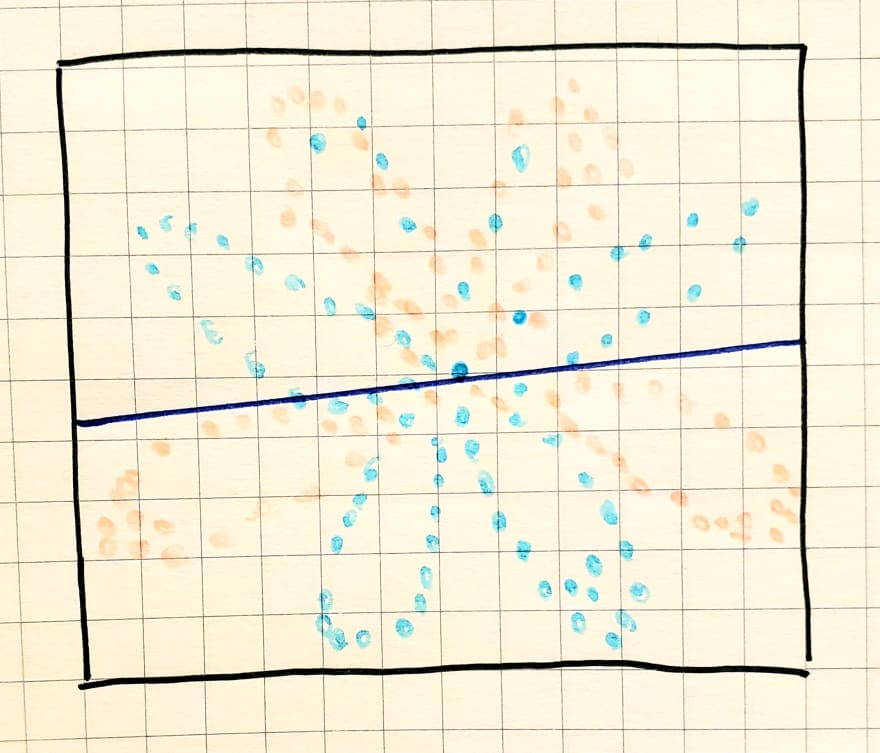
This is what a linear function, such as logistic regression, can uncover:
This is what a non linear neural network can uncover, which gives us a better visualization of the boundaries between blue and pink dots:
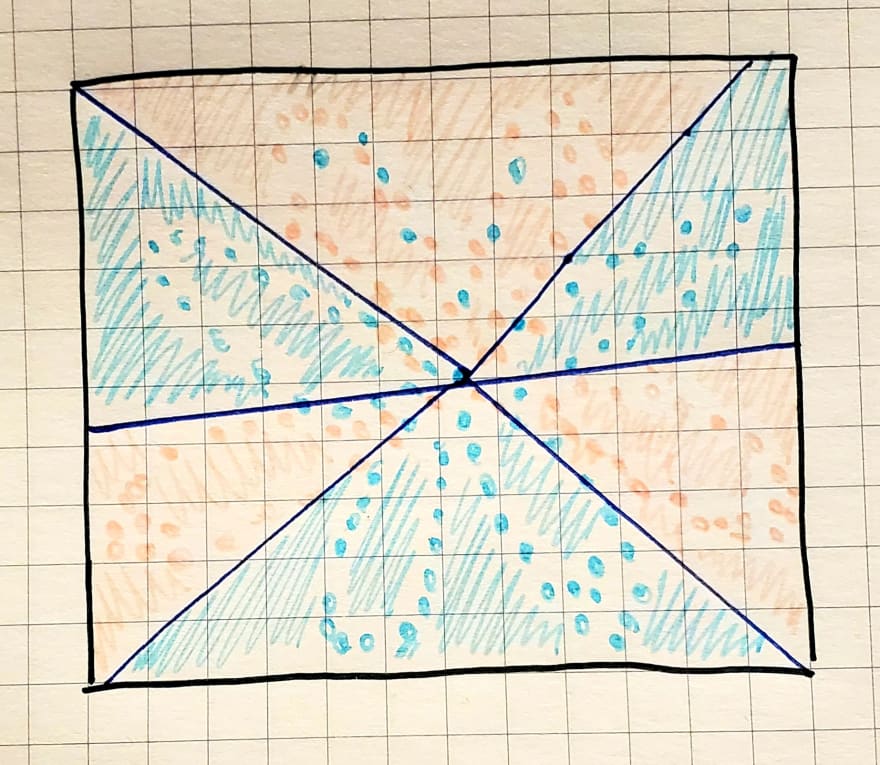
Furthermore, the more hidden layers we add to our network, the more complex relationships we can potentially find in the data—each layer is learning about some feature in the data.
Okay, but how?
I find it helpful to think of activation functions in two categories (I don't know if this is an "official" distinction, it's just the way I think about them)—activations on hidden units and activations for the final output. The activations for the hidden units exist to make training easier for the neural network, and allow it to uncover non-linear relationships in the data. The activations for the final output layer are there to give us an answer to whatever question we are asking the neural network.
For example, let's imagine we're training a binary classifier that distinguishes between pictures of cats and mice. We might use the ReLU activation function on our hidden units, but for our final output layer we need to know the answer to our question: is this picture of a cat or a mouse? So we will want an activation function that outputs 0 or 1.
Let's take a look at what each different activation function is actually doing.
A few popular activation functions:
x here stands for the output from the linear function that is being fed into the activation function
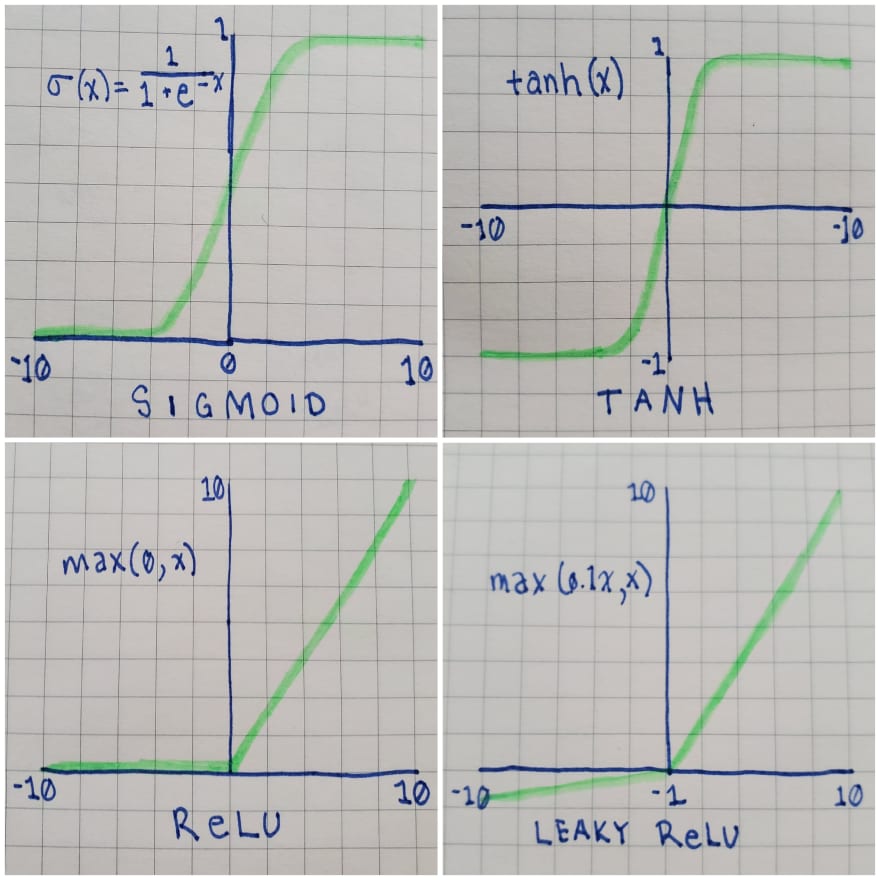
- Sigmoid converts outputs to be between 0 and 1
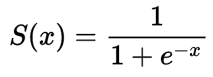
- Tanh: converts numbers to range from -1 to 1—you can picture it as a shifted version of sigmoid. It has the effect of centering the data so that the mean is closer to 0, which improves learning for the following layer.
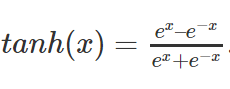
ReLU (rectified linear unit): max(0, x) if the number is negative the function gives back 0, and if the number is positive it just gives back the number with no changes—ReLU tends to run faster than tanh in computations, so it is generally used as the default activation function for hidden units in deep learning
Leaky ReLU: max(0.001x, x)—if the number x is negative, it gets multiplied by 0.01, but if the number x is positive, it stays the same x
Final layer activation functions:
-
Sigmoid is used to turn the activations into something interpretable for predicting the class in binary classification,
- since we want to get an output of either 0 or 1, a further step to is added:
- decide which class your predictions belong to according to a certain threshold (often if the number is less than 0.5 the output is 0, and if the number is 0.5 or higher the output is 1)
- (Yes, sigmoid is on both lists—that's because it is more useful in deep learning in producing outputs, but it's helpful to know about for understanding Tanh and ReLU).
Softmax is used when you need more than one final output, such as in a classifier for more than one category/class. Suppose you want to know if a certain image depicts a cat, dog, alligator, onion, or none of the above. The motivation: it provides outputs that are probabilities
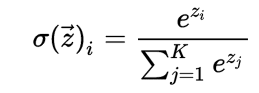
- If that formula looks gross to you, come back next week—I plan to break it down step by step until if seems painfully simple
Posted on April 11, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.