Tekton CI/CD, the grand finale, interceptors

Leandro Proença
Posted on February 22, 2023

We learned in the previous article how to delivery applications using Tekton and the kubernetes-action Task being part of our Pipeline.
But let's think about our process a little bit:
- We open/update some Pull Request
- The Event Listener listens to the Github event
- The pipeline is triggered
- The pipeline runs 3 tasks: clone, build and deploy
Everytime we change the PR, a new deploy is made. But what if we wanted to test the deploy in a "staging environment" first?
That means: we want to release our image to a staging area, which is close to production but somewhat isolated using different data, where we can perform manual tests in the application, and afterwards decide if we promote the image to production or reject it, sending back to the development process for bugfixes and so on.
In Kubernetes, it's quite easy to separate environments in the same cluster, where pods in staging area are "forbidden" to see the production area.
Kubernetes namespaces for the rescue
Let's apply the chespirito-pod to the namespaces (staging and production), so we can keep on our CI/CD saga:
$ kubernetes create namespace staging
$ kubernetes create namespace production
$ kubernetes apply -f chespirito-pod.yml -n staging
$ kubernetes apply -f chespirito-pod.yml -n production
Great, now let's re-think our pipeline a bit more.
The main branch should be production-ready
It's almost mandatory in a variety of companies and projects, that the main branch should be production-ready. By doing this way, we keep the main branch safe which helps to decrease the number of bugs.
Having that said, the feature branch behind the PR can be used to perform our CI tasks: build and staging deploy.
And, as soon as the feature branch is merged to the main branch (PR merge), we should trigger another pipeline, which would perform a rollout deploy to production.
Time to see the needed changes.
Changing the Event Listener
So far, our event listener is listening to events from Github and glueing trigger binding with trigger template.
We have to "intercept" the event, thus being able to look at the payload and decide which pipeline to trigger: staging pipeline or production pipeline.
Tekton Interceptors
In Tekton, event listeners employ the concept of Interceptors, which are event processors that allow to query/filter and manipulate payloads coming from the webhooks.
Tekton delivers by default cluster interceptors for Github and Gitlab, but in order to have more flexibility to manipulate different scenarios, comparisons, calculations on-demand and so on, Tekton also brings CEL interceptors, that stand for Common Expression Language, or CEL.
We're going to use the CEL interceptor, because we want to check whether the payload refers to a Pull Request under certain conditions.
Working on Pull Requests
While working on Pull Requests, we want to trigger the staging-pipeline when the PR is ONLY opened or synchronized (a new commit on the PR branch).
apiVersion: triggers.tekton.dev/v1beta1
kind: EventListener
metadata:
name: chespirito-github-el
spec:
serviceAccountName: tekton-service-account
triggers:
- name: pr-trigger
interceptors:
- ref:
name: "cel"
kind: ClusterInterceptor
apiVersion: triggers.tekton.dev
params:
- name: "filter"
value: >
header.match('x-github-event', 'pull_request') && body.action in ['opened', 'synchronize']
bindings:
- ref: github-pr-trigger-binding
template:
ref: github-pr-trigger-template
........
Note that:
- the
headerobject in CEL brings a parsed HTTP header, so we can look at theX-Github-Eventtype - the
bodyobject in CEL brings the parsed HTTP body
Now, we create the trigger binding as previously, which will get the revision (commit) from body.pull_request.head.sha:
apiVersion: triggers.tekton.dev/v1beta1
kind: TriggerBinding
metadata:
name: github-pr-trigger-binding
spec:
params:
- name: revision
value: $(body.pull_request.head.sha)
- name: repo-url
value: $(body.repository.clone_url)
And the trigger template:
apiVersion: triggers.tekton.dev/v1beta1
kind: TriggerTemplate
metadata:
name: github-pr-trigger-template
spec:
params:
- name: revision
default: main
- name: repo-url
resourcetemplates:
- apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: chespirito-staging-pipeline-
spec:
serviceAccountName: tekton-kubectl-service-account
pipelineRef:
name: chespirito-staging-pipeline
workspaces:
- name: shared-data
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
params:
- name: repo-url
value: $(tt.params.repo-url)
- name: revision
value: $(tt.params.revision)
Such template will start the staging-pipeline with the revision and repo-url coming from the binding. Hence, we'll end up building an image using the revision as the image tag.
This is a good practice, in which each deployed image has its own version leveraging on the git revision.
The Staging Pipeline
The staging-pipeline will do pretty much the same as previously, but we have to change the kubectl script allowing to use the git revision as the image tag version:
export RELEASE_REVISION=$(params.revision)
export RELEASE_IMAGE=colima:31320/chespirito:$RELEASE_REVISION
kubectl set image deployment/chespirito-pod app=$RELEASE_IMAGE -n staging --record
kubectl rollout status deployment/chespirito-pod -n staging --timeout 5m
In short, the staging pipeline:
- fetch source (clone)
- build (run tests)
- release (build an image for staging)
- rollout deploy the image to staging
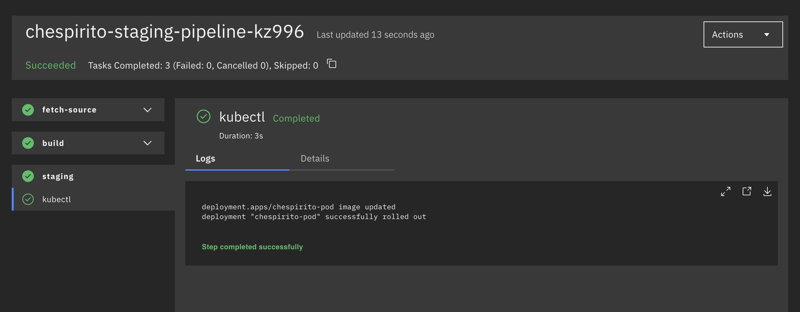
Are we ready?
Once we validate Staging and everything is good, time to promote the same Staging image to production.
We start looking at the second trigger in event listener:
....
- name: push-main-trigger
interceptors:
- ref:
name: "cel"
kind: ClusterInterceptor
apiVersion: triggers.tekton.dev
params:
- name: "filter"
value: >
header.match('x-github-event', 'pull_request') && body.action in ['closed'] && body.pull_request.merged == true
bindings:
- ref: github-main-trigger-binding
template:
ref: github-main-trigger-template
....
Note that this time, in addition to looking at the header to know if it's a pull request event, we also look at the body. In case it's a closed event AND it's a merged PR, we proceed with the template that refers to the production-pipeline.
Couldn't we look at push events?
That's a good question, we could look at push to main and would be enough. But we want the revision of the last commit in the PR.
Thankfully, Github sends both pull_request closed and push to main events, that's why it's a better option looking at the closed PR which will have a flag merged: true, then there's no need to look at the push event.
Furthermore, we keep the Github webhook sending only PR events, that's more efficient and use less resources over the network.
The Production Pipeline
PR closed (and merged), time to see how our pipeline will look like. That's dead simple, there's no need to build images and whatnot.
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: chespirito-production-pipeline
spec:
params:
- name: repo-url
type: string
- name: revision
type: string
tasks:
- name: production
taskRef:
name: kubernetes-actions
params:
- name: "script"
value: |
export RELEASE_REVISION=$(params.revision)
export RELEASE_IMAGE=colima:31320/chespirito:$RELEASE_REVISION
kubectl set image deployment/chespirito-pod app=$RELEASE_IMAGE -n production --record
kubectl rollout status deployment/chespirito-pod -n production --timeout 5m
The only thing here is looking at the revision - thanks to the PR closed event, we have the revision which is exactly the same we sent to Staging -, and using the same image to rollout update to production.
The deploy time is terrific: 11 seconds!.
Why? You may wonder. We are building the image in the staging-pipeline. Using the same registry. In the same cluster.
Just nothing more than a simple kubectl rollout action.
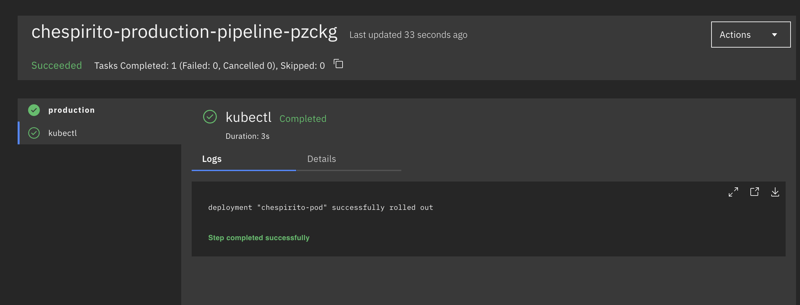
Okay, I'm sold
That's a huge achievement in terms of CI/CD. We have agility without losing quality and security. Using RBAC correctly, there's no chance of staging "messing up" with production. Everything is isolated.
One last thing, security matters
In real production environments, it's not good to use the public Git HTTP clone URL, because we work many times on private repositories.
We can in fact use the body.repository.ssh_url instead of body.repository.clone_url in the trigger bindings.
All we have to do is sharing a workspace across tasks. This workspace will be backed by a Kubernetes Secret.
In the trigger template, declare the workspace in the PipelineRun, which reads from a Secret named ssh-directory:
......
workspaces:
- name: ssh-directory
secret:
secretName: ssh-directory
.......
Then, in the pipeline, at the taskRef git-clone, along with output, send the workspace ssh-directory, so the Task will do the job reading the Secret and configuring all the ssh credentials needed for SSH.
.......
workspaces:
- name: output
workspace: shared-data
- name: ssh-directory
workspace: ssh-directory
........
Now, let's see the secret part. Be aware that you have to generate a keypair using openssh, or reuse your current key. It's up to you.
Place the public key in your Git repository account and create a generic Secret using the private key, something like this:
kubectl create secret generic \
ssh-directory \
--from-file=id_ed25519=$HOME/.ssh/id_ed25519 \
--dry-run=client \
-o yaml | kubectl apply -f -
I'm using ed25519 but it can be rsa or other cryptographic algorithms too. It's totally up to you, but it's very important to configure the secret correctly, otherwise the Task won't be able to authenticate via SSH hence the git-clone Task will fail.
Wrapping Up
That's it. It's been a journey, so let's recap:
- We started talking about CI/CD fundamentals and "why we are here"
- Then, we covered an introduction to Tekton, learning its main building block components
- The second part was about sharing information with Workspaces which are very important to master if we want to explore the best on CI/CD pipelines
- Afterwards, we've seen how to listen to Github events, making automation the first-class citizen
- The part IV talks about the continuous delivery, where we created a pipeline that did a complete job testing, building and deploying an application in production
And this post, the last one, was a demonstration of improving our pipeline, making it more reliable with different environments, where we could learn about Interceptors, which helped to achive our goal 🚀
I hope you enjoyed the journey. Feel free to hit me at Twitter or LinkedIn.
Cheers! 🍺
Posted on February 22, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
