NET8 Web Api Monitoring Fast and Easy With Traces, Logs and Metrics.

leandronoijo
Posted on February 4, 2024

TL;DR: Quickly Jumpstart your monitoring setup with the net8-webapi-monitoring repository. In it a complete containerized solution (with dockers) to streamline your monitoring suite with traces, logs and metrics, together with grafana containing 2 provisioned dashboards to showcase the setup's capabilities. Aside it you'll find a demo web api to play with and see the monitoring in realtime.
Introduction
Joining a company immersed in the fast-paced world of stock market data, I was faced with leading a newly formed team through the challenge of delivering a comprehensive API service under tight deadlines. Our task was to navigate a complex landscape of a vast MSSQL database and an array of services, with the goal of providing stock market information adhering to OpenAPI 3 standards. Given the time constraints, the luxury of optimizing every endpoint upfront was off the table.
Our strategy pivoted to a focus on robust monitoring, allowing us to identify and prioritize optimizations based on real usage data. This approach led us to implement a suite of tools including Serilog, OpenTelemetry, Jaeger, Prometheus, Loki, and Grafana. These weren't just tools; they were our beacon in the complexity, guiding our development and troubleshooting efforts, enabling us to meet our delivery targets effectively.
This blog post is about that journey. It's a guide for developers and team leads alike on how to leverage monitoring for better performance insights and efficient issue resolution. Here, I share our approach to implementing fundamental observability, ensuring our service not only met its initial release targets but was also poised for future growth and scalability.
Why Monitor APIs?
Adapt to User Behavior: The "20% of the work delivers 80% of the value" principle underscores the unpredictability of user interaction. Monitoring unveils actual user engagement, often in unexpected ways, guiding enhancements and optimizations where they truly matter.
Avoid Premature Optimization: Early optimization without user data can lead to misallocated resources. Monitoring helps identify the most used aspects of your API, focusing optimization efforts on areas that genuinely improve user experience and system performance.
Fast Delivery in a Competitive World: Rapid development and iteration are key in today’s market. Monitoring provides essential insights for data-driven decisions, enabling quick adaptation to user feedback and maintaining a competitive edge.
Faster Troubleshooting and Debugging: Monitoring not only aids in understanding user behavior but also accelerates the identification of issues and bottlenecks. Quick access to detailed logs, metrics, and traces means faster troubleshooting and more efficient debugging, reducing downtime and improving overall service reliability.
Understanding the Types of Monitoring
Monitoring an API involves three key pillars: Logs, Metrics, and Traces. Each provides a unique lens through which to observe and understand the behavior and health of your system. Here's how they contribute to a robust monitoring strategy:
Logs: Logs offer a detailed, timestamped record of events within your application. They are invaluable for diagnosing issues after they've occurred, providing context around errors or unexpected behavior. For example, logs can help identify when a particular service starts to experience issues, acting as the first indicator of a problem.
Metrics: Metrics provide quantitative data on the system's operation, such as CPU usage, memory usage, request counts, and response times. They are crucial for identifying trends and patterns over time. Consider a service that's performing slowly without apparent stress on CPU or RAM; metrics on the thread pool could reveal an ever-growing queue, indicating blocked or stuck threads, pointing to areas that need optimization.
Traces: Traces allow you to follow the path of a request through your system, providing a detailed view of the interactions between various components. Tracing is essential for pinpointing specific performance bottlenecks. In the scenario where thread pool metrics suggest blocking, traces can identify which endpoints are slowest and deep dive into each call. This might reveal, for instance, that SQL connections are being handled synchronously instead of asynchronously, causing the delay.
Together, these pillars of monitoring offer a comprehensive view of your application's health and performance. Logs help you understand what happened and when, metrics give you the high-level trends and immediate state of your system, and traces provide the granularity needed to dissect specific issues. By leveraging all three, you can not only identify and resolve issues more efficiently but also proactively optimize your system for better performance and reliability.
Introduction to OpenTelemetry
OpenTelemetry provides a comprehensive, open-source framework for gathering telemetry data (metrics, logs, and traces) across applications. It addresses the growing need for observability in complex systems, offering a unified way to collect, analyze, and export data without tying developers to a specific vendor. This flexibility ensures that applications can be monitored in a way that suits their unique requirements, enhancing debugging, performance monitoring, and operational visibility.
Adopting OpenTelemetry means embracing a community-driven approach to observability, allowing for seamless integration with a variety of tools and platforms. It's an essential step for developers aiming to improve system reliability and make informed decisions based on detailed insights into application behavior.
Next, we'll explore how OpenTelemetry integrates with .NET 8, highlighting its key features and how it complements other monitoring solutions.
Implementing Serilog for Advanced Logging in .NET Web APIs
Serilog stands out in the .NET ecosystem for its flexible and powerful logging capabilities. It excels in logging to multiple destinations and allows for on-the-fly configuration changes, making it a go-to for applications needing detailed, real-time insights.
What Are We Doing?
We are trying to connect our .net webapi into metrics, logs, and traces collectors in order to send all this data to grafana and have the ability to visualize it easly. Heres a diagram
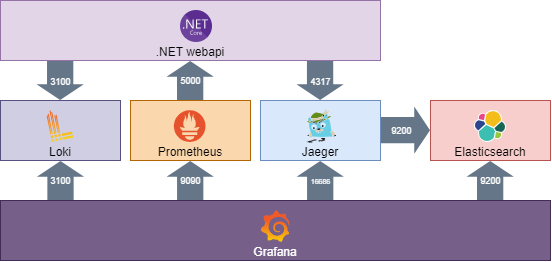
Why Choose Serilog?
Multiple Outputs: Serilog supports logging to various outputs simultaneously, including consoles, files, and external services like Grafana Loki. This multiplicity allows developers to tailor logging strategies to suit different environments and needs, ensuring that logs are always accessible, whether for immediate debugging in development or for detailed analysis in production.
Dynamic Configuration: Logging levels and outputs can be adjusted without redeploying, via changes in the '''appsettings.json'''.
Enrichment: Logs can be enhanced with additional context (machine name, thread ID), aiding in-depth analysis.
Implementing Serilog in a .NET Web API
Integration with .NET's DI system is straightforward, offering a seamless setup process:
using Serilog;
public class LoggerSetup
{
public static Logger Init(WebApplicationBuilder builder)
{
var logger = new LoggerConfiguration()
.ReadFrom.Configuration(builder.Configuration)
.CreateLogger();
builder.Logging.ClearProviders();
builder.Logging.AddSerilog(logger);
builder.Services.AddSingleton(logger);
return logger;
}
}
Configuration Example in appsettings.json
Serilog's setup includes specifying sinks, minimum logging levels, and enrichment directly in the appsettings.json:
"Serilog": {
"Using": ["Serilog.Sinks.Console", "Serilog.Sinks.File", "Serilog.Sinks.Grafana.Loki"],
"MinimumLevel": "Debug",
"WriteTo": [
{"Name": "Console"},
{
"Name": "File",
"Args": {
"path": "logs\\log.txt",
"rollingInterval": "Day",
"retainedFileCountLimit": 7
}
},
{
"Name": "GrafanaLoki",
"Args": {
"uri": "http://localhost:3100",
"labels": [{"key": "app", "value": "webapi"}],
"propertiesAsLabels": ["app"]
}
}
],
"Enrich": ["FromLogContext", "WithMachineName", "WithThreadId"],
"Properties": {
"Application": "webapi"
}
}
This configuration demonstrates how to set up Serilog to log to the console, a file (with daily rotation and a retention policy), and Grafana Loki, including enriching logs with contextual information.
Instrumentation and Exporters in OpenTelemetry for .NET 8
In OpenTelemetry for .NET 8, instrumentation and exporters are the core components that enable the collection and forwarding of telemetry data. Instrumentation acts as the data generator, capturing detailed information about your application's operations. Exporters then take this data and send it to various analysis tools for monitoring and observability. Let's delve into how these components work together within a .NET 8 application, focusing on key examples.
Instrumentation in OpenTelemetry
Instrumentation automatically captures data from your application, requiring minimal changes to your code. This is crucial for developers who need to monitor their applications without adding extensive logging or monitoring code manually. Examples include:
AddAspNetCoreInstrumentation: Captures data related to incoming requests to your ASP.NET Core application. This helps in understanding request rates, response times, and error rates.AddHttpClientInstrumentation: Monitors the outgoing HTTP requests made by your application. It's valuable for tracking external dependencies and their impact on application performance.AddRuntimeInstrumentation: Provides insights into the runtime environment, including garbage collection, threading, and memory usage. This information is essential for diagnosing performance issues and optimizing resource usage.
Exporters in OpenTelemetry
Exporters send the captured data to various destinations, such as monitoring tools and observability platforms. They are configurable, allowing data to be sent to one or more backends simultaneously. Key exporters include:
ConsoleExporter: A simple exporter that writes telemetry data to the console. It's useful for development and debugging purposes, offering immediate visibility into the telemetry generated by your application.AddPrometheusExporter: Exports metrics to a Prometheus server, enabling powerful querying and alerting capabilities. Prometheus is widely used for monitoring applications and infrastructure, making this exporter a key component for observability.AddOtlpExporter: The OpenTelemetry Protocol (OTLP) exporter sends telemetry data to any backend that supports OTLP, including OpenTelemetry Collector. This flexibility makes it a cornerstone for applications that require comprehensive monitoring solutions.
Combining different instrumentation and exporters allows developers to tailor their observability strategy to meet their specific needs. By leveraging these components in OpenTelemetry for .NET 8, developers can ensure their applications are not only performant but also resilient and reliable.
Implementing Metrics in .NET 8 with OpenTelemetry
Implementing metrics in a .NET 8 application is essential for understanding its performance and health. OpenTelemetry facilitates this by providing tools to collect, analyze, and export metrics, such as heap usage, active connections, and thread pool metrics. Below we detail the setup process and insights gained from these metrics.
Metrics Setup Implementation
Setting up metrics collection involves configuring OpenTelemetry to gather data across the application. It's critical to initialize OpenTelemetry metrics early in the application startup process. The Init method should be called before the WebApplication instance is created to ensure all parts of the application are correctly instrumented. Conversely, the CreatePrometheusEndpoint method should be called after the app is created to set up the endpoint for scraping metrics by Prometheus.
using OpenTelemetry.Metrics;
using Serilog.Core;
public class MetricsSetup
{
private static IConfigurationSection _otelConfig;
public static void Init(WebApplicationBuilder builder, Logger logger)
{
_otelConfig = builder.Configuration.GetSection("Otel");
if (!_otelConfig.Exists() || !_otelConfig.GetValue<bool>("Enabled"))
{
logger.Warning("OpenTelemetry Metrics are disabled");
return;
}
builder.Services.AddOpenTelemetry().WithMetrics(metricsOpts =>
metricsOpts.AddAspNetCoreInstrumentation()
.AddHttpClientInstrumentation()
.AddRuntimeInstrumentation()
.AddPrometheusExporter()
);
}
public static void CreatePrometheusEndpoint(WebApplication app)
{
if (!_otelConfig.Exists() || !_otelConfig.GetValue<bool>("Enabled") || _otelConfig["Endpoint"] == null)
return;
app.UseOpenTelemetryPrometheusScrapingEndpoint();
}
}
Configuration in appsettings.json
Ensure OpenTelemetry metrics are enabled in the appsettings.json to activate metrics collection:
"Otel": {
"Enabled": true,
"Source": "webapi",
}
Insights Gained from Metrics
Metrics provide invaluable insights into operational performance:
Heap Data: Identifies memory management efficiency, highlighting potential memory leaks or optimization opportunities.
Active Connections Data: Shows the application's load, aiding in bottleneck identification for concurrent request handling.
Thread Pool Data: Reveals concurrency management effectiveness, with queue length and running threads metrics indicating potential blocked threads or areas needing throughput optimization.
By strategically implementing and analyzing metrics with OpenTelemetry, developers gain the ability to proactively enhance application performance, reliability, and user experience.
Implementing Tracing in .NET 8 with OpenTelemetry
Tracing provides deep insights into the behavior and performance of applications, enabling developers to track requests across various services and identify bottlenecks or inefficiencies. OpenTelemetry's tracing capabilities, integrated into a .NET 8 application, offer a powerful means to visualize and analyze the flow of operations. Here's how you can set it up, along with a nudge towards leveraging SQL instrumentation for comprehensive database query insights.
Tracing Setup in OpenTelemetry
The following C# code outlines the process for setting up tracing in a .NET Web API application, utilizing OpenTelemetry's extensive tracing features:
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
using Serilog.Core;
public class TracingSetup
{
public static void Init(WebApplicationBuilder builder, Logger logger)
{
var otelConfig = builder.Configuration.GetSection("Otel");
if (!otelConfig.Exists() || !otelConfig.GetValue<bool>("Enabled") || otelConfig["Endpoint"] == null)
{
logger.Warning("OpenTelemetry Tracing is disabled, or no endpoint is configured");
return;
}
var serviceName = otelConfig["ServiceName"] ?? "webapi";
builder.Services.AddOpenTelemetry().WithTracing(tracerOpts =>
tracerOpts.AddSource(serviceName)
.SetResourceBuilder(ResourceBuilder.CreateDefault().AddService(serviceName))
.AddAspNetCoreInstrumentation((opts) => opts.Filter = (req) => {
// don't trace incoming calls to /metrics
return !req.Request.Path.Value.Contains("/metrics");
})
.AddHttpClientInstrumentation((opts) => {
// don't trace outgoing calls to loki/api/v1/push
opts.FilterHttpRequestMessage = (req) => {
return !req.RequestUri?.ToString().Contains("/loki/api/v1/push") ?? false;
};
})
.AddEntityFrameworkCoreInstrumentation() // Add Entity Framework Core instrumentation
.AddOtlpExporter(otlpOptions =>
{
otlpOptions.Endpoint = new Uri(otelConfig["Endpoint"]);
})
);
}
}
This setup configures tracing for ASP.NET Core, HttpClient interactions, and Entity Framework Core operations. By exporting traces to an OTLP endpoint, it facilitates comprehensive monitoring across all parts of the application.
Configuration in appsettings.json
To activate tracing, ensure OpenTelemetry is enabled in your application's configuration:
"Otel": {
"Enabled": true,
"Source": "webapi",
"Endpoint": "http://localhost:4317"
},
SQL Instrumentation for Enhanced Database Insights
For applications leveraging SQL databases, incorporating SQL instrumentation is vital for visibility into database interactions. OpenTelemetry supports instrumentation for various SQL databases, including SQL Server and MySQL, enabling developers to capture detailed queries and database operations. To include SQL tracing in your application, explore the OpenTelemetry.Instrumentation.SqlClient and OpenTelemetry.Instrumentation.MySqlData packages. These packages provide the necessary tools to trace database requests, offering insights into query performance and potential issues.
By integrating tracing with OpenTelemetry in your .NET 8 application, you unlock the ability to monitor application flows in real-time, diagnose issues with precision, and understand the impact of database operations on overall performance. This approach ensures that you can maintain high performance and reliability as your application scales.
Writing Program.cs
using Microsoft.AspNetCore.Builder;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Serilog;
var builder = WebApplication.CreateBuilder(args);
// Setup logging
var logger = LoggerSetup.Init(builder);
// Initialize OpenTelemetry Tracing
TracingSetup.Init(builder, logger);
// Initialize OpenTelemetry Metrics
MetricsSetup.Init(builder, logger);
// Add services to the container.
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
var app = builder.Build();
// Create Prometheus metrics endpoint
MetricsSetup.CreatePrometheusEndpoint(app);
// Configure the HTTP request pipeline.
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.MapGet("/", () => Results.Redirect("/swagger")).ExcludeFromDescription();
app.Run();
This Program.cs serves as the entry point for your .NET 8 Web API application, integrating both logging with Serilog and observability with OpenTelemetry. It sets up logging at the beginning, ensuring all startup processes are captured. Then, it initializes OpenTelemetry for both tracing and metrics collection, tailored to the needs of the application as defined in your appsettings.json. Finally, it configures the application to serve metrics via a Prometheus scraping endpoint, alongside the standard setup for Swagger, controllers, and HTTPS redirection.
Integrating Jaeger and Elasticsearch for Enhanced Tracing in .NET Applications
In the world of distributed tracing, Jaeger stands out for its ability to collect, store, and visualize traces across microservices. However, when dealing with vast amounts of trace data, Jaeger alone might not suffice due to its storage limitations. This is where Elasticsearch comes into play, offering a robust backend for storing large volumes of trace data and providing enhanced querying capabilities, especially when integrated with Grafana.
Why Pair Jaeger with Elasticsearch?
- Scalable Storage: Jaeger, while effective in trace collection and visualization, benefits greatly from Elasticsearch's scalable storage solutions for handling extensive trace data.
- Advanced Querying: Elasticsearch enhances the ability to query trace data, making it easier to derive insights and pinpoint issues within Grafana.
- OpenTelemetry Support: Jaeger has embraced the OpenTelemetry protocol, ensuring compatibility with modern observability standards and allowing for deployment with multiple collectors for increased resilience and scalability.
Docker Compose Setup for Jaeger and Elasticsearch
To streamline the deployment of Jaeger with Elasticsearch as its backend, the following Docker Compose configuration can be utilized:
services:
jaeger:
restart: always
image: jaegertracing/all-in-one:1.52
depends_on:
- elasticsearch
environment:
- COLLECTOR_OTLP_ENABLED=true
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=http://elasticsearch:9200
networks:
- jaeger-net
ports:
- 4317:4317
- 16686:16686
- 4318:4318
elasticsearch:
restart: always
image: docker.elastic.co/elasticsearch/elasticsearch:8.12.0
environment:
- discovery.type=single-node
volumes:
- elasticsearch-data:/usr/share/elasticsearch/data
- ./elasticsearch/conf.yml:/usr/share/elasticsearch/config/elasticsearch.yml
networks:
- jaeger-net
ports:
- 9200:9200
networks:
jaeger-net:
volumes:
elasticsearch-data:
Elasticsearch Configuration
For Elasticsearch, the following configuration (elasticsearch/conf.yml) is recommended to facilitate development and integration with Jaeger:
################################### Production Configuration ###################################
### Author: Greg Dooper
### Description: Parameters recommended from documentation
network:
host: 0.0.0.0
################################### Cluster ###################################
cluster.name: opentrace
# This grants anonymous users superuser access to Elasticsearch
# THIS SHOULD ONLY BE USED FOR DEVELOPMENT
xpack.security.enabled: false
xpack.security.transport.ssl.enabled: false
xpack.security.http.ssl.enabled: false
This setup ensures that Jaeger can efficiently use Elasticsearch for trace storage, leveraging its powerful querying capabilities within Grafana for a comprehensive observability solution. By integrating these technologies, developers gain a deeper understanding of their applications, enabling faster issue resolution and improved system performance.
Implementing Prometheus for Monitoring in .NET Applications
Prometheus is a powerful open-source monitoring and alerting toolkit that's become the de facto standard for monitoring software in dynamic, microservices-oriented environments. Its integration into a .NET application ecosystem allows for real-time metrics collection and querying, providing invaluable insights into application performance and health. This section outlines how to configure Prometheus using Docker Compose and set up scraping for a .NET Web API application.
Docker Compose Configuration for Prometheus
To integrate Prometheus into your application stack, you can use Docker Compose to run Prometheus in a container, ensuring it's properly networked with your application services. Here's an example configuration that sets up Prometheus:
services:
prometheus:
restart: always
image: prom/prometheus:v2.49.0
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
extra_hosts:
- "webapi:${WEBAPI_IP}"
ports:
- 9090:9090
networks:
- jaeger-net
This configuration mounts a custom prometheus.yml file into the container, specifying how Prometheus should scrape metrics from your application to get metrics data. The extra_hosts entry is particularly useful for ensuring Prometheus can resolve and access your application, especially when running in Docker environments where service names may not be directly resolvable.
Prometheus Configuration (prometheus.yml)
To instruct Prometheus on where and how often to scrape metrics, you'll need to provide a prometheus.yml configuration file. Below is a basic example that sets up Prometheus to scrape metrics from a Web API service:
# my global config
global:
scrape_interval: 30s # Set the scrape interval to every 30 seconds. Default is every 1 minute.
scrape_configs:
- job_name: "webapi"
static_configs:
- targets: ["webapi:5000"]
This configuration directs Prometheus to scrape metrics from the target webapi:5000 every 30 seconds. Adjust the targets array to match the address of your .NET Web API service. This setup is crucial for capturing timely, relevant metrics data from your application, allowing Prometheus to store and query this data over time.
Integrating Loki for Log Aggregation in .NET Applications
Loki is a horizontally-scalable, highly-available, multi-tenant log aggregation system inspired by Prometheus. It's designed to be very cost-effective and easy to operate, making it a perfect fit for collecting and viewing logs in a cloud-native environment. Integrating Loki with .NET applications enhances the observability by providing a powerful platform for querying and monitoring logs. This section will guide you through setting up Loki using Docker Compose.
Docker Compose Configuration for Loki
To add Loki to your observability stack, to receive logs from your .net app, you can use Docker Compose for easy deployment. Below is a basic Docker Compose configuration for running Loki:
services:
loki:
restart: always
image: grafana/loki:2.9.3
command: -config.file=/etc/loki/local-config.yaml
networks:
- jaeger-net
ports:
- 3100:3100
This configuration starts a Loki instance using the grafana/loki:2.9.3 image. Loki is configured to use the default settings specified in the local-config.yaml file contained within the Docker image, which is suitable for many use cases right out of the box.
Default Configuration of Loki
The default configuration for Loki is designed to get you up and running quickly, with sensible defaults for most settings. It includes configurations for the Loki server, ingesters, and storage options. When running Loki with the default configuration, it stores the data on disk in the container. For production environments, you might want to customize the configuration to change the storage backend, adjust retention policies, or configure multi-tenant capabilities.
Setting Up Grafana for Dashboard Visualization in .NET Applications
Grafana is a premier open-source platform for monitoring and data visualization, providing rich insights into metrics, logs, and traces from various data sources like Prometheus, Loki, Jaeger, and Elasticsearch. Integrating Grafana with your .NET applications allows for comprehensive observability, enabling you to visualize and analyze your data effectively. Here’s how to set up Grafana using Docker Compose, including auto-provisioning of data sources for a seamless observability experience.
Docker Compose Configuration for Grafana
For a quick start, the following Docker Compose configuration can be used to deploy Grafana, specifying not only the container setup but also how Grafana should be provisioned with data sources automatically:
services:
grafana:
restart: always
image: grafana/grafana:10.1.6
networks:
- jaeger-net
ports:
- 3000:3000
volumes:
- grafana-data:/var/lib/grafana
- ./grafana/provisioning:/etc/grafana/provisioning
This setup mounts a provisioning directory, allowing you to configure data sources and dashboards that Grafana will load automatically on startup.
Auto-Provisioning Data Sources
To configure Grafana data sources through provisioning, you can define them in the ./grafana/provisioning/datasources/sources.yml file. This approach automates the addition of Prometheus, Loki, Jaeger, and Elasticsearch as data sources in Grafana:
apiVersion: 1
datasources:
- name: Jaeger
type: jaeger
uid: provisioned-jaeger-datasource
url: http://jaeger:16686
access: proxy
basicAuth: false
- name: Prometheus
type: prometheus
uid: provisioned-prometheus-datasource
url: http://prometheus:9090
access: proxy
basicAuth: false
httpMethod: POST
- name: Loki
type: loki
uid: provisioned-loki-datasource
url: http://loki:3100
access: proxy
basicAuth: false
- name: ElasticSearch
type: elasticsearch
uid: provisioned-elasticsearch-datasource
url: http://elasticsearch:9200
access: proxy
basicAuth: false
jsonData:
timeField: startTimeMillis
interval: Daily
maxConcurrentShardRequests: 5
index: "[jaeger-span-]YYYY-MM-DD"
This configuration ensures that Grafana is immediately aware of and can query data from these sources, facilitating a rich observability experience right from the start.
Understanding the Performance Dashboard in Grafana
The provided screenshot is a glimpse into the performance dashboard available in the ready-to-use GitHub repository net8-webapi-monitoring. This repository contains all the necessary services, along with an example web API application and Grafana, with a performance dashboard already provisioned. Let's break down the key metrics visualized on this dashboard and understand how to interpret them.
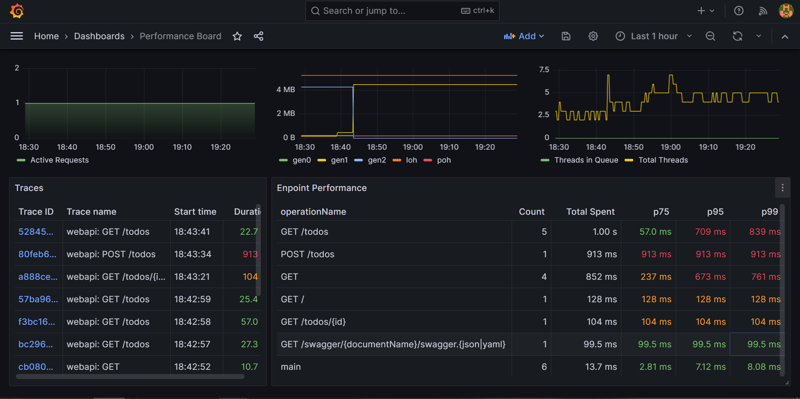
Heap Size Metrics
Heap size metrics are crucial indicators of memory usage by your .NET application. They are broken down into several generations, as seen on the dashboard:
Gen 0, 1, 2: These are different generations of heap memory used by the garbage collector. Generation 0 is for short-lived objects, and with each subsequent generation (1 and 2), the objects are expected to have longer lifetimes. Observing these can help identify memory allocation patterns and potential issues like memory leaks.
LOH (Large Object Heap): This heap is reserved for large objects (85,000 bytes and larger). Frequent allocations in the LOH can lead to memory fragmentation.
POH (Pinned Object Heap): Introduced in .NET 5, this heap is for objects that the garbage collector should not move in memory (pinned objects). Monitoring this can help avoid performance issues due to excessive pinning, which can impede garbage collection.
Thread Pool Metrics
Thread Pool Size: This metric shows the number of threads available in the thread pool. An adequately sized thread pool helps ensure that your application can process incoming requests without unnecessary delays.
Thread Pool Queue: It reflects the number of tasks waiting to be executed. A continuously growing queue might indicate that the thread pool size is insufficient for the workload, leading to slower request processing and degraded performance.
Trace Duration Metrics
Trace Duration: This is the time taken to complete a request. High trace durations could point to performance bottlenecks in your application.
Percentiles (p75, p95, p99): Percentiles are more informative than averages, especially in performance monitoring. They help understand the distribution of request durations. For example, p95 tells you that 95% of the requests are faster than this value. Percentiles are crucial because averages can be misleading and do not account for variability within data.
By examining these metrics, developers can make informed decisions about where to focus optimization efforts. When performance issues arise, these metrics guide developers to the problem areas, whether it's inefficient memory usage, inadequate thread pool size, or slow-executing parts of the code.
For a deep dive into the performance of individual endpoints, developers can look at the traces section. Duration percentiles for each trace give a clear picture of the user experience and help identify outliers in request handling times.
Analyzing Trace Data in Grafana with Jaeger
Traces are an essential tool for understanding the behavior of requests within your application. The attached screenshots demonstrate the use of Jaeger within Grafana to analyze a specific trace from a performance dashboard.
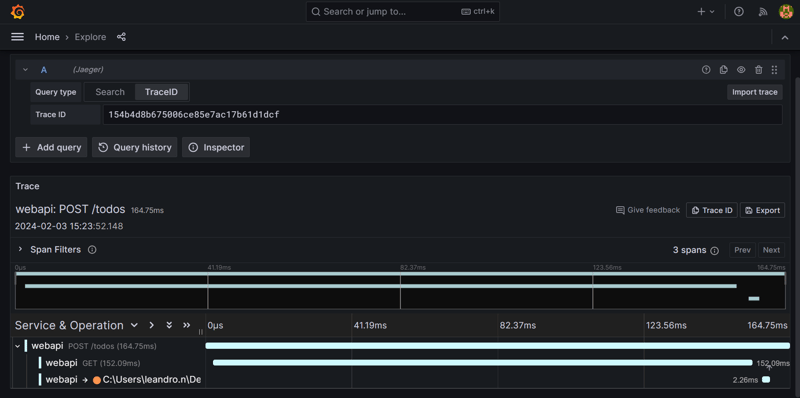
Trace Overview
The trace provided shows a POST /todos request with a total duration of 164.75ms. Inside this trace, we can observe individual spans that record discrete operations:
- The
GETspan, which is most likely an HTTP call made usingHttpClient, takes up most of the trace's duration, clocking in at 152.09ms. - The subsequent database operation span, presumably captured by Entity Framework instrumentation, takes a mere 2.26ms.
The Impact of External Calls
The investigation reveals that the predominant contributor to the request's latency is the call to an external API, catfact.ninja, which provides a cat fact for each todo item. This external dependency is what's slowing down the request, not the database insertion that follows.
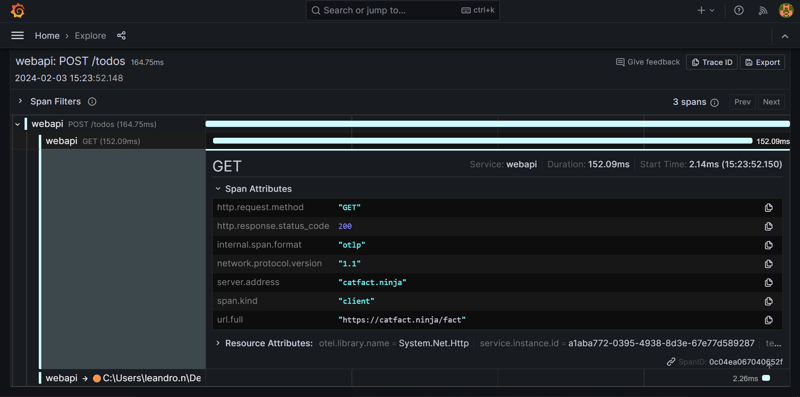
Insights from Span Attributes
By expanding the GET span, we have access to a wealth of information including the HTTP method, the status code returned, and the full URL that was called. This level of detail is invaluable when diagnosing performance issues, as it allows developers to identify external services that may be affecting the performance of their application.
Actionable Findings
In this particular case, the trace clearly indicates that optimization efforts should be directed towards the external HTTP request rather than the database interaction. Solutions might include implementing caching for the external API data or fetching the data asynchronously to prevent it from blocking the critical path of the request handling.
Analyzing Error Logs with Grafana and Loki
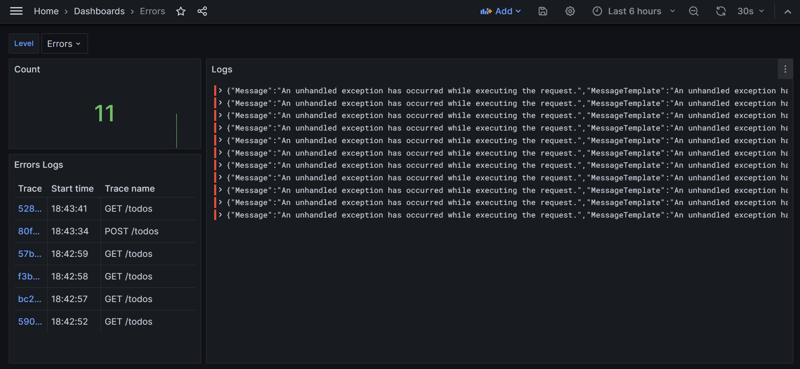
The attached screenshot provides a view of the error logs from the dashboard that is available in the pre-configured GitHub repository net8-webapi-monitoring. This repository includes all necessary services along with a sample web API application, and Grafana dashboards provisioned for both performance and error monitoring. Here's how to understand and utilize the error logs dashboard.
Error Logs Dashboard Overview
The error logs dashboard is a crucial tool for monitoring and identifying issues within your application in real-time. The dashboard provides:
- Error Count: A quick overview of the number of errors that have occurred within a specified time frame.
- Logs Panel: Detailed log messages that allow you to see the exact error messages being generated by your application.
- Trace Identification: Showing only traces that ended in error. easy for cross referencing them with logs. There is a possibility to connect the traces to the logs, but i never felt the need to do it yet.
Understanding and Utilizing the Dashboard
Count Panel: This panel shows the total count of error-level logs, giving an immediate indication of the system's health. A sudden spike in errors can be a red flag that requires immediate attention. the panel has a graph behind showin the errors over time
Logs Panel: Here, you can inspect the error messages themselves. It allows developers to quickly scan through the error logs, identify patterns, or look for specific issues without needing to sift through potentially thousands of log entries manually.
Trace Links: When you have an error log that requires further investigation, the trace ID links you directly to the traces related to that error, providing a pathway to diagnose the issue in the context of the request flow.
Filter: At the top of the dashboard you have a filter varialbe to change between Errors, Warnings and All logs.
Reading the Logs
Each log entry is structured to provide critical information at a glance. In this case, the logs are reporting "An unhandled exception has occurred while executing the request," indicating that exceptions are being thrown but not caught within the application's code.
Importance of Error Rate Monitoring
Monitoring the error rate is essential for maintaining a high-quality user experience. It helps in:
- Proactive Troubleshooting: Identifying and resolving issues before they impact a significant number of users.
- Impact Analysis: Understanding the scope and impact of particular errors.
- Alerting: Setting up alerts based on error thresholds to notify developers or systems administrators to take immediate action.
By leveraging the error logs dashboard in Grafana, powered by log data from Loki, teams can maintain a pulse on the application's error rates and quickly respond to and resolve issues as they arise.
Conclusion: Embracing Observability for Continuous Improvement
As we wrap up our exploration of monitoring .NET 8 APIs, it's crucial to emphasize the importance of having an observability framework in place. The net8-webapi-monitoring GitHub repository stands as a testament to the power of being prepared with a robust monitoring setup. It offers a ready-to-run collection of services that provide immediate insights into your application's performance and health.
The dashboards included are by no means exhaustive or perfect, but they are a significant first step towards full observability. They demonstrate the fundamental truth in software engineering that while we strive for perfection, it should not come at the cost of progress. "Don't let the perfect be the enemy of the good," as the adage goes, is particularly relevant here.
These tools and dashboards are meant to be iterated upon. As your system grows and evolves, so too will your understanding of what metrics are most critical to monitor and what constitutes an improvement. What we consider an enhancement today may change as our applications and businesses develop. Therefore, it's essential to build systems that are not only robust but also adaptable.
Encourage yourself and your team to view these monitoring systems as living entities that grow with your application. Start with what is "good enough" today, and plan for the improvements that will be necessary tomorrow. The key is to begin with a solid foundation that can be built upon, learning and evolving as your system does.
The tools we've discussed—Grafana, Prometheus, Loki, Jaeger, and OpenTelemetry—are powerful allies in this journey. They provide the visibility we need not just to react to issues but to anticipate them. With this setup, you're well-equipped to understand your application deeply, to make informed decisions, and to ensure that your users enjoy the best experience possible.
As we move forward, let us embrace the mindset of continuous improvement, not just in our code, but in how we observe and understand our systems. The ready-to-run repo is your starting block; where you take it from here is limited only by your commitment to learning, adaptation, and improvement.
Posted on February 4, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related