Building a self-creating website with Supabase and AI

Niklas Lepistö
Posted on April 23, 2024

TL;DR:
Built with Supabase, Astro, Unreal Speech, Stable Diffusion, Replicate, Metropolitan Museum of Art
Leverages Supabase Edge Functions, Storage, Webhooks, Database Triggers and pg_cron
Scheduled job every hour triggers a new insert which then triggers Webhook calls to Edge Functions to start generating new assets
Back again writing about another Supabase hackathon project! This is about our most recent one called Echoes of Creation and focuses on the technical details rather than going explaining how it was built in general.
The idea
My friend and I have had this idea of building a website that would "destroy" and re-create itself automatically every hour for over a year now. Idea was to kind of portray how AI has made an impact and especially how it is affecting the creative fields. There would be a countdown on the page to show when a new version is generated, and we would detoriate the content using various effects little by little as the time would tick closer to zero. It's basically an art project which we think would've been cool to do at some point, and this Supabase hackathon turned out to be the time to do it! Although, due to the time restrictions, we had to change up the idea a bit.
Initially we had thought of creating a completely new layout each time the page was created, alongside with the new content. This was, however, a very technically challenging to do especially if you wanted to do using just CSS and HTML: you don't want things to just be boxed and layout out vertically like every other web page out there. So the option would've been to use WebGL to leverage 3D space if we wanted to do our very first idea. This might be a future improvement for the project, however since I'm not as experienced in WebGL as I'd like to be, it was a no-go if we wanted to make it in time of the deadline.
We talked on Discord and my friend came up with a great idea: what if instead of just AI detoriating or destroying the site we'd tell a story of an artist who is struggling in the current world filled with AI. And we'd do a scroll-based website instead, ideally just animating the content so that it'd feel that you are in a 3D space. And each website is the a new "thought/creative flow process" inside the artist's mind. We both were really excited about this idea, and began to work.
Building the project
When we started we had a clear vision of the whole scroll-based story and animation, however we ditched most of it as we moved on. Shortly: we thought it would be cool if the "camera" would change angles and spin the content in different directions on each site variant to make it feel like you're kind of navigating inside the artist's brain. We implemented this and it worked well (albeit sometimes a bit nauseating), however as we thought about the story and structure more, this kind of navigation didn't make sense anymore. We decided to focus more on the narrative via sounds and other content.
But let's focus on the actual gist of the project now: Supabase Edge Functions.
Before starting few things:
- there are three database tables:
thoughts,artwork,thought_textsthoughtis the whole story narrative: the creative process is "one big thought"thought_textscontains all texts in the storty and links to their audio filesartworkcontains, well, all the artwork; both generated and fetched from Met Museum API
Generating artwork
In the project we ended up using only two Edge Functions: one creating artwork called generate and one creating texts and speech called create-speech. Let's start with the artwork one first which looks something like this:
/* eslint-disable @typescript-eslint/ban-ts-comment */
// Follow this setup guide to integrate the Deno language server with your editor:
// https://deno.land/manual/getting_started/setup_your_environment
// This enables autocomplete, go to definition, etc.
import { corsHeaders } from "../_shared/cors.ts";
import { createClient } from "https://esm.sh/@supabase/supabase-js@2.42.3";
import randomSample from "https://esm.sh/@stdlib/random-sample@0.2.1";
import Replicate from "https://esm.sh/replicate@0.29.1";
import { base64 } from "https://cdn.jsdelivr.net/gh/hexagon/base64@1/src/base64.js";
const supabaseClient = createClient(
Deno.env.get("SUPABASE_URL") ?? "",
Deno.env.get("SUPABASE_SERVICE_ROLE_KEY") ?? ""
);
const replicate = new Replicate({
auth: Deno.env.get("REPLICATE_API_TOKEN") ?? "",
});
// @ts-expect-error
Deno.serve(async (req) => {
if (req.method === "OPTIONS") {
return new Response("ok", { headers: corsHeaders });
}
const { record } = await req.json();
const thought_id = record.id;
if (!thought_id) {
return new Response("Missing thought_id", {
status: 400,
headers: { "Content-Type": "application/json", ...corsHeaders },
});
}
const allObjectIDsResponse = await fetch(
"https://collectionapi.metmuseum.org/public/collection/v1/objects?departmentIds=11",
{
method: "GET",
headers: {
"Content-Type": "application/json",
Accept: "application/json",
},
}
);
const { objectIDs } = await allObjectIDsResponse.json();
const listOfArtworks = [];
const addedIDs: number[] = [];
while (listOfArtworks.length < 80) {
const randomObjectID = randomSample(objectIDs, { size: 1 })[0];
if (addedIDs.includes(randomObjectID)) continue;
const res = await fetch(
`https://collectionapi.metmuseum.org/public/collection/v1/objects/${randomObjectID}`,
{
method: "GET",
headers: {
"Content-Type": "application/json",
Accept: "application/json",
},
}
);
const artwork = await res.json();
if (!artwork.primaryImageSmall) continue;
addedIDs.push(artwork.objectID);
listOfArtworks.push({
image_url: artwork.primaryImageSmall,
artist_name: artwork.artistDisplayName,
title: artwork.title,
is_main: listOfArtworks.length === 0,
is_variant: false,
thought_id,
});
}
const mainImage = listOfArtworks[0];
const output = await replicate.run(
"yorickvp/llava-13b:b5f6212d032508382d61ff00469ddda3e32fd8a0e75dc39d8a4191bb742157fb",
{
input: {
image: mainImage.image_url,
top_p: 1,
prompt: "Describe this painting by " + mainImage.artist_name,
max_tokens: 1024,
temperature: 0.2,
},
}
);
const file = await fetch(mainImage.image_url).then((res) => res.blob());
const promises = [];
for (let i = 0; i < 8; i++) {
const body = new FormData();
body.append(
"prompt",
output.join("") + `, a painting by ${mainImage.artist_name}`
);
body.append("output_format", "jpeg");
body.append("mode", "image-to-image");
body.append("image", file);
body.append("strength", clamp(Math.random(), 0.4, 0.7));
const request = fetch(
`${Deno.env.get(
"STABLE_DIFFUSION_HOST"
)}/v2beta/stable-image/generate/sd3`,
{
method: "POST",
headers: {
Accept: "application/json",
Authorization: `Bearer ${Deno.env.get("STABLE_DIFFUSION_API_KEY")}`,
},
body,
}
);
promises.push(request);
}
const results = await Promise.all(promises);
const variants = await Promise.all(results.map((res) => res.json()));
await supabaseClient.from("artworks").insert(listOfArtworks);
for (let i = 0; i < variants.length; i++) {
const variant = variants[i];
const randomId = Math.random();
await supabaseClient.storage
.from("variants")
.upload(
`${thought_id}/${randomId}.jpeg`,
base64.toArrayBuffer(variant.image),
{
contentType: "image/jpeg",
}
);
await supabaseClient.from("artworks").insert({
image_url: `${Deno.env.get(
"SUPABASE_URL"
)}/storage/v1/object/public/variants/${thought_id}/${randomId}.jpeg`,
artist_name: mainImage.artist_name,
is_main: false,
is_variant: true,
thought_id,
});
}
await supabaseClient
.from("thoughts")
.update({ generating: false })
.eq("id", thought_id);
return new Response(JSON.stringify({ main: mainImage }), {
headers: { "Content-Type": "application/json", ...corsHeaders },
});
});
function clamp(value: number, min: number, max: number) {
return Math.min(Math.max(value, min), max);
}
Breaking it down, we'll first check if there is a new thought ID that needs artwork to be generated from before we fetch any data. I added the 400 response there just so that I'd be able to debug if Webhooks would fail for some reason later. The record data structure is passed automatically in the Webhook triggers, however we'll touch those later!
const { record } = await req.json();
const thought_id = record.id;
if (!thought_id) {
return new Response("Missing thought_id", {
status: 400,
headers: { "Content-Type": "application/json", ...corsHeaders },
});
}
Then we'll hook to Met Museum's API to fetch publicly available artwork in their collections. Isn't it amazing that a museum has a free and public API! These artworks will serve as "ideas" the artist has during the creative flow, in which one of them will be the main piece of art they create.
const allObjectIDsResponse = await fetch(
"https://collectionapi.metmuseum.org/public/collection/v1/objects?departmentIds=11",
{
method: "GET",
headers: {
"Content-Type": "application/json",
Accept: "application/json",
},
}
);
Using a department ID as a URL param will only return pieces that are categorized under a specific department, such as "Drawings and Prints", "Modern Art", "European Paintings." In our case, we use the ID 11 which corresponds to "European Paintings" which includes over 2500 pieces of art! The endpoint we used returns a list of IDs attached the pieces which we'll use to fetch the actual data associated to them.
You can fetch pieces from multiple departments by splitting the list with the pipe
|character, so?departmentIds=11|9would return you "European Paintings" and "Drawings and Prints." You can see the available departments in the API documentation.
We'll loop the list of 80 IDs, picking a random piece of art from the original ID list. I'm using stdlib's random-sample which uses Fisher-Yates as its algorithm to randomize entries as I didn't want to bloat my own code too much with these kind of helpers. Fetching the artwork data I unfortunately noticed that some of the artwork do not have images available. This meant that we'll need to loop the list until we have 80 pieces with images. For the main piece of the story we keep things simple and just pick the first one in the list. We store some metadata along the way, too, which we can/will use later.
const { objectIDs } = await allObjectIDsResponse.json();
const listOfArtworks = [];
const addedIDs: number[] = [];
while (listOfArtworks.length < 80) {
const randomObjectID = randomSample(objectIDs, { size: 1 })[0];
if (addedIDs.includes(randomObjectID)) continue;
const res = await fetch(
`https://collectionapi.metmuseum.org/public/collection/v1/objects/${randomObjectID}`,
{
method: "GET",
headers: {
"Content-Type": "application/json",
Accept: "application/json",
},
}
);
const artwork = await res.json();
if (!artwork.primaryImageSmall) continue;
addedIDs.push(artwork.objectID);
listOfArtworks.push({
image_url: artwork.primaryImageSmall,
artist_name: artwork.artistDisplayName,
title: artwork.title,
is_main: listOfArtworks.length === 0,
is_variant: false,
thought_id,
});
}
const mainImage = listOfArtworks[0];
Note: The
primaryImageSmallattribute has a link to a more web-suitable format and size. There is aprimaryImageattribute, too, however those links can contain images of multiple megabytes!
Now we get to the part where we use AI the first time: generating a prompt from the main image which will be used to generate variants.
We're using LLaVa model to get a description of the main painting. Then we fetch the image file from the URL we got from the previous step and use it as the base for Stable Diffusion 3 to generate variants from. This allows us to keep the original image structure & colors and just modify some parts of it to make it look a copy. Depending on the strength param, the end result is either identical or very different from the original image. If you passed 1, SD would consider that you didn't pass an image at all, so we pick a number between 0.4 and 0.7, which would give a strength of 30-60% for the original image in the mix.
const output = await replicate.run(
"yorickvp/llava-13b:b5f6212d032508382d61ff00469ddda3e32fd8a0e75dc39d8a4191bb742157fb",
{
input: {
image: mainImage.image_url,
top_p: 1,
prompt: "Describe this painting by " + mainImage.artist_name,
max_tokens: 1024,
temperature: 0.2,
},
}
);
const file = await fetch(mainImage.image_url).then((res) => res.blob());
const promises = [];
for (let i = 0; i < 8; i++) {
const body = new FormData();
body.append(
"prompt",
output.join("") + `, a painting by ${mainImage.artist_name}`
);
body.append("output_format", "jpeg");
body.append("mode", "image-to-image");
body.append("image", file);
body.append("strength", clamp(Math.random(), 0.4, 0.7));
const request = fetch(
`${Deno.env.get(
"STABLE_DIFFUSION_HOST"
)}/v2beta/stable-image/generate/sd3`,
{
method: "POST",
headers: {
Accept: "application/json",
Authorization: `Bearer ${Deno.env.get("STABLE_DIFFUSION_API_KEY")}`,
},
body,
}
);
promises.push(request);
}
The new Stable Diffusion 3 endpoints use
FormDatato take in params, changing from the previous JSON payloads. A welcome improvement is that it can now return JPEG or WebP formats instead of PNG which means we can save on storage space!
Lastly we'll handle storing the variants into Supabase Storage and updating the thought record to not be in generating state anymore. This is pretty straight-forward: first we bulk insert all the artworks from the Met Museum API which is just links to images, and then we upload each generated variant to the Storage. I'm using Math.random to generate a "random" ID as the file name for the images as I don't care what they are called (semantically): they're just going be placed under a specific directory with the thought ID in the path which helps us to keep track which images are part of which thought. We're also creating records in the "artwork" table with links to the images, so we're able to fetch these images along with the other content without any extra hassle.
const results = await Promise.all(promises);
const variants = await Promise.all(results.map((res) => res.json()));
await supabaseClient.from("artworks").insert(listOfArtworks);
for (let i = 0; i < variants.length; i++) {
const variant = variants[i];
const randomId = Math.random();
await supabaseClient.storage
.from("variants")
.upload(
`${thought_id}/${randomId}.jpeg`,
base64.toArrayBuffer(variant.image),
{
contentType: "image/jpeg",
}
);
await supabaseClient.from("artworks").insert({
image_url: `${Deno.env.get(
"SUPABASE_URL"
)}/storage/v1/object/public/variants/${thought_id}/${randomId}.jpeg`,
artist_name: mainImage.artist_name,
is_main: false,
is_variant: true,
thought_id,
});
}
await supabaseClient
.from("thoughts")
.update({ generating: false })
.eq("id", thought_id);
Updating the thought record at the end will trigger a Webhook call to trigger a deployment in Cloudflare pages. This is because the site doesn't use Server-Side Rendering to access data dynamically, so we'll need to rebuild it each time there is a new thought (which is done generating content). We'll be adding SSR in the future so that you can navigate back and forth the thoughts to see how it has progressed from the original one!
Generating speech
The second function called, which I think is the coolest part of this project, is used to generate AI speech over some texts in the site. It looks like the following and we'll break it down below.
import { corsHeaders } from "../_shared/cors.ts";
import { createClient } from "https://esm.sh/@supabase/supabase-js@2.42.3";
import Replicate from "https://esm.sh/replicate@0.29.1";
import randomSample from "https://esm.sh/@stdlib/random-sample@0.2.1";
// Follow this setup guide to integrate the Deno language server with your editor:
// https://deno.land/manual/getting_started/setup_your_environment
// This enables autocomplete, go to definition, etc.
// Setup type definitions for built-in Supabase Runtime APIs
/// <reference types="https://esm.sh/@supabase/functions-js/src/edge-runtime.d.ts" />
const supabaseClient = createClient(
Deno.env.get("SUPABASE_URL") ?? "",
Deno.env.get("SUPABASE_SERVICE_ROLE_KEY") ?? ""
);
const replicate = new Replicate({
auth: Deno.env.get("REPLICATE_API_TOKEN") ?? "",
});
Deno.serve(async (req) => {
if (req.method === "OPTIONS") {
return new Response("ok", { headers: corsHeaders });
}
const voice = randomSample(["Scarlett", "Dan", "Liv", "Will", "Amy"], {
size: 1,
})[0];
const { record } = await req.json();
const thought_id = record.id;
const thoughtIdToUse = thought_id === 1 ? thought_id : thought_id - 1;
const { data: thought } = await supabaseClient
.from("thoughts")
.select(
`
id,
thought_texts(
index,
text
)
`
)
.eq("id", thoughtIdToUse);
const thoughtTexts = thought[0].thought_texts.sort(
(a, b) => a.index - b.index
);
for (let i = 0; i < thoughtTexts.length; i++) {
let newText = thoughtTexts[i].text;
if (thought_id !== 1) {
const input = {
prompt: `Write the following differently but keep the style of it being your thought: ${thoughtTexts[i].text}`,
temperature: 1.0,
frequency_penalty: 1.0,
prompt_template:
"<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nReturn info wrapped as text snippet wrapped in \`\`\`. If your suggestion is longer than 150 characters, make it shorter.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
};
const textResponse = await replicate.run(
"meta/meta-llama-3-70b-instruct",
{
input,
}
);
newText = textResponse.join("").replace(/\`\`\`/g, "");
}
const options = {
method: "POST",
headers: {
accept: "application/json",
"content-type": "application/json",
Authorization: `Bearer ${Deno.env.get("UNREAL_SPEECH_API_KEY")}`,
},
body: JSON.stringify({
Text: newText,
VoiceId: voice,
Bitrate: "192k",
Speed: "0",
Pitch: voice === "Dan" || voice === "Will" ? "0.96" : "1.0",
TimestampType: "word",
}),
};
const voiceResponse = await fetch(
Deno.env.get("UNREAL_SPEECH_API_URL"),
options
);
const voiceResponseJson = await voiceResponse.json();
const blob = await fetch(voiceResponseJson.OutputUri).then((r) => r.blob());
const jsonBlob = await fetch(voiceResponseJson.TimestampsUri).then((r) =>
r.blob()
);
await supabaseClient.storage
.from("speeches")
.upload(`${thought_id}/${i}.json`, jsonBlob, {
contentType: "application/json",
});
await supabaseClient.storage
.from("speeches")
.upload(`${thought_id}/${i}.mp3`, blob, {
contentType: "audio/mpeg",
});
await supabaseClient.from("thought_texts").insert({
thought_id,
text: newText,
audio_url: `${Deno.env.get(
"SUPABASE_URL"
)}/storage/v1/object/public/speeches/${thought_id}/${i}.mp3`,
index: i,
});
}
await supabaseClient
.from("thoughts")
.update({ generating: false })
.eq("id", thought_id);
return new Response(JSON.stringify({ check: "database" }), {
headers: { "Content-Type": "application/json" },
});
});
Creating AI speech isn't that difficult thing to do, however it is a bit challenging to find an API that doesn't cost you your kidneys. Luckily I ran into Unreal Speech which has some pretty generous free monthly tier. However it will not suffice for us to run the site generations for a over month, so I'll need to do some tricks here and there to keep things running (or just open up my wallet).
With Unreal Speech, you have five voices to choose from: "Scarlett", "Dan", "Liv", "Will", "Amy." We'll only need one as the narrator (i.e. artist) should always be a singular "person" so we'll use the same random-sample helper to pick one of these voices.
const voice = randomSample(["Scarlett", "Dan", "Liv", "Will", "Amy"], {
size: 1,
})[0];
Then instead of always having the same texts read out loud in different voices, we generate new texts for each new thought record. And in order to do this, we'll need the previous thought texts to base these new texts on so that we keep the original meaning throughout each iteration. Here we're using Meta's LLama 3 model to generate the texts as it's cheap and fast. The promp template is using a special syntax to direct the model to reply in specific way. It works in similar fashion as GPT4, however I do prefer the JSON array syntax over this speciality. There are guides how to use this template syntax in the model's Replicate page. The model returns the text as a stream, however since we just want the whole string at once, we'll need to join each word together in the end.
const { data: thought } = await supabaseClient
.from("thoughts")
.select(
`
id,
thought_texts(
index,
text
)
`
)
.eq("id", thoughtIdToUse);
const thoughtTexts = thought[0].thought_texts.sort(
(a, b) => a.index - b.index
);
for (let i = 0; i < thoughtTexts.length; i++) {
let newText = thoughtTexts[i].text;
if (thought_id !== 1) {
const input = {
prompt: `Write the following differently but keep the style of it being your thought: ${thoughtTexts[i].text}`,
temperature: 1.0,
frequency_penalty: 1.0,
prompt_template:
"<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nReturn info wrapped as text snippet wrapped in \`\`\`. If your suggestion is longer than 150 characters, make it shorter.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
};
const textResponse = await replicate.run(
"meta/meta-llama-3-70b-instruct",
{
input,
}
);
newText = textResponse.join("").replace(/\`\`\`/g, "");
}
// More code here...
}
For the very first thought we wanted to keep the original story texts and just generate speech for them.
Next we'll start generating the audio. We'll do a regular POST call to the Unreal Speech API with some params:
-
VoiceIdis the voice we pick -
Bitrateis the sound quality and we'll keep it as 192k to keep the files relatively small -
Speedis 0 so we let the AI talk at a "normal" pace instead of slowing it down or speeding it up - "Pitch" we adjust a bit based on if the voice is a male voice to give it a bit deeper sound
- "TimestampType" allows us to define if we want a transcript where the file is timestamped by sentence or by word. We go with "word" as we planned to do word highlighting in the app whenever the audio is playing (didn't have time to implement this for the hackathon).
Note that we are using the /speech endpoint from Unreal Speech. It temporarily uploads the audio and transcript on their servers and provides an URL to these files. There is also a /stream endpoint which allows you to stream back audio in 0.3s, and /synthesisTasks which allows you to create scheduled audio generation.
After this audio generation is done, we fetch the audio and transcript files from the URLs provided, and upload them to Supabase Storage. Lastly, we insert the new text and reference to the audio file in the thought_texts table.
const options = {
method: "POST",
headers: {
accept: "application/json",
"content-type": "application/json",
Authorization: `Bearer ${Deno.env.get("UNREAL_SPEECH_API_KEY")}`,
},
body: JSON.stringify({
Text: newText,
VoiceId: voice,
Bitrate: "192k",
Speed: "0",
Pitch: voice === "Dan" || voice === "Will" ? "0.96" : "1.0",
TimestampType: "word",
}),
};
const voiceResponse = await fetch(
Deno.env.get("UNREAL_SPEECH_API_URL"),
options
);
const voiceResponseJson = await voiceResponse.json();
const blob = await fetch(voiceResponseJson.OutputUri).then((r) => r.blob());
const jsonBlob = await fetch(voiceResponseJson.TimestampsUri).then((r) =>
r.blob()
);
await supabaseClient.storage
.from("speeches")
.upload(`${thought_id}/${i}.json`, jsonBlob, {
contentType: "application/json",
});
await supabaseClient.storage
.from("speeches")
.upload(`${thought_id}/${i}.mp3`, blob, {
contentType: "audio/mpeg",
});
await supabaseClient.from("thought_texts").insert({
thought_id,
text: newText,
audio_url: `${Deno.env.get(
"SUPABASE_URL"
)}/storage/v1/object/public/speeches/${thought_id}/${i}.mp3`,
index: i,
});
Finally, we update the thought record to not be in generating state again. This is just to make sure we trigger the Webhook to build the site always when all the newly generated data is there.
await supabaseClient
.from("thoughts")
.update({ generating: false })
.eq("id", thought_id);
Scheduled job and Webhook
Now that we have the main functionality done, we can do some simple scheduled jobs with triggers. All we need to do is enable pg_cron extension and Webhook functionality in the Database Settings.
After this is done, the following SQL snippet allows us to invalidate previous thoughts (i.e. make them not be the active thought), and then create a new one each hour. Very simple stuff!
create function create_thought () returns void as $$
BEGIN
UPDATE thoughts
SET current = false
WHERE current = true;
INSERT INTO thoughts (created_at)
VALUES (NOW());
END;
$$ language plpgsql;
select cron.schedule ('hourly-thoughts', '0 * * * *', 'SELECT create_thought()');
And since we need to only trigger the generation processes whenever there is a new thought, we just need to create two Webhooks to listen to these database events and trigger a call to our Edge Functions: one for generate and one for create-speech
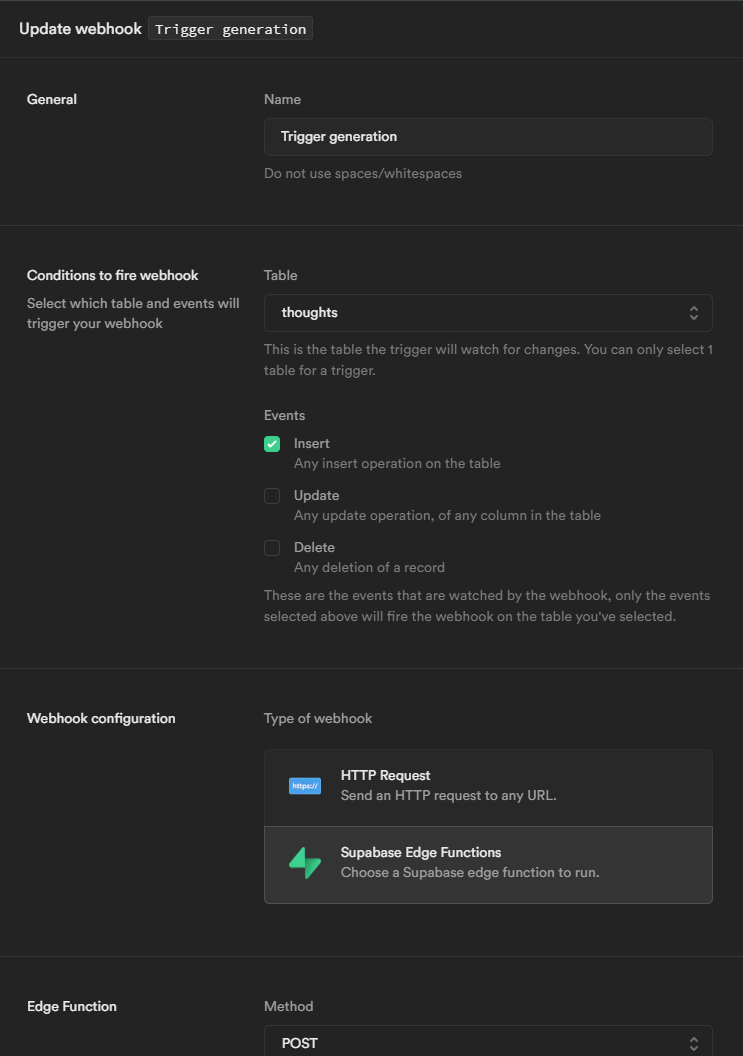
I hadn't used the Webhook functionality earlier other than just checking the UI a bit, so I was very pleasantly surprised to see (and remind myself since I think I've read about this in some of the blog posts..) that you actually can just select a Supabase Edge Function from the settings! Supa cool.
Remember to add
Authorizationheader withBearertoken as the value so that the Function triggers work with these Webhooks! Otherwise you'll run into unauthorized errors (which can be caught in the Function logs). This is something which would be nice to have there by default.
Now remember earlier when we did the updates to the thought record to change the generating state to false? And that we need to trigger new deployments each time this happens? We use same Webhook functionality to do that! So in similar fashion as above with the other Webhooks, only difference this time is to select the UPDATE event instead, keep the HTTP Request option as the type, and then just inputting your provider's deployment build webhook URL as the URL value.
And that's it: now we have a self generating website! On the website I'm just fetching the current thought and displaying all the data I have for that thought. This fetching is only done once when the site builds which is pretty fast. It also reduces the amount of traffic flowing to your Supabase instance which is always nice: it's scalable solution (to some extent).
// The only Supabase call in client code
const { data: thought } = await supabase
.from('thoughts')
.select(`
id,
created_at,
current,
generating,
thought_texts(
index,
audio_url,
text
),
artworks(
is_main,
is_variant,
image_url,
artist_name,
title
)
`)
.eq('current', true)
.single()
It was (and still is) a very ambitious project in terms of styling and the things we visioned to do, and we both just love the concept behind it. It's truly an art project for us.
And while I'm happy that we got the project ready during the hackathon, I'm a bit disappointed that we weren't able to do all the things we wanted. We had a lot of problems in the end regarding the scrolling (still learning GSAP) and other styling issues. In the end a lot of curners were cut just push it out. 'Tis what it is, though, and we did have fun during this whole process: these hackathons are great and will keep on participating in them in the future.
Anyways, keep going back to the site every now and then as we keep on building until we're satisfied with the end result. For now we'll take a small break from it, though, and focus on working on some of our other projects in the meanwhile (I don't think I've already mentioned we're making a game!).
Hopefully this insight to the project gives you some inspiration how to approach your own solutions. Remember to not give up on your dreams: everything is possible, and in the world of AI the possibilities are endless!
Posted on April 23, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related