Colmena, an Architecture for Highly-Scalable Web Services

Lorenzo Arribas
Posted on November 6, 2018
About 3 years ago, our startup pivoted from a Q&A app for doctors to an education platform (which we named SchoolHouse.io). It was a big product shift, and we knew many technical changes would follow.
At the time, we had a 1-year-old Python+Django codebase that was already getting rusty and hard to maintain. How did we cross the legacy line so fast?
(sigh)
We were clearly doing something wrong, and we wanted to understand what, so we made a list of our main pain points:
To understand how a feature worked, we needed to jump a lot between our code and the framework's, sometimes through long inheritance hierarchies, decorators, hooks and conventions documented somewhere. Thus, every time we needed to trace a bug or make a change we needed to put on our Indiana Jones hat.
It wasn't obvious where many changes (like some permissions, relationships or validations) belonged. This generated a lot of interesting but ultimately time-wasting debates.
Unit tests were ridden with stubs and mocks, and when they weren't, they had to be busy understanding HTTP parameters or making sure the database was clean.

We ditched MVC frameworks and did it our way
Those issues made us unproductive and made our codebase messy over time.
On top of that, we suspected we wouldn't be able to solve our pain points if we kept using an MVC framework by the book, so we set out to design our own architecture1, optimized for long-term productivity and maintainability.
... So, was it worth it?
3 years later, we've seen our product change A LOT, fell in love with functional languages like Elm and Haskell, and went beyond full-stack, taking care of graphic design, frontend engineering, system administration, and data science. And despite all these changes, we believe something extraordinary has happened: We are as comfortable with our backend as the first day (no large refactors!).
Our architectural choices have consistently made our lives easier, and now we'd like to share what we've learned with the community. We've also published an implementation of the RealWorld spec to provide realistic code examples2.
OK. I'm listening. What is it about?
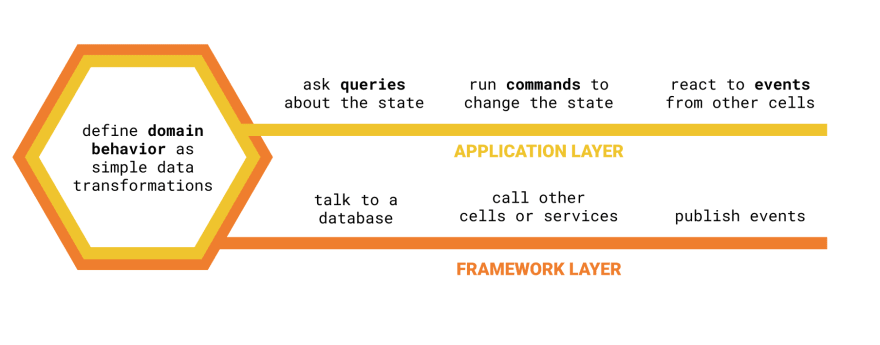
A Colmena app is composed of multiple cells.
Cells are self-contained services that follow the hexagonal architecture. Each cell:
- Has a clear purpose and responsibility.
- Has some internal domain that represents, validates and transforms the cell's state.
- Relies on a series of interfaces to receive input from (and send output to) external services and technologies.
- Exposes a public API (a contract stating what it can do).
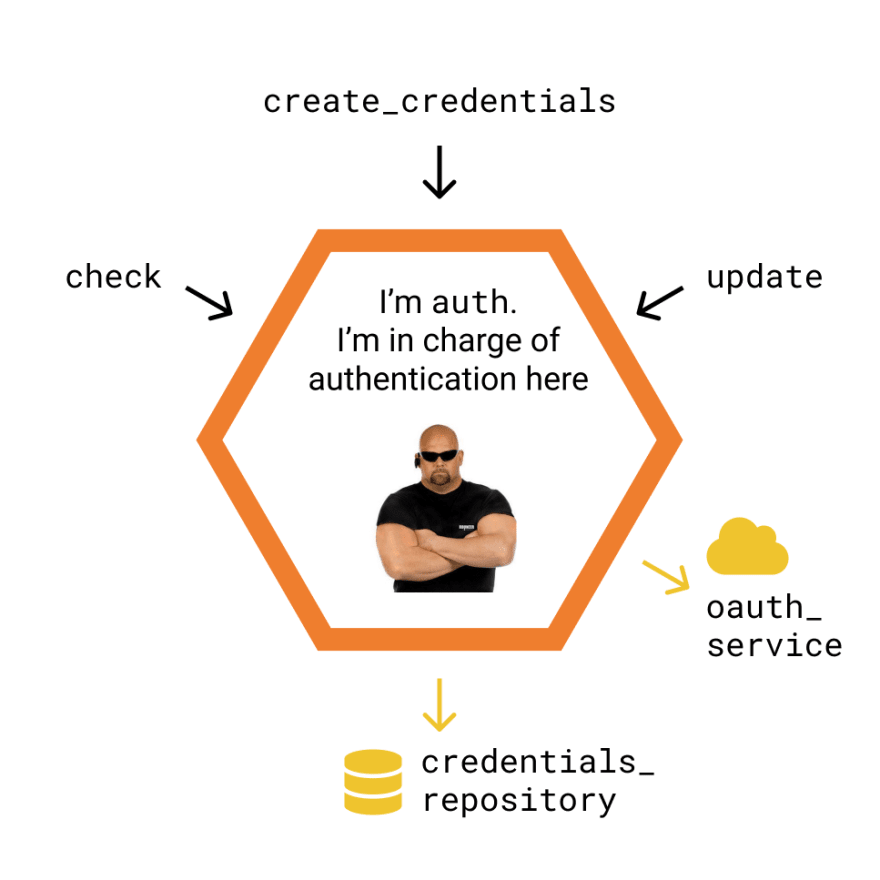
You can think of cells as very small microservices. In fact, we encourage you to try to make your cells as small as possible. In our experience, granulating your domain around entities and relationships helps you understand, test and maintain the codebase in the long run. These are the cells of the RealWorld backend:
- user
- auth
- follow (user)
- article
- tag
- comment (article)
- (article) feed
If we told you our app is a blogging platform, the purpose of each cell becomes pretty clear. It would only take a glance at the lib/real_world directory to find out where a certain feature might be defined. From there, a developer can quickly look at the API to learn about the operations it supports and navigate the implementation in a very gradual and natural way.
An event-based, functional domain
Each cell models a small domain. This domain may correspond to an entity (e.g. a user), a relationship (e.g. a user follows another), or a special feature (e.g. each user has their own materialized feed of articles).
In Colmena, changes to the domain are represented as a sequence of events. This sequence of events is append-only, as events are immutable (they are facts that have already taken place). In event sourcing, this sequence is called a "Source of truth", and it provides:
- An audit log of all the actions that have modified the domain.
- The ability for other components (in the same or different cells) to listen to certain events and react to them.
The latter practice is commonly known as event-driven or reactive programming, and it has proven a really useful way to implement certain features with very low coupling.
Moreover, since we have a sequence of immutable data, everything the domain does can be conceived as a pure function (no side effects, just deterministic data transformations). In Ruby (or any other object-oriented language for that matter), this translates to:
- No classes, class instances, or methods.
- No calls to any external technology or service.
- No need for stubs, mocks, or any other test artifacts that make our tests slow or complicated.
We can validate and describe our app's behavior in a way that is both simple and very powerful, forgetting about the noise.
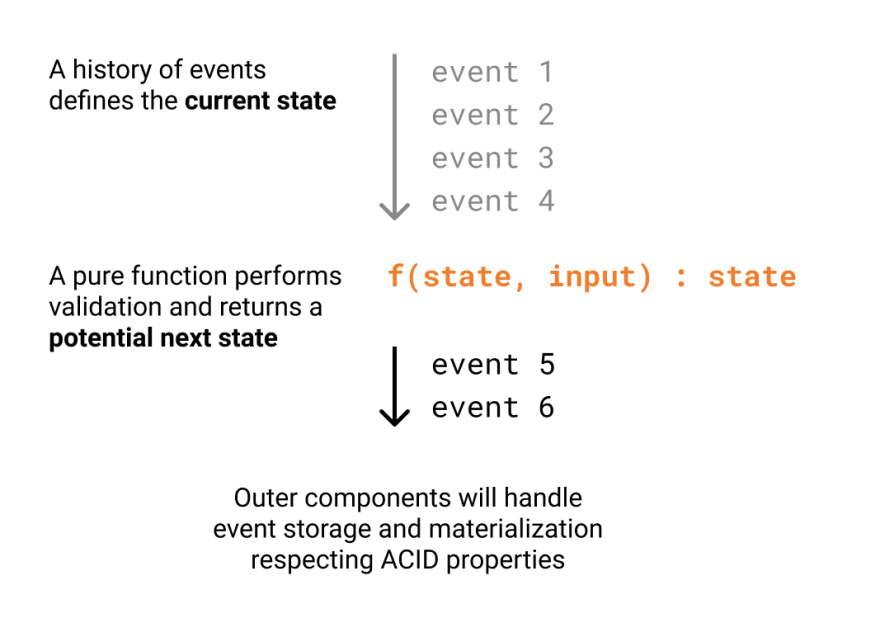
A public contract
Every useful application needs to let the world do something with it. We'll continue with our RealWorld example.
Our follow cell is there to fulfill a few use cases:
- A user follows another profile.
- A user stops following another profile.
- Someone wants to know whether a particular user follows a particular profile.
- Someone wants to know which profiles a user is following.
You'll notice the first two use cases are actions that may (if validation rules allow it) change the cell's state, whereas the last two use cases are just querying the current state.
In Colmena, we call the former commands and the latter queries, and we deal with them in a slightly different way. This pattern is called CQRS (command-query responsibility segregation). The linked article does a very good job at explaining the pros and cons of this approach, so we'll focus on our particular implementation for this RealWorld codebase:
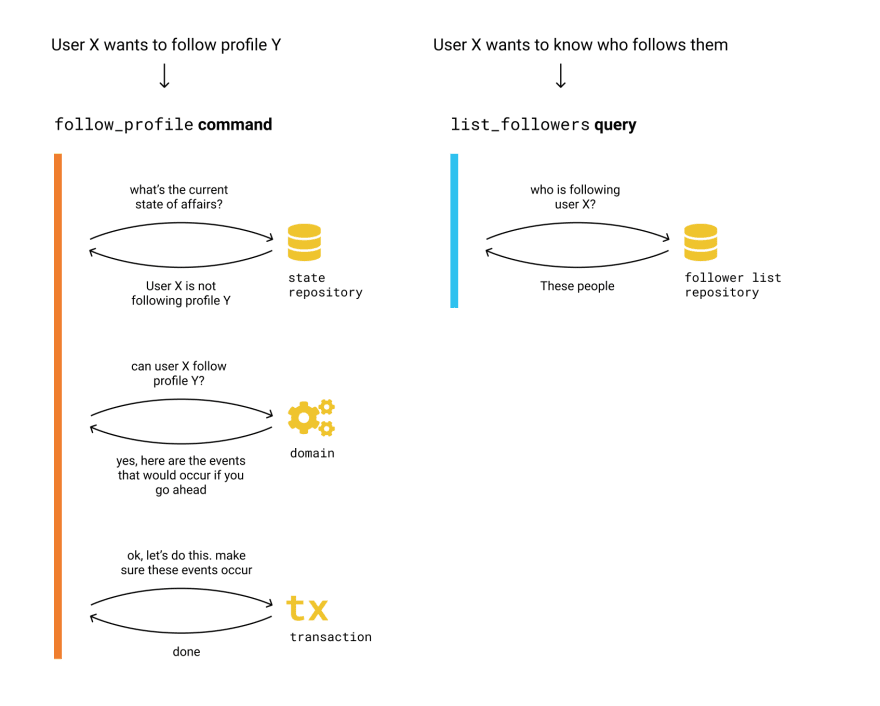
It is extremely valuable for a project to make sure the contracts for all these public-facing components are properly documented and semantically versioned. Developers need to be able to learn and trust, at any point:
- What types of events does this cell publish? What data do they contain?
- Which are the arguments to this command? How about this query?
Keep ACID properties in mind
Given that this is a distributed architecture with many components and cells working separately, it's fair to wonder... Are changes atomic? How do we keep them consistent?
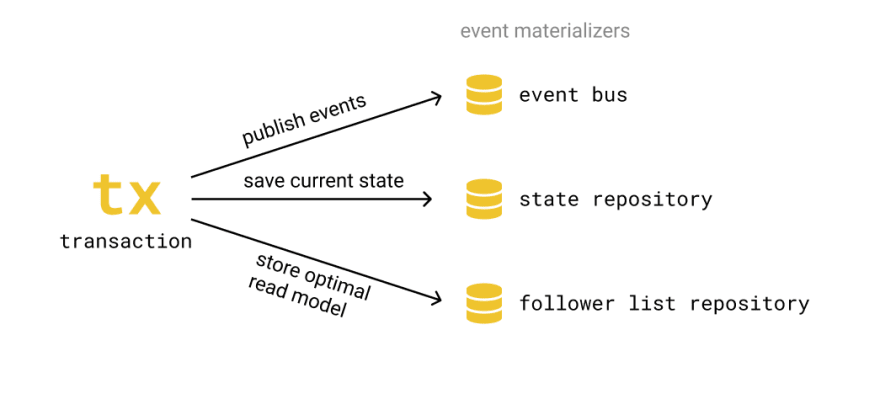
When commands need to be atomic (they usually do), they are decorated by a transaction. This transaction is responsible for publishing the sequence of events the command generates and running the proper materializers. In turn, these materializers enforce consistency and integrity. A materializer takes a sequence of events and propagates their changes to the several "read models" the queries use.
For instance, the transaction in the previous diagram might call these materializers:
Let's try with a second example as well. We're dealing with articles now. A materializer might get the following sequence of events:
article_published(...)
article_tagged(...)
And perform the following operations:
- Store the whole article in a document-oriented database (e.g. MongoDB) to optimize read operations.
- Store the article in a reverse index of
tag -> articlesto fetch articles with certain tags. - Store the article's title and description in a database optimized for search (e.g. ElasticSearch).
Some parts of this materialization process must happen synchronously (if consistency is a requirement). Others may happen asynchronously (when eventual consistency is enough).
Rely on interfaces, not concrete implementations
At this point, our cell accepts requests from a potentially untrusted source, stores and retrieves data from a database, and may need to call other cells.
These operations are the weak links of software development. The network can fail, databases can be corrupted and public APIs can't be trusted. So, what can we do to minimize these risks?
In Colmena, we define every input/output component as an interface (a port in the hexagonal jargon). A particular cell might rely on:
- A
repositoryport, which persists and reads domain data. - An
event publisherport, which allows events to be made public. - A
routerport, which communicates with other cells.
In Ruby, we specify the behavior these interfaces should satisfy with a shared example. All implementations (adapters in the hexagonal jargon) must comply with the spec if they are to be trusted, and provide explicit error handling so that risks can be gracefully handled, logged, and mitigated.
Relying on interfaces is one of the most basic design principles, and it has immediate practical benefits:
- We can write a single test for multiple components.
- We can apply the dependency inversion principle to inject the adapters we need for each environment (e.g. a fast SQLite database for testing and a fully scalable cloud database in production).3
- We can switch to a different technology without changing our cell's code.
Your application is made up of multiple cells
Cells have clearly defined boundaries, but they still need to communicate with one another. In Colmena, cells can talk to each other in two different ways:
- Synchronously, invoking a command or query on the other cell. This is a traditional remote procedure call we perform through a central service registry we call the router.
- Asynchronously, listening to events produced by the other cell and reacting to them. We do this through an event broker.
In our example app, both the router and event broker ports are implemented in-memory. The beauty of these interfaces is that they can be implemented by a service like RabbitMQ or Amazon Kinesis and connect cells deployed on different parts of the world; or even cells written in different programming languages!
Here are a few examples of how we glue cells together in this RealWorld service:
- A counter listener reacts to tags being added to or removed from an article and it updates a total count on the times a tag has been used. All the while, the
articlecell doesn't even know thetagcell exists. - The
apicell is a bit special. It exposes some of the behavior of all cells in a RESTful HTTP API. As such, it needs to deal with authentication and authorization, hiding private data and aggregating several operations into a more useful endpoint, making several sub-calls to other cells in the process. We've recently found out this pattern has its own name.
Hence, Colmena
We felt it was better to start explaining this architecture from the bottom up, so we haven't had the time to explain properly what the heck a Colmena is.
Colmena means Beehive in Spanish. Like our architecture, 🐝-hives are composed of many small hexagonal units that are isolated from one another but work together as a powerful system. Isn't that beautiful?
Hence, the name.

In this article, we've presented an overview of the Colmena architecture and the reasons that brought us to use it in the first place.
In the next ones, we'll zoom into some of the main features and provide more details and code examples.
-
By what we mean, do a lot of research and combine the ideas we liked the most with our own use cases ↩
-
The example app is written in Ruby, but we've applied the same ideas to codebases in Go and Haskell, with the same effects. ↩
-
Just remember to test every adapter before releasing to production, not just the ones you use for your development environment. ↩
Posted on November 6, 2018
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.