
Sergio Ocón-Cárdenas
Posted on November 24, 2022

Advance Git — Git to Work with GitOps
Soon after you master the basics of Git — creating a repository, committing changes, pushing to remotes, and creating pull requests — you’re bound to quickly run into situations where you need to run more than git add . and git push origin main.
At the same time, if you jump straight into the reference documentation, you’ll quickly find yourself lost in every complex nook and cranny of Git, like stashing, cherry-picking patches, adding submodules, and more. Those things are useful but are not really needed on a day to day basis.
This piece is for every developer and DevOps admin who’s in-between. You’re certainly not a beginner, but not an expert (yet) either, and you just want to master new problems and streamline the processes you’ve already embarked on. And we’ll get you exactly the information you need to be even more productive and elaborate with your version control tactics without sacrificing your development velocity.
Merge (or rebase!) your code
The standard way of working on features, specially when more than one developer collaborates, is to create a new branch in Git with the intention of merging your code back into your primary development branch, which, these days, is most often called main. There are many strategies for this (from git flows to truck based development) that we won’t be covering here.
If everything goes to plan on your new branch, the process looks something like this:
Make changes to your code
Stage your changes with git add
Commit your changes
Push your changes to your remote
Merge your new branch withmainand repeat the cycle
But you need to be prepared when things don’t go to plan.
Amend
Let’s say you just hit Enter on your most recent commit and realized you did something wrong. You can change your last commit by replacing it with a new commit, which also creates a new commit hash, or ref. that substitutes the previous one.
You can use it to update your commit message:
git commit --amend -m "Your updated commit message"
Or, if you forgot to stage a file:
git add your-file.txt
git commit --amend --no-edit
As this changes history, it is bad practice to do it if you have pushed your changes into a remote server, as other people can be working on a different version of the history. You will have to –force your new history to push it to a remote server.
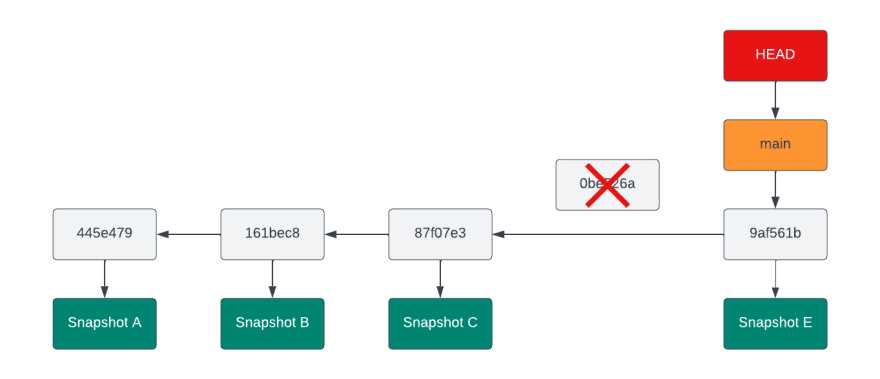
Unstage
If you already staged a file using git add, Git doesn’t force you to commit it. When you are sharing your history with other people, sometimes it can be useful to make your history reflect the way you work, and commit the files in different commits instead of in one big step. What happens when you commit a file that you want to add to your history to a later stage? Well, you can unstage these files, which prevents them from being committed, but retains the changes you’ve already made.
If you have a single file you want to unstage, use git restore:
git restore --staged <your-file>
Alternatively, you can unstage all your changes with a single command and get back to the original content before your changes:
`git reset <your-file>`
Unmodify
If you’ve modified a file but haven’t yet staged or committed it, you can use the same technique:
`git reset <your-file>`
Merge
If you’re using a platform like GitHub for code collaboration, you probably won’t be doing much manual merging of branches, but it’s still an important process you should be familiar with.
It’s also important to recognize that, behind the scenes, Git merges your code every time you run git pull to incorporate changes from your remote.
Let’s run through the most common example of manual merges: Combining the work you’ve completed on two local branches before you push to your remote and engage in any code collaboration via GitHub or another platform. You currently have your main branch checked out and want to merge in your changes from new-feature.

git merge new-feature
Git will replay the commits you made on the new-feature branch on top of what’s changed in the main branch, creating one more commit that combines the latest state.

If there are conflicts, you’ll have to deal with them manually.
Rebase
When you merge branches, you write new commits into your repository’s historical record and move on from there, as you see in commit Z from the diagram above. A rebase solves the same problem as a merge — you integrate changes from one branch into another — but when you rebase, it’s more like *rewriting and cleaning up *history.
You’re most likely to rebase when you’ve worked in a development branch for a while, but your main branch has also progressed in parallel. You want to include these new changes into your branch—perhaps you could benefit from a recently-merged bugfix or UI improvement—but you don’t want to create a new and possibly messy merge commit. Instead, rebasing allows you to replay your changes on top of the latest state of main, integrating not only their code, but also their histories.
Let’s assume your Git history looks like this:

From your new-feature branch, you run the following on the branch new-feature:
`git rebase main`
Your Git history ends up looking like this:
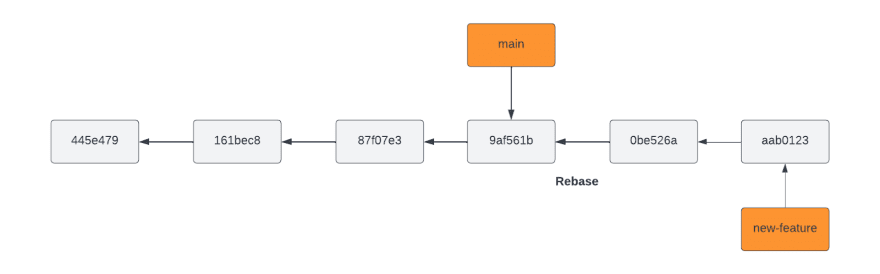
From Git’s perspective, you’ve now changed the beginning of your branch from commit T to commit V, allowing you to continue developing from the most up-to-date history. The two big benefits of rebasing is that your branch’s history is cleaner, as though you started working from the latest main from the get-go, and you get a cleaner merge when you’re ready to integrate the branches.
Now a git merge will consist of a fast forward of main to the latest commit.
Resolve conflicts
Whether you’re merging or rebasing, you’ll encounter situations where Git’s merging algorithm can’t reliably handle without potentially breaking your code. You need to resolve these conflicts, telling Git which version of your code is more up-to-date or “correct” before you can push to your remote.
Git informs you of the conflicting file(s), at which point you need to open them, find the line(s) of code that are affected, delete the outdated code, and retain the version that’s more up-to-date or “correct.” Once you’ve resolved a conflict, you can save the file(s), stage with git add, and then continue the process with one of the two commands:
`git merge --continue`
`git rebase --continue`
You may have to resolve conflicts multiple times — particularly when rebasing — but keep cycling through the process until you’ve fully integrated your branches!
Find branches that have been merged with the current
After you’ve been developing for a while, creating many new branches and eventually merging them into main, you’ll inevitably start to clutter up your repository with obsolete or outdated branches. When you run git branch, or attempt to use your terminal’s autocomplete feature to checkout a branch, it inundates you with irrelevant options.
` example-101
exciting-new-feature
* main
refactor
strange-bug
strange-bug-2
…`
Because your local branches might contain code you want to keep and merge later, you don’t want to start deleting branches without taking some precautionary steps first.
If you want to see which branches you’ve merged into the latest commit on main:
`git branch --merged main`
Once you know your code is safely inmain, you can delete branches with git branch -d <branch-name>.
Tag important points in your Git history
Now that you’re developing, committing, merging, and rebasing with more confidence, with the knowledge to circumvent any mistakes you might make, you’re getting to the point where you should start to create more organization around your project’s history.
Git might be a version control system, but it doesn’t automatically create the kind of versions we’re more used to seeing, downloading, and interacting with — think milestones like v1.0, v4.0.8, v183.22.8, and more. These version numbers, whether you follow the semantic versioning scheme or any other, help you, collaborators, and end users understand the state of the software they’re creating or using.
Note: Git tags aren’t limited to version numbers alone — you can tag a commit with any string you’d like.
We recommend creating an annotated tag to include metadata, like your Git username, email, date, and a short message. To create a tag based on the current HEAD:
`git tag -a v1.2.0`
Once you’ve created one or more tags, you can list them with git tag.
Another important note is that tags aren’t pushed to your remotes by default, which means you need to do so explicitly:
`git push origin v1.2.0`
The benefit of pushing your tags to your remote is that others can check them out explicitly without having to know a specific ref:
`git checkout v1.2.0`
Fix errors by rolling back history
Sometimes, despite your best intentions, you let errors or bugs make their way into the current commit of yourmain branch. And sometimes, you can’t afford to spend time with a formal process of troubleshooting, fixing, testing, and deploying a bugfix branch—for example, if you use CI/CD to deploy the latest commit to production automatically.
In these cases, your best bet might be to roll back the state of your repository to a previous commit you know works.
Finding a previous commit
First, you need to find the old commit. Either of the following commands will display your repository’s commit history, all the way back to its origin, along with the associated commit message. The first command also displays the author, date, and refs involved in a merge, if applicable. The second command displays only the ref and the commit message, allowing you to traverse history a little faster.
`git log`
`git log --oneline`
Once you find the previous commit, take note of its ref, whether the shortened or long version.
Rolling back to your chosen commit
Before we talk about *how *to do this, it’s important to clarify some of Git’s terminology around these processes, as they’re quite important:
A reset is like going back in time to a specific commit, effectively undoing and removing all the commits between the two and altering the project’s commit history.
A revert is pulling out a specific commit and leaving a revert commit in its place, then continuing development from there.
In the following diagram, you remove commit D and C, rolling back the history to commit B, and then continue your development with E. With a reset, the history is rewritten, while revert will create a new commit that modifies the changes so that the new commit is the same as B (but a new one)
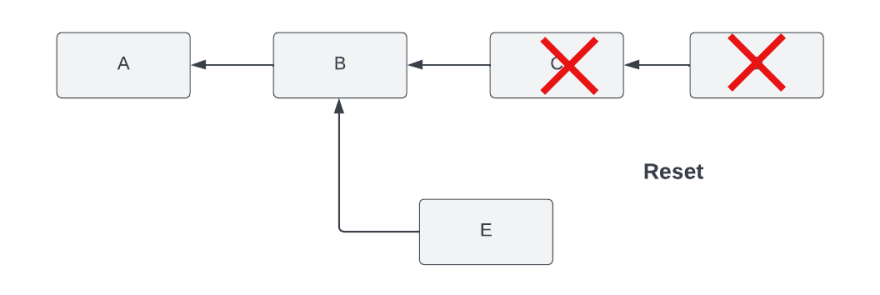

Based on how you want to handle your commit history, and whether you need to preserve the work you completed in those intermediate commits in the process, you can take one of two actions:
Reset:
`git reset --hard B`
Revert:
git revert B
As we said before, reset is a dangerous command if you have shared your code with others, because it will create inconsistencies between copies of the code, as the histories will be different.
Code collaboration on GitHub
GitHub might not be the only place where code collaboration happens, but it’s the most popular platform to do so. Most open source projects host their projects and work with contributors there. GitHub adds some flows to these basic git flows, so it’s important to know where Git’s features end and GitHub’s begin.
Fork a repository
Forking has a long history in open source, but in the context of GitHub, it refers to the process of duplicating a repository under your GitHub account. For example, you find a project at github.com/sandra/projectA, but then create a duplicate at github.com/your-username/projectA. They share the same project name, but they’re managed and maintained by different people—the original creator, and yourself. You are the owner of your copy, so you can modify it and maintain it in the way that you want.
Forking is necessary when you don’t have write access to the original repository and its remotes and branches, which is almost always the case when collaborating on an open source project. Even when working on an internal project, such as refining the Kubernetes manifests your team uses to deploy your application to production, you might be required to work with a fork of the repository rather than writing directly, so you can do some checks and follow some procedures before committing new code.
Pull requests and merges
On GitHub, code collaboration occurs primarily through pull requests, which are your way of informing others about the work you’ve completed and asking them to review and merge your code. Pull requests are completely asynchronous, which is a boom for organizations who work remotely and across multiple time zones and blocks of working hours. When you open a pull request on GitHub, your peers and collaborators can comment on your work, review it, make suggestions and comments. Eventually, your code will be ready and somebody will approve your request, and your changes will be merged into your destination branch — most often, that’s going to be main, although there are different strategies for branch management.
Aside from creating an asynchronous conversation around your proposed changes, pull requests also act as an important check on code quality. Your organization likely requires one or more approvals from your peers to merge any of your pull requests, preventing any developer or engineer from unilaterally merging code.
Pull requests also trigger CI/CD pipelines, which can trigger even more robust quality checks — we’ll cover those in a moment.
One important part of the Pull Request process is the code review. We will see later how you can add automation to the workflow, introducing compliance tests that show information about the code, so the review process can be done easier and quicker (i.e. giving you information about whether the commit will still pass the integration tests, or more).
GitHub Actions
Continuous integration and continuous delivery (CI/CD) pipelines have been around for a long time, but mostly as third-party platforms. GitHub now offers its own CI/CD pipeline, GitHub Actions, which lets you define how you build, test, and deploy your code.
You first define, in your repository, which events — pushes, new issues, pull requests, and more — should trigger CI/CD pipelines, and what actions you want GitHub to take on your behalf. You can automatically test your code for compliance with style, security, or testing requirements, which we’ll cover in the next section.
Making your code compliant
Stylize your code with a linter
A linter is a static analysis tool for improving the quality of your code by fixing errors, pointing out stylistic mistakes, or warning you about suspicious patterns. There are linters for every major programming language and tools that care more about code formatting, like Prettier. These tools look for configuration files, which you store directly in your repository to apply standards across your codebase. Having a well defined linter means that your lines of code are written in the same style as others, making the code easier to understand and review. It is like your automatic coding style guide, and it is so useful for collaboration that modern languages include their own code formatter and linter (like rust, elixir or go)
While some of these tools can run directly in your IDE/code editor, creating flags and warnings as you write your code, another powerful way to stylize and correct your code is with a Git pre-commit hook: Every time you run git commit ..., Git runs your tool (linter or formatter) of choice, and stops the commit if that tool returns any errors or warnings, like a failed revision of your PR. It outputs some helpful information about the violation, along with the filename and line number to help you resolve it quickly.
Run tests automatically
Continuous integration (CI) is an automated process that builds and tests the code you’ve just committed to prevent bugs and errors from being merged into your main branch. The more often you commit, the more often these tests run, encouraging and enforcing higher quality while keeping your velocity high.
CI tests can include the linters mentioned above and code coverage, which reveals what percentage of coude you’re currently testing vs. how much you will test if you merge your branch into main. You can’t use CI directly with Git, but code collaboration platforms like GitHub make it trivial with GitHub Actions. You can also opt for an independent CI/CD platform, like Jenkins, CircleCI, ArgoCD, or dozens of others.
In many cases, you can define your CI practices directly in your repository and keep them version-controlled alongside the rest of your project, smoothing your onramp into more sophisticated DevOps practices, like GitOps.
Integrate security into your workflow
Linters and code coverage tests help ensure the quality of your code, but they can’t prevent you from deploying inherently insecure code. That’s where security-focused CI/CD pipelines come into play, giving you the power to automatically:
Scan your source code for potential vulnerabilities (static application security testing)
Discover which dependencies introduce major security flaws (source composition attacks)
Verify that all user inputs are not vulnerable to injection attacks
Ensure no secrets, like passwords or keys, are publicly visible
Tighten access controls on changes to your production infrastructure as code (IaC)
Dependency management
The application you’re building in your Git repository inevitably requires dependencies — open source projects, tools, and protocols — to function correctly. Every framework and language defines and stores dependencies differently, but most can be saved and version-controlled in Git.
Take, for example, managing dependencies in NodeJS. You create apackage.json file, which defines which packages you need to build and run your application. NodeJS/NPM then creates a package-lock.json/yarn.lock file, which defines your dependencies' dependencies, and stores the packages themselves in the node_modules/ folder. Once you tell Git to ignore that folder by adding it to `.gitignore, you can manage dependencies directly in your repository,
Conclusion
This piece on advanced Git techniques might seem like a lot if you are new to Git, but we have left a few ones behind that you will be using only in very limited situations. However, it is more and more clear that Git is the right choice to store the history of your application and infrastructure configuration to achieve full auditability and automation. Stay tuned for even more workflows and optimizations that come with a deep understanding of all things Git!
And in the meantime, we encourage you to check out Monokle, a desktop application that helps DevOps engineers and developers better leverage Git when managing and optimizing their Kubernetes deployments adding a lot of fundamental features to analyze and create your optimal desired state.
We’re fully open-source and would love to hear about your Git, DevOps, and GitOps journeys on Discord!
Originally published at https://monokle.io.
Posted on November 24, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
November 29, 2024
November 28, 2024

November 28, 2024
