One real game backend overview

Konstantin Usachev
Posted on October 3, 2022
A few weeks ago, I announced a post with an overview of some real game backend, and here it is. Unfortunately, I don't work for this developer anymore, so I can't name the game. In general, it is an online-session-based FPS game. And to recall, by "game backend", I assume it is a part of the server code that handles everything the player does when they are not in the battle.
Tech stack
- C++ for the server and client
- MySQL database
- Node.js/Vue for the administrative interface
- ELK for logs
- ClickHouse/Graphite/Grafana for metrics
- Hadoop/Hive/Impala/HUE for analytics
Architecture
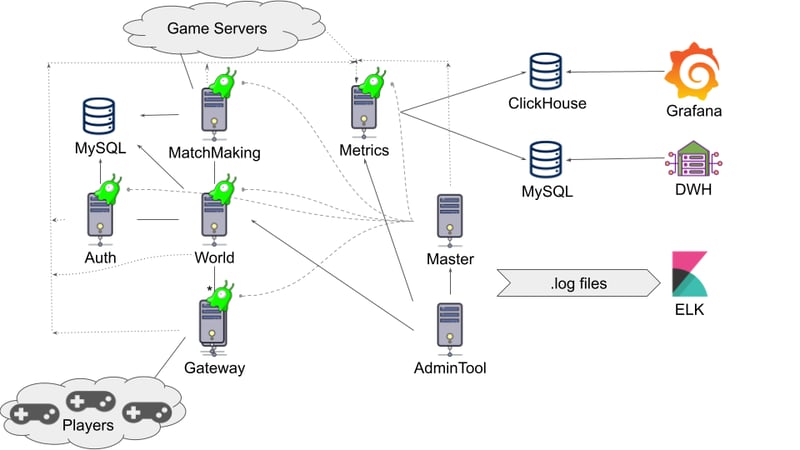
There are several backend nodes:
Auth server
- It is the first server client connects to
- It handles client authorization through one of the external authorization services (like Steam)
- It handles new player creation and EULA acceptance
- It sends back to the client the current least-busy Gateway to connect to
Gateway server
- It is the only server that supports horizontal scaling in this backend
- All game clients keep a TCP connection to one of the Gateway servers
- Only Auth and Gateway servers have publicly available addresses.
- The Gateway server handles all client pings, and it is more than 90% of the clients' requests
- It handles "global" chat, which is a chat per Gateway
- It protects from spam messages
- It keeps outcome message buffers for each client. It is something like 1 MB per connection, allowing for the distribution of some RAM consumption.
World server
- It is the Monolith of this backend
- It handles most parts of the game logic
- It keeps in the RAM caches of all online players
- It is the main performance bottleneck
- It is the main crash bottleneck because, when it crashes, it takes some time to write more than 100 GB crash dump file with the current memory state
MatchMaking server
- It handles matchmaking (i.e. requests to enter a battle and distributes players in teams)
- It requests and manages new game server launches to send players to.
- It handles match results
Master server
- It is a custom-made server management system
- It provides configuration to other nodes
- It has information about each server load through special processes on each server called Commander (Brain Slugs in the picture)
- It can send commands to Commanders to launch new processes
- It handles MatchMaking server's requests to launch a new game server and has information about global game servers' current load and capacity
- It provides some administrative API to do some cluster-related manipulations (stop/launch another Gateway server, for example)
AdminTool server
- Administrative Web UI and Websocket API to execute administrative actions (like check player profile, ban player, give the player something and so on)
- Allows through Websocket API to integrate with custom operator's tools to automate some actions (give everybody a loot box, or give something to a player because he purchased it on the game's webshop)
Metrics server
- It handles all metrics and analytics messages for other nodes
- It supports some primitive UI to access recent metrics (for development purposes mostly)
- It sends metrics to Clickhouse through carbon-clickhouse. There are ~10k metrics for backend nodes only without game servers
- It sends analytics events to MySQL where it gets replicated to an analytics MySQL instance and by daily job gets moved to Hadoop cluster
It is a bird's-eye view of the cluster's components. Each node is a process which can be launched on a separate physical or virtual server. However, most utilize very few threads and don't have any high load, so, in production, they fit on three physical servers.
Let's take a look inside a single server:
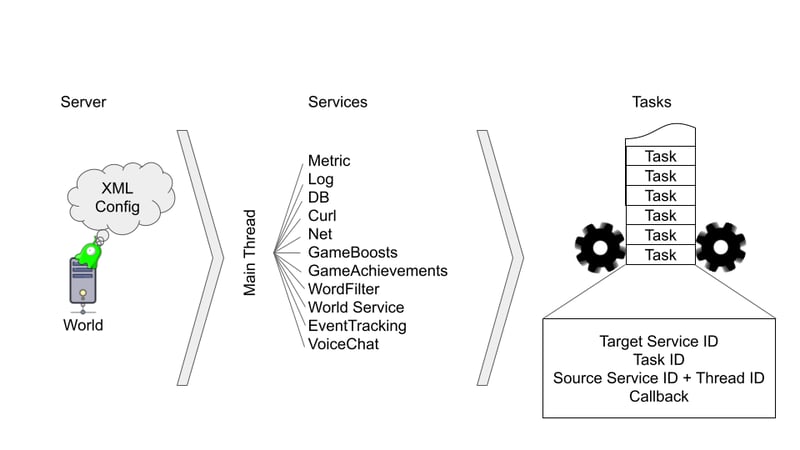
Every server contains a bunch of services. At the start, the main thread parses this node's XML config and creates services. The config is provided by the master server through the local commander. Each service launches one or more threads for its work. In this picture, you can see some examples of such services.
Services communicate with each other asynchronously through tasks. Essentially, every service is a conveyor that handles tasks specific to them. Every task is a data-only struct with the following information:
- The service the task should be handled by
- The task ID, so it can be cast properly
- Information about the service and thread where this task was created
- A pointer to a callback function for when the task is executed—this gets called from inside the thread it was created
- Specifics of the task information required to execute it properly and to store execution results
Every service adds some boilerplate code to hide this internal complexity and for more convenient usage.
Cluster configuration
The whole cluster configuration lives in two XML files.
- The primary XML file has sections for each node configuration and a long list of defined variables to reuse some values in different config parts and override them in the second XML config. This file is provided with a new server code version and is not supposed to be modified locally.
- The secondary XML config is the list of overrides for variables specific to the current environment, like local dev cluster, test stand or production. It is a part of the current environment and can be modified locally or through the AdminTool.
When the master server starts, it combines these two files into a single XML document and sends it to each node. Also, the master server observes config modification and sends updated sections when changes in the XML document happen. Therefore, the modification of some server settings, such as switching a feature on or matchmaking configuration modification, is essentially just a modification of this XML file on a server with this cluster's master server process launched.
Network communication
Here, no special framework for network communication, and even serialization is used. As described before, each player has a TCP connection to one of the Gateway. All client-server communication is organized through serializable messages, and no PRC idiom is used. The Gateway server handles some message types, but most go farther to the World server.
Each serializable object is inherited from a special class and implements Write and Read methods to serialize its data to a stream and deserialize it.
Player state management
When the player logs in to the game, information related to him gets loaded on the World server and cached inside a single PlayerCache object. During this load process, some DB data might be irrelevant or incorrect. In this case, the load routine executes the required updates to fix it.
All player caches are stored inside the same process in a custom-made in-memory DB where any service can asynchronously request and lock some player's cache and release it to make it available for other services.
This approach reduces read queries to DB because you never need to read anything after the initial load. Also, it allows all the information in one place and synchronously do all the required checks before modification.
At the same time, this load consist of ~20 SQL select queries and a single cache might take up to 2 MB of RAM. So, if the cluster starts during a peak time, some system to limit players' login pace is required to handle this load.
The following is the standard workflow with a PlayerCache:
- The World server handles a message from the player to execute an action.Because almost every message from the client is a modification command, a locked PlayerCache is provided to the message handle method.
- All the checks to verify this action are performed
- Send a request to the DB service to modify the DB state
- When the DB state is modified, these changes are applied to the cache
- Send modification information to the client and release the cache
When a player connects to the server, it receives the same PlayerCache. So to keep it in sync with the server, the following approach is used:
- Every modification action we might want to do with the cache has two versions: the TryAction method and the DoAction method
- The TryAction method checks whether this action can be performed, then returns an object with all the information about this modification
- The DoAction method receives this modification object and executes the actual modification
So as described previously, on the server, we execute the Try method. If it is successful, then after the DB modification, we apply this modification to the server cache and send it to the client who also applies it. And because the server and the client are both made with C++ and can share some source code, there is no need to write these Try and Do methods twice on the server and client. Also, the client can use the Try method before sending a request to the server to check preconditions and notify the player in case of failure.
Administrative interface
There is a Node.JS-based tool called AdminTool to modify the server's config remotely and perform administrative actions. It connects to the World server and provides a WebSocket-based API. Also, it hosts a Vue-based web UI, which uses this WebSocket-based API to perform these actions. Some external tools use this API as well.
To do this, the World server provides some special API available only for the AdminTool and a special set of messages. These messages on the World server's side mostly use the same methods regular players use. And Node.JS part deserializes and serializes this message from a byte stream to a JSON. When performing some action with a player, AdminTool allows for the action and its cache's being locked on the World server, so if this player is currently online, it gets disconnected. AdminTool also provides all the required functionality to manipulate the player's state.
Analytics
Each analytics event can have up to 1 UUID field, up to 10 long fields and up to 10 double fields. In code, it is covered in a type-safe class with mapping info.
All analytics events come to MySQL in two tables:
- A table with event schemes
- A per-day partitioned table with the actual data
Of course, MySQL isn't an OLAP DB. So it only keeps the data for a few days until it moves it to the Hadoop cluster.
The scheme of both tables looks very similar:
Columns in the data table:
- int EventId
- int EventVersion
- binary Guid
- bigint Long1, Long2 … Long10
- double Double1, Double2 … Double10
Columns in the schemes table:
- varchar EventName
- int EventId
- int EventVersion
- varchar GuidName
- varchar Long1Name, Long2Name … Long10Name
- varchar Double1Name, Double2Name … Double10Name
With information from the scheme table, ETL scripts can create the required Hive Views for convenient data representation and query data through HUE using friendly names. This process never involves the modification of the MySQL table schemes to add new events.
When there is more data to send than fits into a single event, you can always create another event with the rest of the data. When you change the event's scheme, you should increase its version so that a new row will be added to the scheme table and the Hive View be updated.
This approach looks a bit complicated, but it worked well with ~200 mln events a day.
This was just an overview of one existing game backend. Of course, it has some pros and cons, but it was able to handle 70k CCU peaks, and this game is still actively supported.
I believe that you can select any tech stack or architecture and use any approach to build your product. The only difference is in the cost and effort required to make it and support it later.
Posted on October 3, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.