Whatsapp chat analyzer web app with Python and Symbl.ai in < 100 lines of code!

Kacha
Posted on March 24, 2022

Creating a Whatsapp Chat analyser web app with Symbl.ai and python in less than 100 lines of code
This application will take an .txt export of a Whatsapp chat. The application will then run conversational analysis on the .txt file. Symbl.ai will then extract information like follow ups, topics and action items.
The application requires the following libraries:
- streamlit: This library converts python scripts into web applications.
- symbl.ai: This is a conversational A.I library that can get insights from audio and text.
Starting the Streamlit app
Streamlit is a great library I found that can convert python scripts into a web application.
Lets create an application that will accept a whatsapp txt chat file and parse the chat data.
import streamlit as st
chat_file = st.file_uploader("Select chat file")
if chat_file:
conversation_request = handle_uploaded_file(chat_file)
To handle the file and extract the messages in a format that symbl will understand we need to create a function to do it.
def handle_uploaded_file(file):
chat = file.read().decode("utf-8")
# Split each line from the file into a list and strip all whitespace
lines = chat.splitlines()
lines = [line.strip() for line in lines]
messages = []
cleaned_lines = []
# If line does not start with a Whatsapp date format [m/d/y, h:m:s am] then append it to the previous line.
for x in range(len(lines)):
if lines[x].find("[") == -1:
cleaned_lines[-1] = f"{cleaned_lines[-1]} {lines[x]}"
continue
cleaned_lines.append(lines[x])
# pares the time, name and message from a line
for line in cleaned_lines:
st_dt, en_dt = line.find("["), line.find("]")
time = line[st_dt:en_dt].replace("[", "")
name = line[en_dt:].split(":")[0].replace("]", "")
st_m = line[en_dt:].find(":")
message = line[en_dt:][st_m:].replace(":", "")
# Create messages in the format Symbl requires
messages.append(
{
"duration": {"startTime": arrow.get(time, 'M/D/YY, H:mm:ss A').format(), "endTime": arrow.get(time, 'M/D/YY, H:mm:ss A').format()},
"payload": {"content": message, "contentType": "text/plain"},
"from": {"name": name, "userId": name},
}
)
return {
"name": "Chat",
"confidenceThreshold": 0.6,
"detectPhrases": True,
"messages": messages,
}
Once we have the messages from the handle request file we can analyse it with Symbl.ai
import symbl
...
conversation_object = symbl.Text.process(payload=conversation_request)
Displaying the results
Add some display components using streamlit.
with st.expander("Topics"):
with st.spinner("Getting topics"):
topics = symbl.Conversations.get_topics(conversation_id=conversation_id)
for topic in topics.topics:
st.write(f"- {topic.text}")
with st.expander("Action Points"):
with st.spinner("Getting action items"):
action_items = symbl.Conversations.get_action_items(conversation_id=conversation_id)
for item in action_items.action_items:
st.write(f"- {item.text}")
with st.expander("Questions"):
questions = symbl.Conversations.get_questions(conversation_id=conversation_id)
for question in questions.questions:
st.write(f"- {question.text}")
with st.expander("Follow ups"):
follow_ups = symbl.Conversations.get_follow_ups(conversation_id=conversation_id)
for follow_up in follow_ups.follow_ups:
st.write(f"- {follow_up.text}")
The final code file
import streamlit as st
import arrow
import symbl
def handle_uploaded_file(file):
chat = file.read().decode("utf-8")
lines = chat.splitlines()
lines = [l.strip() for l in lines]
messages = []
cleaned_lines = []
for x in range(len(lines)):
if lines[x].find("[") == -1:
cleaned_lines[-1] = f"{cleaned_lines[-1]} {lines[x]}"
continue
cleaned_lines.append(lines[x])
for line in cleaned_lines:
st_dt, en_dt = line.find("["), line.find("]")
time = line[st_dt:en_dt].replace("[", "")
name = line[en_dt:].split(":")[0].replace("]", "")
st_m = line[en_dt:].find(":")
message = line[en_dt:][st_m:].replace(":", "")
messages.append(
{
"duration": {"startTime": arrow.get(time, 'M/D/YY, H:mm:ss A').format(), "endTime": arrow.get(time, 'M/D/YY, H:mm:ss A').format()},
"payload": {"content": message, "contentType": "text/plain"},
"from": {"name": name, "userId": name},
}
)
return {
"name": "Chat",
"confidenceThreshold": 0.6,
"detectPhrases": True,
"messages": messages,
}
chat_file = st.file_uploader("Select chat file")
if chat_file:
conversation_request = handle_uploaded_file(chat_file)
with st.spinner("Analysing Text"):
conversation_object = symbl.Text.process(payload=conversation_request)
conversation_id = conversation_object.get_conversation_id()
st.write(conversation_id)
with st.expander("Topics"):
with st.spinner("Getting topics"):
topics = symbl.Conversations.get_topics(conversation_id=conversation_id)
for topic in topics.topics:
st.write(f"- {topic.text}")
with st.expander("Action Points"):
with st.spinner("Getting action items"):
action_items = symbl.Conversations.get_action_items(conversation_id=conversation_id)
for item in action_items.action_items:
st.write(f"- {item.text}")
with st.expander("Questions"):
questions = symbl.Conversations.get_questions(conversation_id=conversation_id)
for question in questions.questions:
st.write(f"- {question.text}")
with st.expander("Follow ups"):
follow_ups = symbl.Conversations.get_follow_ups(conversation_id=conversation_id)
for follow_up in follow_ups.follow_ups:
st.write(f"- {follow_up.text}")
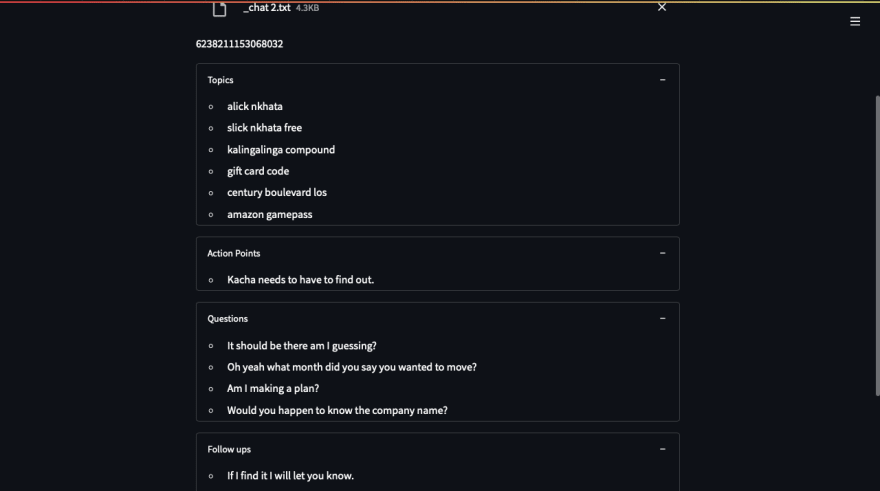
Screenshots of our final application


Posted on March 24, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
March 24, 2022