Getting started building with Fauna and Java using Spring Boot

Divine Odazie
Posted on July 2, 2021

Written in connection with the Write With Fauna program.
“Software is eating the world” - Marc Andreessen. The need for more software brought about cloud-native application development to speed up the building and updating of software while improving quality and reducing risk. Cloud-native application development utilizes container technologies, microservices architecture, hybrid cloud, etc., in software development.
A cloud-native application needs a cloud-native database. Fauna, the API for modern applications, gives you access to transactional databases via a serverless data API. Fauna can perform ACID transactions, create flexible data models, run powerful document and relational queries, and graph traversals.
This tutorial will step you through the process of building a simple RESTful Todo List API. At the end of this tutorial, you will know how Fauna works, set up a Spring Boot project with Fauna, and implemented the CRUD Todo List API.
This tutorial will cover:
For reference, here's the Github repository of the finished project that you can use to follow along: https://github.com/Kikiodazie/Getting-started-with-Fauna-and-Java.
Prerequisites
- Basic understanding of RESTful API design
- Java 8 or above (This tutorial uses Java 11)
- A Java IDE - In this tutorial, we will use IntelliJ Idea, but you can use any IDE of your choice
- Postman - download it here
How Fauna works
Fauna lets you focus on your data. It reduces the operational pain of managing databases through its developer querying. Fauna gives you the data safety and reliability you need with little effort from your end.
To interact with any database, developers write queries in a query language; with Fauna, you can use Fauna Query Language (or FQL for short) to execute queries within Fauna. You can write FQL queries via the Fauna shell on your terminal or via the shell on the Fauna dashboard. In this tutorial, you will use the Fauna dashboard.
For more details on what Fauna is all about and how it works, see Fauna features.
Building an API with Fauna and Spring Boot
Set up a Spring Boot project with Fauna
You can use the Spring Initializr to set up your Spring Boot project by clicking this link, which will fill in the details of the basic configuration for you.
Click “Generate” and then import the project into an IDE. After importing the project, the directory structure should look like this:
todolist-api-with-faunadb
├── mvnw
├── mvnw.cmd
├── pom.xml
└── src
├── main
│ ├── java
│ │ └── com
│ │ └── demo
│ │ └── todolistapiwithfaunadb
│ │ └── TodolistApiWithFaunadbApplication.java
│ └── resources
│ ├── application.properties
│ ├── static
│ └── templates
└── test
└── java
└── com
└── demo
└── todolistapiwithfaunadb
└── TodolistApiWithFaunadbApplicationTests.java

To make queries to a Fauna cloud database via your Spring Boot project, you will need to add the Fauna Maven dependency into your project pom.xml. Update your project ‘s pom.xml file to have the dependency below present:
// Fauna Maven dependency
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.0.1</version>
<scope>compile</scope>
</dependency>
You can now configure FaunaClient (The Java native client for Fauna) to use throughout your project to query a cloud database.
Next, you will create a database on the Fauna dashboard, generate a server key and configure FaunaClient in the Spring Boot project.
Initializing Fauna

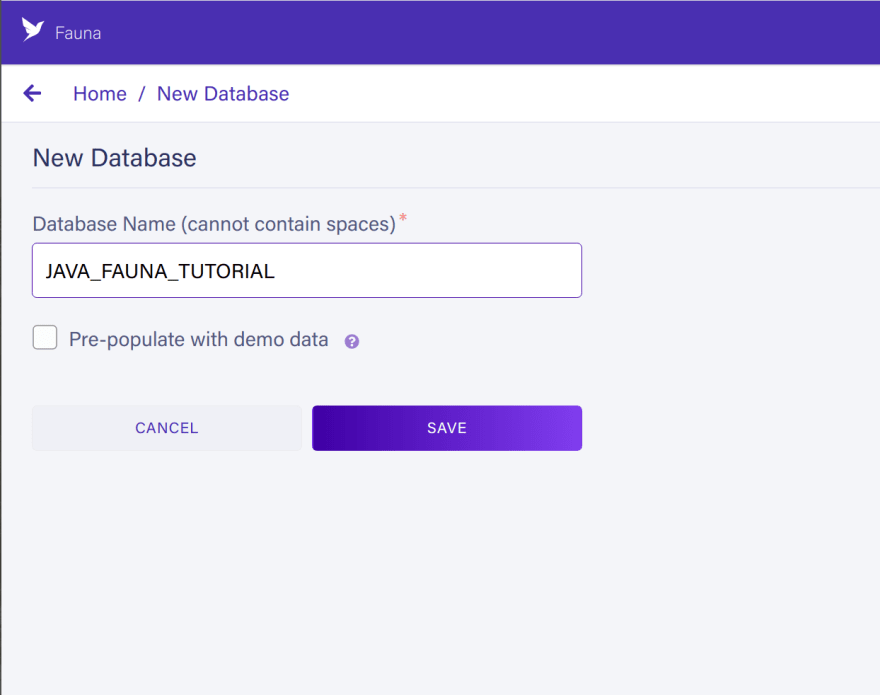
To create a database and server key for your Spring Boot project, you will need a Fauna account. If you don’t have one already, you can sign up today. After signup, create a database:
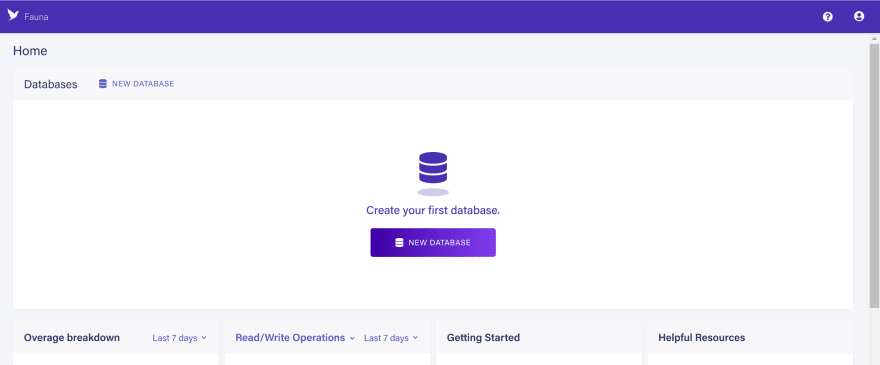
For this demo, I will name the database JAVA_FAUNA_TUTORIAL, but you can use any name you prefer:
To access your database from your code, you will need to create a server key. In your Fauna dashboard, go to the security section, and create a new key. In the settings, give it a role of Server:

After creating a key, you'll see the key's secret. The key secret won't be displayed again, so please copy and store it somewhere safe:

In your project, to configure FaunaClient in Spring Boot Java, locate the Main application class TodolistApiWithFaunadbApplication.java in src/main/java/com/demo/todolistapiwithfaunadb path which annotates with @SpringBootApplication annotation.
In your application.properties file, add environment variable fauna-db.secret to protect your secret. You will use a private variable to store your key secret for configuring FaunaClient in the Main application class.
fauna-db.secret=fnAELIH5_EACBbjxHugMSRxZ0yZxemDWU2Q-ynkE
Create a private variable serverKey:
@Value("${fauna-db.secret}")
private String serverKey;
The @Value annotation injects the value of fauna-db.secret from the application.properties into the serverKey variable field.
Now to configure FaunaClient, create a bean using the @bean method-level annotation. Next, make the bean of single scope using the @Scope annotation. The @Scope creates a single instance of the bean configuration; all requests for the bean will return the same object, which is cached.
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_SINGLETON)
public FaunaClient faunaConfiguration() {
FaunaClient faunaClient = FaunaClient.builder()
.withSecret(serverKey)
.build();
return faunaClient;
}
The instantiation of FaunaClient connects to Fauna using the serverKey provided.
Now, you can use FaunaClient anywhere in your Spring Boot project and be sure it queries to your cloud database.
To learn more about FaunaClient, check out Fauna Java documentation.
Preparing the Todo data
You’re now ready to execute your first FQL queries to create your first collection, index, document, etc. To do this, you’re going to use the shell right from the Fauna dashboard:

If you've never used FQL queries before, take a quick look at this introductory article.
To start executing CRUD queries to your database, create a collection to store the Todo documents. To create the todos collection, run this query in the shell:
CreateCollection(
{ name: "todos" }
);
The FQL query above returns JSON-like data similar to this:
{
ref: Collection("todos"),
ts: 1623105286880000,
history_days: 30,
name: "todos"
}
Next, you need to create an index to retrieve all todos from the todos collection:
CreateIndex(
{
name: "all_todos",
source: Class("todos")
}
);
So far, you’ve set up a Spring Boot project with Fauna Maven dependency, created a database and server key. Also, you’ve configured FaunaClient in your Spring Boot project and learned how to write FQL queries via the shell on the Fauna dashboard. Next, you will implement the Todo List API with Fauna and test it.
Implementing the Todo List API
The Todo List API will expose the following RESTful endpoints:
| Endpoints | Functionality |
|---|---|
| POST /todos | Create a new todo |
| GET /todos/{id} | Get a todo |
| PUT /todos/{id} | Update a todo |
| DELETE /todos/{id} | Delete a todo |
| GET /todos | List all todos |
Now, structure your project into different layers. For this demo, you can use this structure:
├── src
├── main
├── java
└── com
└── demo
└── todolistapiwithfaunadb
├── data
│ ├── dataModel
├── persistence
├── rest
├── service
└── TodolistApiWithFaunadbApplication.java
The above packages:
- Data layer for defining entities and other data model structures
- Persistence layer for your Fauna database access and manipulation
- Service layer for the API business logic, and
- Rest (web) layer for your REST controllers

In implementing the Todo List API, we are going to implement each layer in the following order
Data layer → Persistence layer → Service layer → Rest (web) layer
Data layer
To start, create the data models for the Todo List API.
In src/main/java/com/demo/todolistapiwithfaunadb/data/dataModel directory path create an abstract Entity class:
package com.demo.todolistapiwithfaunadb.data.dataModel;
public abstract class Entity {
protected String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
- This class will serve as a base class for implementing domain entities
- Entity (Todo) data persisted(saved) to the database is defined by its unique identity
For the /todos GET endpoint which lists all Todos in the database, breaking up the request results into multiple pages makes the request more efficient and quick. This process is called Pagination. To achieve this, create Page and PaginationOptions classes.
Still in dataModel package, Page class:
package com.demo.todolistapiwithfaunadb.data.dataModel;
import java.util.List;
import java.util.Optional;
public class Page <T> {
private List<T> data;
private Optional<String> before;
private Optional<String> after;
public Page(List<T> data, Optional<String> before, Optional<String> after) {
this.data = data;
this.before = before;
this.after = after;
}
public List<T> getData() {
return data;
}
public void setData(List<T> data) {
this.data = data;
}
public Optional<String> getBefore() {
return before;
}
public void setBefore(Optional<String> before) {
this.before = before;
}
public Optional<String> getAfter() {
return after;
}
public void setAfter(Optional<String> after) {
this.after = after;
}
}
The Page class creates a new Page with the following given parameters:
- Data: The
dataparameter lists the data of the current page sequence. - Before: The
beforeoptional parameter serves as a cursor that contains the Id of the previous record before the current sequence of data. - After: The
afteroptional parameter serves as a cursor that contains the Id of the next record after the current sequence of data.
PaginationOptions class:
package com.demo.todolistapiwithfaunadb.data.dataModel;
import java.util.Optional;
public class PaginationOptions {
private Optional<Integer> size;
private Optional<String> before;
private Optional<String> after;
public PaginationOptions(Optional<Integer> size, Optional<String> before, Optional<String> after) {
this.size = size;
this.before = before;
this.after = after;
}
public Optional<Integer> getSize() {
return size;
}
public void setSize(Optional<Integer> size) {
this.size = size;
}
public Optional<String> getBefore() {
return before;
}
public void setBefore(Optional<String> before) {
this.before = before;
}
public Optional<String> getAfter() {
return after;
}
public void setAfter(Optional<String> after) {
this.after = after;
}
}
The PaginationOptions class creates a new PaginationOptions object with the following given parameters:
- Size: The
sizeparameter defines the max number of elements to return on the requested page. - Before: The
beforeoptional parameter indicates to return the previous page of results before the Id (exclusive). - After: The
afteroptional parameter indicates to return the next page of results after the Id (inclusive).
Next, in the data package, create a TodoEntity from the Entity base class, which will represent a simple Todo for the Todo List API:
package com.demo.todolistapiwithfaunadb.data;
import com.demo.todolistapiwithfaunadb.data.dataModel.Entity;
import com.faunadb.client.types.FaunaConstructor;
import com.faunadb.client.types.FaunaField;
public class TodoEntity extends Entity {
@FaunaField
private String title;
@FaunaField
private String description;
@FaunaConstructor
public TodoEntity(@FaunaField("id") String id,
@FaunaField("title") String title,
@FaunaField("description") String description) {
this.id = id;
this.title = title;
this.description = description;
}
public void setTitle(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
- The
TodoEntityfields annotate with Fauna’s @FaunaField annotation, which maps a field to an object field in FaunaDB when encoding or decoding an object. - The
@FaunaConstructorspecifies theTodoEntityconstructor to be used when decoding objects with a Decoder.
In this demo API, when a Todo saves to your database, Fauna generates a unique Identifier using NewId() function, which creates a unique number across the entire Fauna cluster. Due to that, you will need to create a replica of the TodoEntity containing all necessary data except Id, which will be used for POST (Creating) and PUT (Updating) requests.
In data package, create a CreateOrUpdateTodoData class:
package com.demo.todolistapiwithfaunadb.data;
public class CreateOrUpdateTodoData {
private String title;
private String description;
public CreateOrUpdateTodoData(String title, String description) {
this.title = title;
this.description = description;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
Next, you will be implementing the Persistence layer of your API.
Persistence layer
The persistence layer is also known as the repository layer. In this layer, you will implement the FaunaRepository class, which will serve as the base repository for entity repositories.
The FaunaRepository class will implement Repository and IdentityFactory interfaces.
In the persistence layer, create a Repository interface. This interface defines the base trait for implementing all other repositories and sets base methods for mimicking a collection API:
package com.odazie.faunadataapiandjava.persistence;
import com.odazie.faunadataapiandjava.data.model.Entity;
import com.odazie.faunadataapiandjava.data.model.Page;
import com.odazie.faunadataapiandjava.data.model.PaginationOptions;
import java.util.Optional;
import java.util.concurrent.CompletableFuture;
public interface Repository<T extends Entity> {
// This method saves the given Entity into the Repository.
CompletableFuture<T> save(T entity);
// This method finds an Entity for the given Id
CompletableFuture<Optional<T>> find(String id);
// This method retrieves a Page of TodoEntity entities for the given PaginationOptions
CompletableFuture<Page<T>> findAll(PaginationOptions po);
// This method finds the Entity for the given Id and removes it. If no Entity can be found for the given Id an empty result is returned.
CompletableFuture<Optional<T>> remove(String id);
}
-
*<*T extends Entity*>*says that the expectedTcan contain class objects representing any class that implements theEntitybase class. - The above methods are of type CompletableFuture, used in asynchronous programming. You use
CompletableFutureas Fauna’s FQL queries execute concurrently.
Next, to support early Identity (Id) generation and assignment before a Todo entity saves to the database, create the IdentityFactory interface:
package com.demo.todolistapiwithfaunadb.persistence;
import java.util.concurrent.CompletableFuture;
public interface IdentityFactory {
CompletableFuture<String> nextId();
}
Now, you will implement the FaunaRepository class. Still, in the persistence package, create the FaunaRepository class:
package com.demo.todolistapiwithfaunadb.persistence;
import com.demo.todolistapiwithfaunadb.data.dataModel.Entity;
import com.demo.todolistapiwithfaunadb.data.dataModel.Page;
import com.demo.todolistapiwithfaunadb.data.dataModel.PaginationOptions;
import com.faunadb.client.FaunaClient;
import com.faunadb.client.errors.NotFoundException;
import com.faunadb.client.query.Expr;
import com.faunadb.client.query.Pagination;
import com.faunadb.client.types.Value;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
import java.util.Optional;
import java.util.concurrent.CompletableFuture;
import java.util.function.Function;
import java.util.stream.Collectors;
import static com.faunadb.client.query.Language.*;
public abstract class FaunaRepository<T extends Entity> implements Repository<T>, IdentityFactory {
@Autowired
protected FaunaClient faunaClient;
protected final Class<T> entityType;
protected final String collectionName;
protected final String collectionIndexName;
protected FaunaRepository(Class<T> entityType, String collectionName, String collectionIndexName) {
this.entityType = entityType;
this.collectionName = collectionName;
this.collectionIndexName = collectionIndexName;
}
// This method returns a unique valid Id leveraging Fauna's NewId function.
@Override
public CompletableFuture<String> nextId() {
CompletableFuture<String> result =
faunaClient.query(
NewId()
)
.thenApply(value -> value.to(String.class).get());
return result;
}
// This method saves an entity to the database using the saveQuery method below. It also returns the result of the saved entity.
@Override
public CompletableFuture<T> save(T entity) {
CompletableFuture<T> result =
faunaClient.query(
saveQuery(Value(entity.getId()), Value(entity))
)
.thenApply(this::toEntity);
return result;
}
// This method deletes from the data an entity(document) with the specified Id.
@Override
public CompletableFuture<Optional<T>> remove(String id) {
CompletableFuture<T> result =
faunaClient.query(
Select(
Value("data"),
Delete(Ref(Collection(collectionName), Value(id)))
)
)
.thenApply(this::toEntity);
CompletableFuture<Optional<T>> optionalResult = toOptionalResult(result);
return optionalResult;
}
// This method finds an entity by its Id and returns the entity result.
@Override
public CompletableFuture<Optional<T>> find(String id) {
CompletableFuture<T> result =
faunaClient.query(
Select(
Value("data"),
Get(Ref(Collection(collectionName), Value(id)))
)
)
.thenApply(this::toEntity);
CompletableFuture<Optional<T>> optionalResult = toOptionalResult(result);
return optionalResult;
}
// This method returns all entities(documents) in the database collection using the paginationOptions parameters.
@Override
public CompletableFuture<Page<T>> findAll(PaginationOptions po) {
Pagination paginationQuery = Paginate(Match(Index(Value(collectionIndexName))));
po.getSize().ifPresent(size -> paginationQuery.size(size));
po.getAfter().ifPresent(after -> paginationQuery.after(Ref(Collection(collectionName), Value(after))));
po.getBefore().ifPresent(before -> paginationQuery.before(Ref(Collection(collectionName), Value(before))));
CompletableFuture<Page<T>> result =
faunaClient.query(
Map(
paginationQuery,
Lambda(Value("nextRef"), Select(Value("data"), Get(Var("nextRef"))))
)
).thenApply(this::toPage);
return result;
}
// This is the saveQuery expression method used by the save method to persist the database.
protected Expr saveQuery(Expr id, Expr data) {
Expr query =
Select(
Value("data"),
If(
Exists(Ref(Collection(collectionName), id)),
Replace(Ref(Collection(collectionName), id), Obj("data", data)),
Create(Ref(Collection(collectionName), id), Obj("data", data))
)
);
return query;
}
// This method converts a FaunaDB Value into an Entity.
protected T toEntity(Value value) {
return value.to(entityType).get();
}
// This method returns an optionalResult from a CompletableFuture<T> result.
protected CompletableFuture<Optional<T>> toOptionalResult(CompletableFuture<T> result) {
CompletableFuture<Optional<T>> optionalResult =
result.handle((v, t) -> {
CompletableFuture<Optional<T>> r = new CompletableFuture<>();
if(v != null) r.complete(Optional.of(v));
else if(t != null && t.getCause() instanceof NotFoundException) r.complete(Optional.empty());
else r.completeExceptionally(t);
return r;
}).thenCompose(Function.identity());
return optionalResult;
}
// This method converts a FaunaDB Value into a Page with the Entity type.
protected Page<T> toPage(Value value) {
Optional<String> after = value.at("after").asCollectionOf(Value.RefV.class).map(c -> c.iterator().next().getId()).getOptional();
Optional<String> before = value.at("before").asCollectionOf(Value.RefV.class).map(c -> c.iterator().next().getId()).getOptional();
List<T> data = value.at("data").collect(entityType).stream().collect(Collectors.toList());
Page<T> page = new Page(data, before, after);
return page;
}
}
The
FaunaClientis@Autowiredwithin theFaunaRespositoryto run CRUD queries to your Fauna cloud database.The produced Id for
nextId()method is unique across the entire cluster, as you’ve seen before. For more details, check out Fauna’s documentation on NewId built-in function.The
SelectandValuefunctions are present in most of theFaunaRespositoryqueries. TheSelectfunction extracts a value under the given path. In contrast, theValuefunction defines the string value of the operation it performs.The
save()method uses the transactionalsaveQuery()method to perform a valid database save operation. For more details on the transactional query, check out Fauna’s documentation reference on Create, Replace, If, Exists built-in functions.The
remove()method uses the built-in Delete function to remove/delete a specific entity by Id.The
find()method uses the Get function to retrieve a single entity(document) by Id.The
findAll()method using thePaginationOptionsprovided paginates all entities(documents) in a collection. The Map applies the given Lambda to each element of the provided collection. It returns the results of each application in a new collection of the same type.-
The
toOptionalResult()method in-depth:- recovers from a Fauna’s NotFoundException with an Optional result, and
- Suppose the given
CompletableFuturecontains a successful result. In that case, it returns a newCompletableFuturecontaining the result wrapped in an Optional instance. - If the given
CompletableFuturecontains a failing result caused by aNotFoundException, it returns a newCompletableFuture. - Suppose the given
CompletableFuturecontains a failing result caused by aNotFoundException. In that case, it returns a newCompletableFuturecontaining an Optional empty instance. - Suppose the given
CompletableFuturecontains a failing result caused by any otherThrowable. In that case, it returns a newCompletableFuturewith the same failing result. - And finally, the method returns an Optional result derived from the original result.
Finally, to create a FaunaRepository implementation for the TodoEntity, create a TodoRepository class:
package com.demo.todolistapiwithfaunadb.persistence;
import com.demo.todolistapiwithfaunadb.data.TodoEntity;
import org.springframework.stereotype.Repository;
@Repository
public class TodoRepository extends FaunaRepository<TodoEntity> {
public TodoRepository(){
super(TodoEntity.class, "todos", "all_todos");
}
//-- Custom repository operations specific to the TodoEntity will go below --//
}
The
@Repositoryannotation indicates that the classTodoRepositoryprovides the mechanism for storage, retrieval, search, update and delete operation on objects.super()invokes theFaunaRepositoryconstructor to set thecollectionNameandindexNamefor theTodoEntity.In this repository class, you can add custom operations like
findByTitle()specific to theTodoEntity.
Service layer
In the service package, create a class TodoService:
package com.demo.todolistapiwithfaunadb.service;
import com.demo.todolistapiwithfaunadb.data.CreateOrUpdateTodoData;
import com.demo.todolistapiwithfaunadb.data.TodoEntity;
import com.demo.todolistapiwithfaunadb.data.dataModel.Page;
import com.demo.todolistapiwithfaunadb.data.dataModel.PaginationOptions;
import com.demo.todolistapiwithfaunadb.persistence.TodoRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Optional;
import java.util.concurrent.CompletableFuture;
@Service
public class TodoService {
@Autowired
private TodoRepository todoRepository;
public CompletableFuture<TodoEntity> createTodo(CreateOrUpdateTodoData data) {
CompletableFuture<TodoEntity> result =
todoRepository.nextId()
.thenApply(id -> new TodoEntity(id, data.getTitle(), data.getDescription()))
.thenCompose(todoEntity -> todoRepository.save(todoEntity));
return result;
}
public CompletableFuture<Optional<TodoEntity>> getTodo(String id) {
return todoRepository.find(id);
}
public CompletableFuture<Optional<TodoEntity>> updateTodo(String id, CreateOrUpdateTodoData data) {
CompletableFuture<Optional<TodoEntity>> result =
todoRepository.find(id)
.thenCompose(optionalTodoEntity ->
optionalTodoEntity
.map(todoEntity -> todoRepository.save(new TodoEntity(id, data.getTitle(), data.getDescription())).thenApply(Optional::of))
.orElseGet(() -> CompletableFuture.completedFuture(Optional.empty())));
return result;
}
public CompletableFuture<Optional<TodoEntity>> deleteTodo(String id) {
return todoRepository.remove(id);
}
public CompletableFuture<Page<TodoEntity>> getAllTodos(PaginationOptions po) {
return todoRepository.findAll(po);
}
}
The
@Serviceindicates that the classTodoServiceprovides some business functionalities, and theTodoRepositoryis@Autowiredin the service.The
createTodomethod builds up a new TodoEntity with the givenCreateUpdateTodoDataand a generated valid Id. Then, it saves the new entity into the database.getTodo()finds and retrieves a Todo by its Id from the database.updateTodo()looks up a Todo for the given Id and replaces it with the given*CreateUpdateTodoData*, if any.deleteTodo()deletes a Todo from the database for the given Id.getAllTodos()retrieves a Page of Todos from the database for the givenPaginationOptions.
Finally, to finish up your API, implement the REST endpoints in the rest layer.
Rest layer
In the rest package, create a class TodoRestController:
package com.demo.todolistapiwithfaunadb.rest;
import com.demo.todolistapiwithfaunadb.data.CreateOrUpdateTodoData;
import com.demo.todolistapiwithfaunadb.data.TodoEntity;
import com.demo.todolistapiwithfaunadb.data.dataModel.Page;
import com.demo.todolistapiwithfaunadb.data.dataModel.PaginationOptions;
import com.demo.todolistapiwithfaunadb.service.TodoService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.Optional;
import java.util.concurrent.CompletableFuture;
@RestController
public class TodoRestController {
@Autowired
private TodoService todoService;
@PostMapping("/todos")
public CompletableFuture<ResponseEntity> createTodo(@RequestBody CreateOrUpdateTodoData data) {
return todoService.createTodo(data)
.thenApply(todoEntity -> new ResponseEntity(todoEntity, HttpStatus.CREATED));
}
@GetMapping("/todos/{id}")
public CompletableFuture<ResponseEntity> getTodo(@PathVariable("id") String id) {
CompletableFuture<ResponseEntity> result =
todoService.getTodo(id)
.thenApply(optionalTodoEntity ->
optionalTodoEntity
.map(todoEntity -> new ResponseEntity(todoEntity, HttpStatus.OK))
.orElseGet(() -> new ResponseEntity(HttpStatus.NOT_FOUND))
);
return result;
}
@PutMapping("/todos/{id}")
public CompletableFuture<ResponseEntity> updateTodo(@PathVariable("id") String id, @RequestBody CreateOrUpdateTodoData data) {
CompletableFuture<ResponseEntity> result =
todoService.updateTodo(id, data)
.thenApply(optionalTodoEntity ->
optionalTodoEntity
.map(todoEntity -> new ResponseEntity(todoEntity, HttpStatus.OK))
.orElseGet(() -> new ResponseEntity(HttpStatus.NOT_FOUND)
)
);
return result;
}
@DeleteMapping(value = "/todos/{id}")
public CompletableFuture<ResponseEntity> deletePost(@PathVariable("id")String id) {
CompletableFuture<ResponseEntity> result =
todoService.deleteTodo(id)
.thenApply(optionalTodoEntity ->
optionalTodoEntity
.map(todo -> new ResponseEntity(todo, HttpStatus.OK))
.orElseGet(() -> new ResponseEntity(HttpStatus.NOT_FOUND)
)
);
return result;
}
@GetMapping("/todos")
public CompletableFuture<Page<TodoEntity>> getAllTodos(
@RequestParam("size") Optional<Integer> size,
@RequestParam("before") Optional<String> before,
@RequestParam("after") Optional<String> after) {
PaginationOptions po = new PaginationOptions(size, before, after);
CompletableFuture<Page<TodoEntity>> result = todoService.getAllTodos(po);
return result;
}
}
The rest controller method with
@PostMapping("/todos")mapping creates a new Todo with the given@RequestBodyCreateOrUpdateTodoDatadata.The rest controller methods with
@GetMapping("/todos/{id}")and@DeleteMapping(value = "/todos/{id}")mappings retrieves and deletes respectively a Todo with Id bound by@PathVariable("id").The rest controller method with
@PutMapping("/todos/{id}")mapping updates Todo data with Id bound by@PathVariable("id").The rest controller method with
@GetMapping("/todos")mapping takes three@RequestParam's (size, before, after) that builds up thePaginationOptionsfor the database query.
And you’re done implementing a Todo List API with Fauna and Java using Spring Boot. See the API final project directory structure:

Testing the Todo List API
To test your API endpoints, run the Spring Boot project, and the API will start by default at port 8080. Open Postman:
Create a new Todo
POST /todos:

You can check on your Fauna dashboard to see the created Todo document:

Get a Todo by Id
GET /todos/{id}:

Update a Todo by Id
PUT /todos/{id}:

You can check on your Fauna dashboard to see the updated Todo document:

Delete a Todo by Id
DELETE /todos/{id}:

You can check on your Fauna dashboard to see the empty Todos collection:

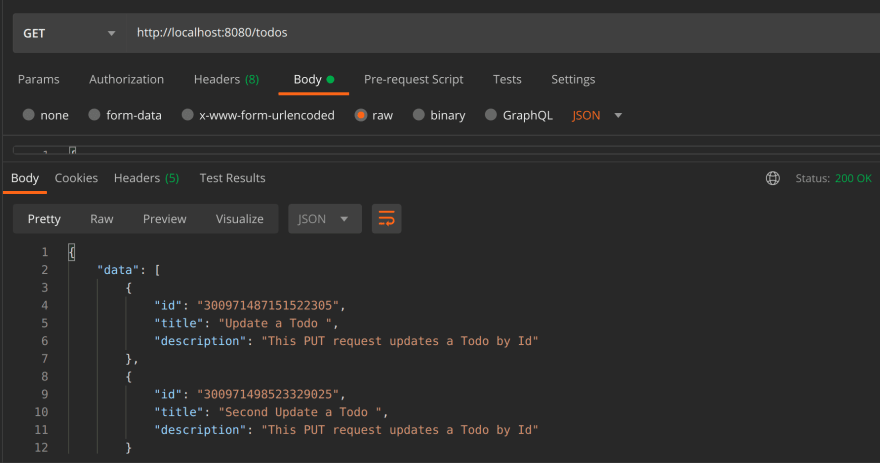
Get all Todos
Create two more todos to test this.
GET /todos:
Conclusion
In this tutorial, you saw why you should use the Fauna cloud database in creating a Spring Boot application and how Fauna works. Also, you set up Spring Boot with Fauna, implemented a Todo List API with Fauna, and test the Todo List API using Postman.
You can see more resources on building with Fauna and Java:
Posted on July 2, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related