Web Scraping with Python BeautifulSoup and Requests

Kashif Aziz
Posted on December 20, 2017
This is an overview of a blog post I recently wrote about how to scrap web pages using Python BeautifulSoup and Requests libraries.
What is Web Scraping:
Web scraping is the process of automatically extracting information from a website. Web scraping, or data scraping, is useful for researchers, marketers and analysts interested in compiling, filtering and repackaging data.
A word of caution: Always respect the website’s privacy policy and check robots.txt before scraping. If a website offers API to interact with its data, it is better to use that instead of scraping.
Web Scraping with Python and BeautifulSoup:
Web scraping in Python is a breeze. There are number of ways to access a web page and scrap its data. I have used Python and BeautifulSoup for the purpose.
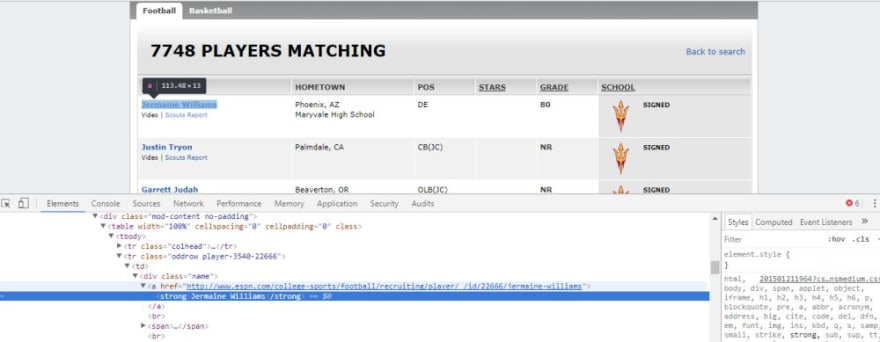
In this example, I have scraped college footballer data from ESPN website.
The Process:
- Install requests and beautifulsoup libraries
- Fetch the web page and store it in a BeautifulSoup object.
- Set a parser to parse the HTML in the web page. I have used the default html.parser
- Extract the player name, school, city, playing position and grade.
- Appended the data to a list which will be written to a CSV file at later stage.
The Code:
Posted on December 20, 2017
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.