
Kane Hooper
Posted on January 30, 2024

G’day Rubyists. I’m currently working with a client on implementing a custom AI solution using an open source AI model. The reason for this is the client has very sensitive customer information and we don’t want to pass this across to OpenAI or other proprietary models, in order to maintain a very high level of security.
The solution has been to download and run an open source AI model in an AWS virtual machine, keeping the model completely under our control, with the Rails application making API calls to the AI in a safe environment.
I wanted to share with you how to download an open source AI model locally, get it running and run Ruby scripts against it.
Why Go Custom?
The reason behind this project is straightforward: data security. When dealing with sensitive client information, the safest route is often to keep things in-house. This approach led us to explore custom AI models, which offer a higher degree of control and privacy.
Open source models
Over the last 6 months we have started to see a plethora of open source models hitting the market. While not as powerful as GPT-4, many of these models are showing performance that exceeds GPT-3.5 and they are only going to get better as time goes on.
There are a few other successful AI model such as Mistral, Mixtral and Lama. The right model to use depends on your processing power and what you are trying to achieve.
As we are going to be running this model locally, probably the best option is Mistral. It is about 4GB in size and outperformance GPT-3.5 on most metrics. For it’s size Mistral is the best model in my opinion.
Mixtral, out performs Mistral, but it a huge model and requires at least 48GB of RAM to run.
Parameters
When talking about Large Language Models they are generally referred to by their parameter size, and a brief description of this is useful.
The Mistral model, which we will be running locally, is a 7 billion parameter model. Mixtral is a 70 billion parameter model.
It works this way, all of these LLMs are neural networks. A neural network is a collection of neurons, and each neuron connects to all of the other neurons in the proceeding layers.
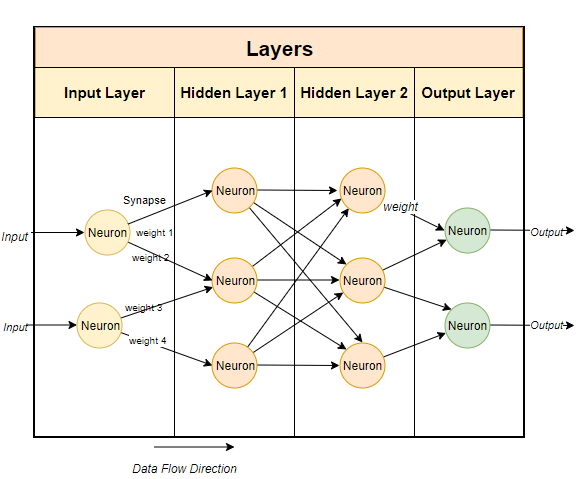
Each connection has a weight, which is usually a percentage. Each neuron also has a bias which modifies the data as it passed through that node.
The whole purpose of a neural network is to “learn” a very advanced algorithm which is effectively a pattern matching algorithm. In the case of LLMs, by being trained of huge amounts of text, it learns the ability to predict text patterns and so can generate meaningful responses to our prompts.
In simple terms the parameters are the number of weights and biases in the model. This tends to give us an idea of how many neurons are in the neural network. For a 7 billion parameter model there will be something on the order of 100 layers, with thousands of neurons per layer.
To put in context GPT-3.5 has about 175 billion parameters. It’s actually quite amazing that Mistral with 7 billion parameters can outperform GPT-3.5 in many metrics.
Software to run models locally
In order to run our open source models locally it is necessary to download software to do this. While there are several options on the market the simplest I found, and the one which will run on an Intel Mac, is Ollama.
Right now Ollama runs on Mac and Linux, with Windows coming in the future. Though you can use WSL on Windows to run a Linux shell.
Ollama allows you to download and run these open source models. It also opens up the model on a local port giving you the ability to make API calls via your Ruby code. And this is where it gets fun as a Ruby developer. You can write Ruby apps that integrate with your own local models.
You can also watch this setup process on my YouTube video.

Running open-source AI models locally with Ruby - YouTube
reinteractive CEO shares his process for using Ollama.ai on a local computer to set up and run a large language model that captures and learns a unique set o...
Setting Up Ollama
Installation of Ollama is straightforward on Mac and Linux systems. Just download the software and it will install the package. Ollama is primarily command-line based, making it easy to install and run models. Just follow the steps and you will be set up in about 5 minutes.
- Download Ollama at https://olama.ai/
Installing your first model
Once you have Ollama set up and running, you should see the Ollama icon in your task bar. This means it’s running in the background and will run your models.
The next step is to download the model.
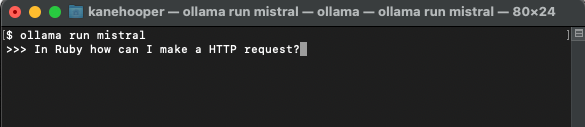
Open your terminal
Run the following command:
ollama run mistral
The first time this will download Mistral, which will take some time as it is about 4GB in size.
Once it has finished downloading it will open the Ollama prompt and you can start communicating with Mistral.
Next time you run ollama run mistral it will just run the model.
Customizing Models
With Ollama you can create customizations to the base model. This is a little like creating custom GPTs in OpenAI.
Full details are provided in the Ollama documentation.
The steps to create a custom model are fairly simple:
Create a Modelfile
Add the following text to the Modelfile:
FROM mistral
# Set the temperature set the randomness or creativity of the response
PARAMETER temperature 0.3
# Set the system message
SYSTEM ”””
You are an excerpt Ruby developer.
You will be asked questions about the Ruby Programming
language.
You will provide an explanation along with code examples.
”””
The system message is what primes the AI model to respond in a given way.
Create the new model. Run the following command in the terminal:
ollama create <model-name> -f ‘./Modelfile’
In my case, I am calling the model Ruby.
ollama create ruby -f ‘./Modelfile’
This will create the new model.
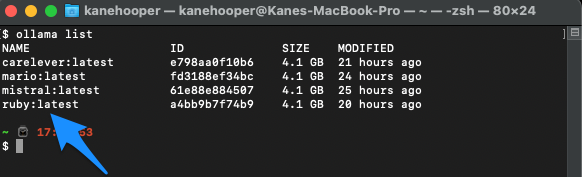
List your models with the following command:
ollama list
Now you can run the custom model
ollama run ruby
Integrating with Ruby
Although there's no dedicated gem for Ollama yet, Ruby developers can interact with the model using basic HTTP request methods. Ollama runs in the background, and it opens up the model via port 11434, so you can access it on `http://localhost:11434’.
The Ollama API documentation provides the different endpoints for the basic commands such as chat and creating embeddings.
For us we want to work with the /api/chat endpoint to send a prompt to the AI model.
Here is some basic Ruby code for interacting with the model.
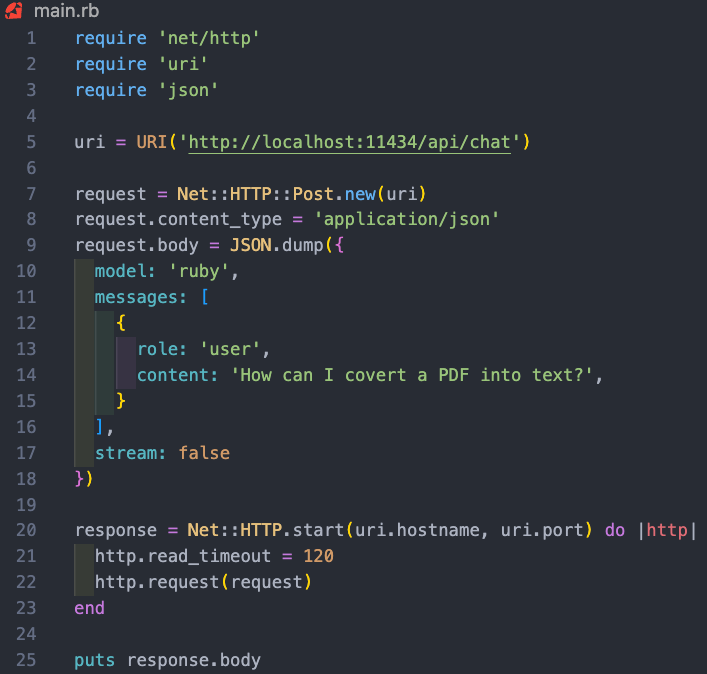
The Ruby code does the following:
The code starts by requiring three libraries: 'net/http', 'uri', and 'json'. These libraries are used for making HTTP requests, parsing URIs, and handling JSON data respectively.
A URI object is created with the address of the API endpoint ('http://localhost:11434/api/chat').
A new HTTP POST request is created using the Net::HTTP::Post.new method with the URI as the argument.
The content type of the request is set to 'application/json'.The body of the request is set to a JSON string that represents a hash. This hash contains three keys: 'model', 'messages', and 'stream'. The 'model' key is set to 'ruby' which is our model, the 'messages' key is set to an array containing a single hash representing a user message, and the 'stream' key is set to false.
The messages hash follows a model for intersecting with AI models. It takes a role and the content. The roles can be system, user and assistance. System is the priming message for how the model should respond. We already set that in the Modelfile. The user message is our standard prompt, and the model will respond with the assistant message.
The HTTP request is sent using the Net::HTTP.start method. This method opens a network connection to the specified hostname and port, and then sends the request. The read timeout for the connection is set to 120 seconds given that I am running on a 2019 Intel Mac, the responds can be a little slow. This isn’t an issue running on the appropriate AWS servers.
The response from the server is stored in the 'response' variable.
Practical Use Cases
The real value of running local AI models comes into play for companies dealing with sensitive data. These models are really good at processing unstructured data, like emails or documents, and extracting valuable, structured information.
For one use case I am training the model on all of the customer information in a CRM. This allows users to ask questions about the customer without needing to go through sometimes hundreds of notes.
Conclusion
Where security is not an issue I am more likely to work directly with OpenAI. But for companies that need private models, then Open Source is definitely the way to go.
If I get around to it, one of these days I’ll write a Ruby wrapper around the Ollama APIs to make it a little easier to interact with. If you would like to work on that project, then definitely reach out.
Have fun working with open source models.
Kane Hooper is the CEO of reinteractive a specialist Ruby on Rails dev firm.
If you need any help with your Rails or AI projects you can contact Kane directly.
kane.hooper@reinteractive.com
reinteractive.com
Posted on January 30, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

