
Kamila Santos Oliveira
Posted on July 29, 2020

In part 1 we talk about some concepts used in reactive programming, now, in part 2 we will understand the reason for Webflux was created and how its architecture works :)
What is Spring WebFlux?
Spring WebFlux can be defined as a “parallel” version to the already known and widely used Spring MVC, with the main difference being the support for reactive NIO streams and for supporting the concept of backpressure and with Netty server coming by default embedded in its architecture.
Since version 5.0 of the Spring Framework we have a reactive part in addition to the Servlet structure that already existed, each module of these is optional, you can use the Servlet part to reactive part or even both in your applications.
This can be best exemplified through the image below:
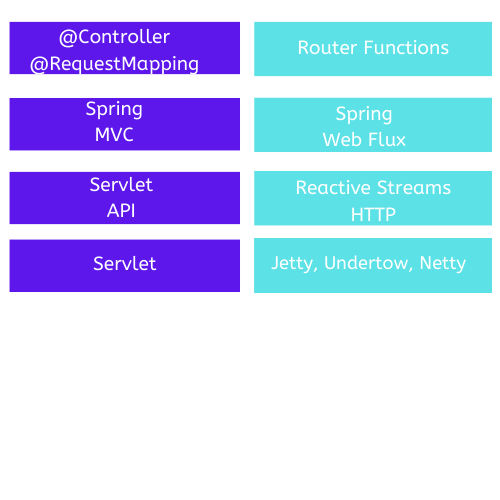
Webflux is in the "reactive part" of the stack, where:
- instead of servlet we work with Netty / Undertow as a server;
- We do not use the Servlet API (which is blocking) and we use Reactive Streams;
- we started using router functions instead of @Controller
It is important to note that we can use only one or even both architectures, using the best of both.
Spring Webflux was developed due to the need for non-blocking applications that were able to work with a small number of threads simultaneously and that could be run with a few hardware resources.
In Servlet 3.1 an NIO API was provided, but its use does not match the rest of the API and all the concepts behind Servlet, which has blocking contracts like getPart and getParameter for example and their contracts were defined in a way synchronous using Filter and Servlet as an example.
These factors were decisive for the development of a new API that would be used independently of the execution time and in a non-blocking way, which was possible with the servers that consolidated themselves in the asynchronous and non-blocking operation, for example Netty.
Another reason is that WebFlux makes it easier to understand and use functional / reactive programming concepts. With the addition of functional features from Java 8 (such as lambda expressions, streams, Optional ...). In terms of style / programming model, Java 8 allowed Spring WebFlux to have functional endpoints and annotated controllers in the applications.
How does it work?
In the MVC model, requests work as follows:
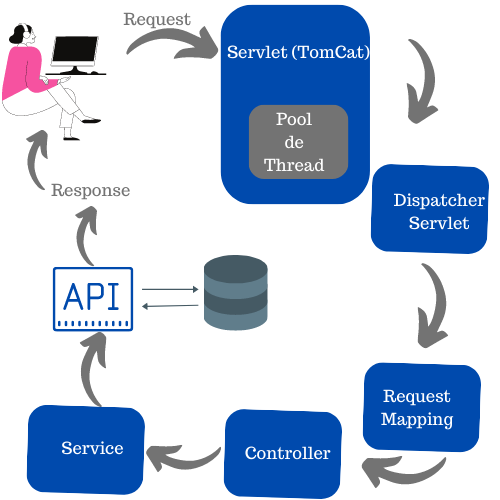
The client makes a request, which is received by TomCat and controlled by the thread pool, this is passed on to the Dispatcher Servlet that dispatches that request to the corresponding endpoint in RequestMapping, which will be received at the Controller, which will handle the service and by end will return a response. This whole process occurs in a blocking way, that is, another request will only enter when the previous one is completed.
In Webflux, this would be a little different:
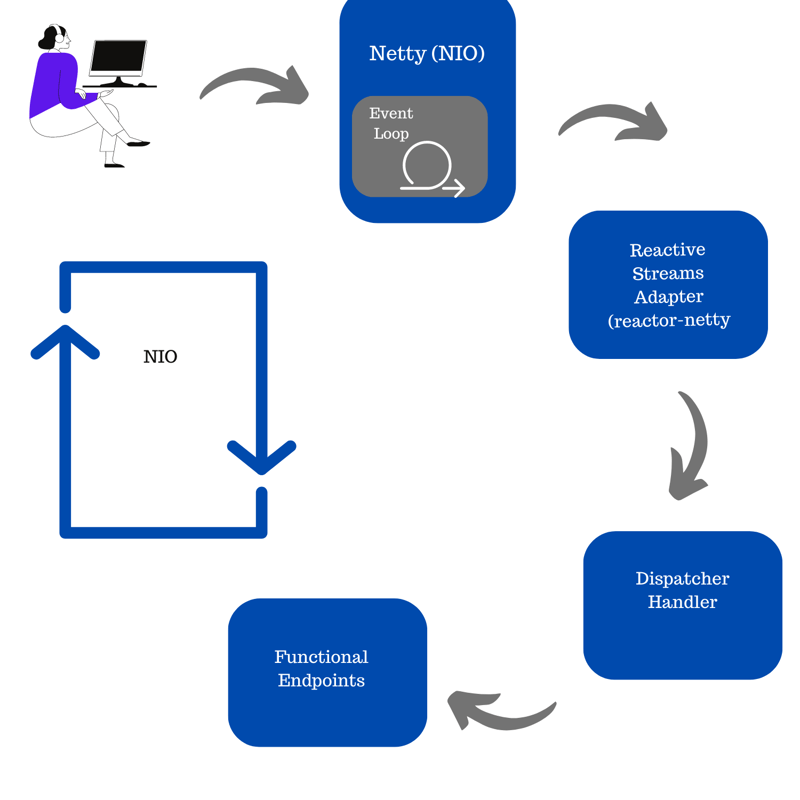
The client makes the request that goes to our non-blocking server (Netty), which inside it has an event loop that manages these requests, then it passes to the reactor-netty (which makes this interface reactive with the application), it passes to the dispatcher handler, which through functionals endpoints will generate this response, and, throughout this process, new requests can be made, as it is a non-blocking architecture.
We can say that Spring WebFlux uses the best of the servlet stack along with its reactive features, as we can see in the image below the documentation of the Spring:
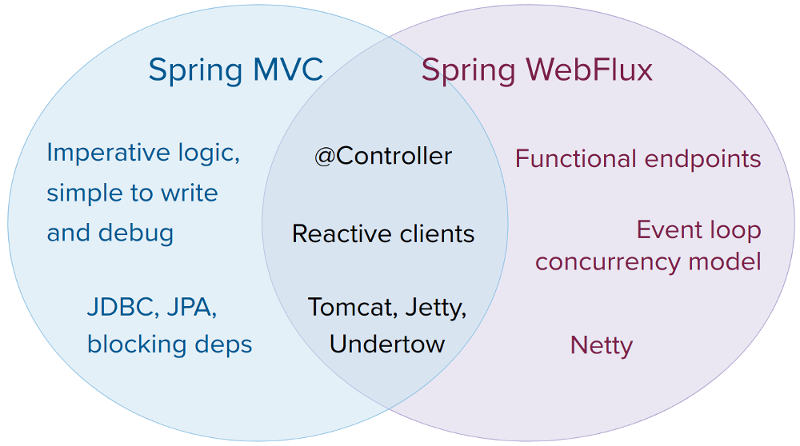
On the MVC side we have imperative programming, JDBC / JPA and other blocking dependencies / processes.
On the Spring Webflux side, we have funcitonal endpoints, event loop, Netty and some features that already existed in MVC but who in Webflux started to have greater support, such as Reactive Clients.
This article introduced the reason for creating WebFlux and its differences from MVC, in the next article we will talk about Project Reactor!
Thanks,
Posted on July 29, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

