gRPC Demystified - Introduction to gRPC

Kostas Kalafatis
Posted on February 7, 2023

What is the Client-Server Model
In practice, the client-server model is the fundamental operating principle of all data centers, including the cloud. The term "client server model" simply refers to a strategy in which not all required applications and files are installed directly on an endpoint. Instead, some or all of these files or apps are installed on another server. Clients, which can be laptops, desktops, tablets, or smartphones, then ask the remote server for a file or application. The server receives the request, verifies the credentials, and then serves the requested file to the client if everything checks out.
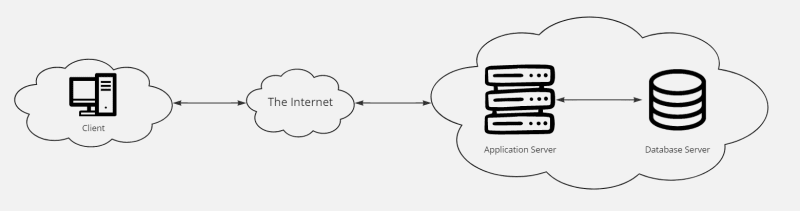
Communication between clients and servers is bidirectional. Servers can contact clients to ensure that they have the necessary patches and updates or to see if they require anything else. Once the server has finished its work, it disconnects from the client to save bandwidth and space on the network.
A client is a program that initiates communication, most commonly by establishing a TCP connection. It could be an end-user program that initiates communication in order to request information or resources that it then presents to the user. The client in web applications, for example, is a web browser such as Chrome or Firefox.
A server is a program that accepts client connections and handles their requests. There are various types of servers. The diagram depicts an application server, which serves data to the client application. (It is also called a web server if it uses HTTP as the communication protocol.) The application server, as depicted in the diagram, may involve other computers in order to serve responses. In that case, the server serves as both a client and a server. The application server is depicted as a database client, requesting information from the database server.
Most networking protocols follow this pattern: a client connects to a server and sends requests. The server accepts requests, processes them, and then sends responses. This request-response flow was conceived in the early days of networking in the 1960s and has since been the foundation of distributed computing.
What is HTTP
HTTP is a protocol used to retrieve resources such as HTML documents. It is the foundation of all data exchange on the Web and is a client-server protocol, which means that requests are initiated by the recipient, which is typically the Web browser. A complete document is reconstructed from the various sub-documents retrieved, such as text, layout descriptions, images, videos, scripts, and others.
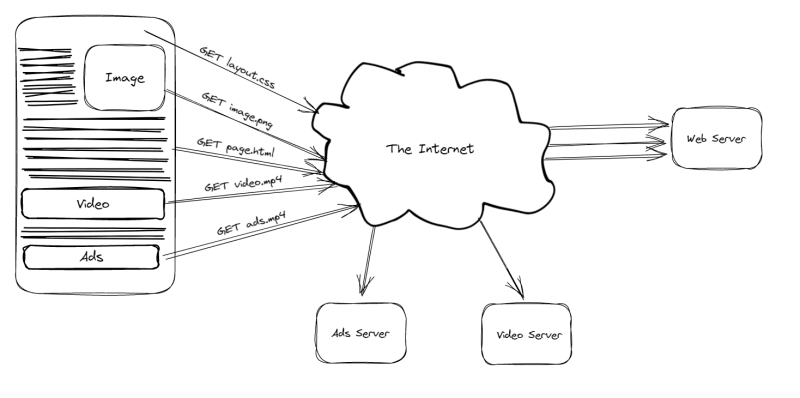
Clients and servers communicate by sending and receiving individual messages (as opposed to a stream of data). Requests are messages sent by the client, which is usually a Web browser, and responses are messages sent by the server as an answer.
Components of HTTP-based systems
HTTP is a client-server protocol, which means that requests are sent by a single entity, the user-agent (or a proxy on its behalf). The user-agent is typically a Web browser, but it could be anything, such as a robot that crawls the Web in order to populate and maintain a search engine index.
Each request is routed to a server, which processes it and returns an answer known as the response. Between the client and the server, there are many things called "proxies" that do different things, like act as gateways or caches.
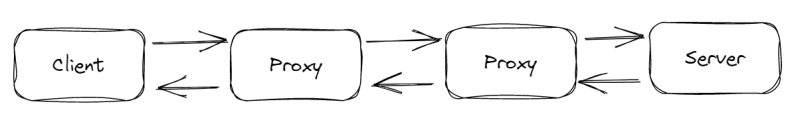
In reality, there are more computers between a client and the server processing the request: routers, modems, and other devices. These are hidden in the network and transport layers due to the Web's layered design. At the application layer, HTTP is on top. Although useful for troubleshooting network issues, the underlying layers are mostly irrelevant to the description of HTTP.
Basic aspects of HTTP
HTTP is simple.
Even with the additional complexity introduced by HTTP/2 by encapsulating HTTP messages in frames, HTTP is generally designed to be simple and human-readable. Humans can read and understand HTTP messages, making testing easier for developers and simplifying things for newcomers.
HTTP is extensible.
HTTP headers, first introduced in HTTP/1.0, allow this protocol to be easily extended and experimented with. A simple agreement between a client and a server about how a new header should be interpreted can even add new features.
HTTP is stateless but not sessionless.
HTTP is stateless: there is no connection between two requests sent on the same connection. This immediately raises the possibility of problems for users attempting to interact coherently with specific pages, such as when using e-commerce shopping baskets. However, while the core of HTTP is stateless, HTTP cookies enable the use of stateful sessions. Using header extensibility, HTTP cookies are added to the workflow. This makes it possible for each HTTP request to create a new session that shares the same context or state.
HTTP flow
When a client wishes to communicate with a server, whether the final server or an intermediate proxy, the following steps are taken:
- Open a TCP connection: The TCP connection is used to send one or more requests and receive responses. The client can set up a new connection, use an existing connection, or set up multiple TCP connections to the servers.
- Send an HTTP message: HTTP messages (prior to HTTP/2) are readable by humans. HTTP/2 encapsulates these simple messages in frames, making them impossible to read directly, but the principle remains the same. As an example:
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: en
- Read the response sent by the server:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html>… (here come the 29769 bytes of the requested web page)
- Close the connection or use it for further requests.
What is REST
Representational State Transfer (REST) is a software architecture that imposes conditions on how an API should work. REST was initially created as a guideline to manage communication on a complex network like the internet. You can use a REST-based architecture to support high-performing and reliable communication at scale. You can easily implement and modify it, bringing visibility and cross-platform portability to any API system.
API developers can create APIs using a variety of architectures. REST APIs are APIs that adhere to the REST architectural style. RESTful web services are web services that use the REST architecture. RESTful APIs are commonly referred to as RESTful web APIs. However, the terms REST API and RESTful API can be used interchangeably.
The following are some of the REST architectural principles:
Uniform interface
A consistent interface is essential in the design of any RESTful web service. It denotes that the server sends data in a standard format. In REST, the formatted resource is referred to as a representation. This format may differ from the server application's internal representation of the resource. For example, the server may store data as text but send it in HTML format.
Statelessness
Statelessness in REST architecture refers to a communication method in which the server completes each client request independently of all previous requests. Clients can request resources in any order they want, and each request is stateless and independent of the others. This REST API design restriction means that the server must always fully understand the request and fulfill it.
Layered system
The client can connect to other authorized intermediaries between the client and the server in a layered system architecture and still receive responses from the server. Servers can also route requests to other servers. Your RESTful web service can be designed to run on multiple servers with multiple layers, such as security, application, and business logic, all working together to fulfill client requests. The client is unaware of these layers.
Cacheability
Caching, which is the process of storing some responses on the client or an intermediary to improve server response time, is supported by RESTful web services. Assume you visit a website that uses the same header and footer images on every page. The server must resend the same images every time you visit a new website page. To avoid this, after the first response, the client caches or stores these images and then uses them directly from the cache. Caching is handled by RESTful web services by using API responses that say whether something can be cached or not.
Code on demand
Servers can temporarily extend or customize client functionality in the REST architectural style by transferring software programming code to the client. When you fill out a registration form on any website, for example, your browser immediately highlights any errors you make, such as incorrect phone numbers. This is possible due to the code sent by the server.
How do RESTful APIs work?
A RESTful API performs the same basic function as browsing the internet. When a resource is required, the client contacts the server via the API. In the server application API documentation, API developers explain how the client should use the REST API. The general steps for any REST API call are as follows:
- The client sends a request to the server. The client follows the API documentation to format the request in a way that the server understands.
- The server makes sure the client is who they say they are and that they are allowed to make the request.
- The server receives the request and processes it internally.
- The client receives a response from the server. The response contains information that indicates whether or not the client's request was successful. Any information requested by the client is also included in the response.
What does the RESTful API client request contain?
RESTful APIs require the following main components in requests:
Unique Resource Identifier (URI)
The server assigns unique resource identifiers to each resource. The server typically performs resource identification for REST services by using a Uniform Resource Locator (URL). The path to the resource is specified by the URL. A URL is similar to the website address you type into your browser to access any webpage. The URL, also known as the request endpoint, clearly indicates to the server what the client requires.
Method
RESTful APIs are frequently implemented by developers using the Hypertext Transfer Protocol (HTTP). An HTTP method tells the server what to do with a resource. The four most common HTTP methods are as follows:
GET
Clients use GET to access resources on the server that are located at the specified URL. They can store GET requests and add parameters to RESTful API requests to tell the server to filter data before sending it.
POST
POST is used by clients to send data to the server. They send the data representation along with the request. Sending the same POST request multiple times results in multiple creations of the same resource.
PUT
PUT is used by clients to update existing server resources. Unlike POST, sending the same PUT request to a RESTful web service multiple times yields the same result.
DELETE
To remove a resource, clients use the DELETE request. A DELETE request can cause the server's state to change. The request, however, fails if the user does not have appropriate authentication.
HTTP Headers
The metadata exchanged between the client and server is represented by request headers. For example, the request header specifies the format of the request and response, as well as information about the request's status.
Data
Requests to the REST API may include data that is needed for the POST, PUT, and other HTTP methods to work.
Parameters
RESTful API requests can include parameters that provide additional information to the server about what needs to be done. The following are some examples of parameters:
- Path parameters that specify URL details.
- Query parameters that request more information about the resource.
- Cookie parameters that authenticate clients quickly.
REST is the foundation for a plethora of RPC systems. Some, such as Swagger and JAX-RS, make full use of REST's flexibility (the Java APIs for REST-ful web services). Swagger is a cross-platform and language-independent technology whose IDL—the Swagger specification—describes how a set of operations is represented in HTTP requests and responses. The specification describes the HTTP method, URI path patterns, and even the request and response structures for each operation. There are code generation tools available to generate client stubs and server interfaces from a Swagger specification.
JAX-RS, on the other hand, is only for Java, and its IDL is written in Java. To define the operations, a Java interface is used, with annotations controlling how its methods, arguments, and return values are mapped to the HTTP protocol. Servers can provide interface implementations. A client stub is a runtime-generated implementation of that interface that intercepts method calls and converts them into outgoing HTTP requests using reflection.
Other RPC systems are HTTP-based. They can be viewed as narrow subsets of REST: they still adhere to its architectural principles but impose significant constraints and conventions on resource naming, methods, and document encoding to simplify client and server implementation. Such systems, such as XML-RPC and SOAP, were developed during the "adolescent era" of the web. As XML's popularity waned, new approaches to content encoding emerged, such as JSON-RPC. In fact, gRPC falls into this category.
Remote Procedure Calls (RPC)
RPC is an abbreviation for "Remote Procedure Calls**". It is a programming model that is built on the foundation of request-response network protocols. For a client, issuing an RPC is equivalent to invoking a procedure from the application code. Serving an RPC on a server is equivalent to executing a procedure with a specific signature.
The objects in the client that expose these procedures are known as stubs. When application code invokes a procedure on a stub, the stub converts the arguments into bytes and then sends a request to the server, the contents of which are the serialized arguments. When it receives a response from the server, it converts the bytes into a result value, which is then returned to the application code that called it.
Service implementations are the objects on the server that expose these procedures. The server machinery receives the request, converts the bytes into procedure arguments, and then calls a procedure on the service implementation with those arguments. The service implementation executes its business logic and then returns a result, either a value in the case of success or an error code in the case of failure. (In some RPC implementations, servers may return both values and an error code.) This result is then translated by the server machinery into bytes, which become the response that is sent back to the client.
RPC is not a new way of programming. Proposals for remote procedure call semantics were written in the 1970s, and practical RPC implementations like the Network File System (NFS) came out in the 1980s.
gRPC is a cross-platform RPC system that can communicate with a wide range of programming languages. It does a great job of delivering high performance and ease of use, making it much easier to build all kinds of distributed systems.
RPC Systems
Some characteristics are shared by all RPC systems. Some systems have some of these characteristics, whereas mature systems have all of them:
- Of course, all RPC systems make procedure calls; the networking aspect of the technology is abstracted away from application code, giving it the appearance of a normal in-process function call rather than an out-of-process network call.
- Interfaces can be defined as the names and signatures of procedures that can be invoked, as well as the data types that are exchanged as arguments and return values. For language-agnostic RPC systems (those that can be used with multiple programming languages), the interface is typically defined in an "Interface Definition Language", or IDL for short. IDLs can describe the structure of data and interfaces, but not business logic.
- RPC systems frequently include code generation tools to convert interface descriptions into usable libraries. They also include a runtime library that handles transport protocol details and provides an Application Binary Interface (ABI) for generated code to connect to that transport implementation. Some systems rely more on runtime reflection than code generation. This can even differ between programming languages for different implementations of a single RPC system.
- Unlike REST, these systems do not typically expose all of HTTP's flexibility. Some people avoid HTTP entirely, instead using a custom binary TCP protocol. Those that do use HTTP as a transport typically have rigid conventions for mapping RPCs to HTTP requests, which are often inflexible. The specifics of the HTTP request are intended to be implementation details encapsulated in the system's transport implementation.
gRPC
Let's talk about gRPC now. First, it's important to know that gRPC's architecture is layered.
The transport layer is the lowest layer, and gRPC uses HTTP/2 as its transport protocol. HTTP/2 has the same basic semantics as HTTP 1.1 (the version most developers are familiar with), but it aims to be more efficient and secure. The most noticeable new features of HTTP/2 are that it can multiplex many parallel requests over the same network connection and that it supports full-duplex bidirectional communication. In a later post in this series, we will discuss HTTP/2 and how it differs from and improves on HTTP 1.1.
The channel is the subsequent layer. This is a thin abstraction of transportation. The channel defines calling conventions and maps RPCs to the underlying transport. A gRPC call at this layer includes a client-supplied service and method name, optional request metadata (key-value pairs), and zero or more request messages. When the server provides optional response header metadata, zero or more response messages, and response trailer metadata, the call is considered complete. The trailer metadata indicates whether the call was a success or a failure. There is no knowledge of interface constraints, data types, or message encoding at this layer. A message is nothing more than a series of zero or more bytes. There can be any number of request and response messages on a call.
The stub is the final layer. Interface constraints and data types are defined in the stub layer. Does a method accept a single request message or a stream of requests? What type of data is contained in each response message, and how is it encoded? The stub provides the answers to these questions. The stub connects IDL-defined interfaces to channels. The IDL is used to generate the stub code. The channel layer is responsible for providing the ABI that these generated stubs use.
Protocol Buffers are an important part of gRPC. Protocol Buffers, also known as "protobufs," are a type of IDL that is used to describe services, methods, and messages. A compiler generates code for a variety of programming languages, as well as runtime libraries for each of those languages, from IDL. It is important to note that Protocol Buffers only play a role in the final layer of the above list: the stub. The lower layers of gRPC, the channel and transport, are IDL-independent. This enables the use of any IDL with gRPC (though the core gRPC libraries only provide tools for using protobufs). There are even unique open source implementations of the stub layer that use different formats and IDLs, such as flatbuffers and messagepack.
Streaming
Streaming allows a request or response to be arbitrarily large in size, which is useful for operations that require uploading or downloading large amounts of data. Most RPC systems require that RPC arguments be represented in memory as data structures, which are then serialized to bytes and sent over the network. When a large amount of data must be exchanged, both the client and server processes may experience significant memory pressure. To avoid resource exhaustion, operations typically impose hard limits on the size of request and response messages. Streaming solves this problem by allowing the request or response to be an infinitely long sequence of messages. A request or response stream's total size may be enormous, but clients and servers do not need to store the entire stream in memory. They can instead operate on a subset of data, even as few as one message at a time.
gRPC not only supports streaming but also full-duplex, bidirectional streams. The client can use a stream to upload an arbitrary amount of request data, and the server can use a stream to send back an arbitrary amount of response data, all within the same RPC. The "full-duplex" part is the novel part. Most request-response protocols, including HTTP 1.1, operate on a "half-duplex" basis. They allow bidirectional communication (HTTP 1.1 even allows bidirectional streaming), but not both directions at the same time. Before the server can respond, the request must be fully uploaded; only after the client has finished transmitting can the server respond with its full response. gRPC is built on HTTP/2, which explicitly supports full-duplex streams, allowing the client to upload request data while the server sends back response data. This is extremely powerful and eliminates the need for web sockets, an HTTP 1.1 extension that allows full-duplex communication over an HTTP 1.1 connection. Streaming allows applications to build very sophisticated conversational protocols on top of gRPC.
Where to use gRPC
You should have a good idea of what gRPC is by now. So far, we've seen that gRPC is a request-response protocol for streaming RPC that defines interfaces with Protocol Buffers. But where and why should you use gRPC in your application?
We can leverage gRPC almost anywhere two or more computers communicate over the network:
Microservices: gRPC excels at connecting servers in service-oriented environments. One of the original problems it aimed to solve with its predecessor, Stubby, was connecting microservices. It is well-suited for a wide range of applications, ranging from medium and large enterprise systems to "web-scale" eCommerce and SaaS offerings.
Client-Server Applications: gRPC works equally well in client-server applications where the client application is run on a desktop or mobile device. It employs HTTP/2, which outperforms HTTP 1.1 in terms of latency and network utilization.
Integration and APIs: gRPC is also a method of providing APIs over the Internet for integrating applications with the services of third-party providers. Many of Google's Cloud APIs, for example, are exposed via gRPC. This is a different approach than REST+JSON, but it does not have to be mutually exclusive.
grpc-gatewayis a tool for easily exposing gRPC services over REST and JSON.Browser-based Web applications: The final major area appears to be a poor fit at first glance. Because gRPC has a strict requirement for HTTP/2 but browser XHRs do not, JavaScript code running in a browser cannot directly use it. However, as previously mentioned, there are tools for exposing your gRPC APIs as REST+JSON, which browser clients can then consume.
There are alternatives to using gRPC in each of the scenarios listed above. In fact, REST and JSON have become de facto standards for all of these scenarios. So, why not use gRPC instead? There are several dimensions where gRPC outperforms the competition, particularly in REST and JSON:
Performance: HTTP 1.1 is a verbose protocol, and JSON is a message format that is even more verbose. They are excellent for human readability but less so for computer readability, necessitating extensive string parsing. HTTP 1.1 also has a strict limitation on how a single connection can be used for multiple requests: all requests must be returned in the order in which they were received. Pipelining clients will experience head-of-line blocking delays, but later responses may have been computed quickly and must wait for earlier responses to be computed and transmitted before they can be sent. Using a connection for only one request at a time and then using a pool of connections to issue parallel requests consumes more resources on both clients and servers, as well as potentially on proxies and load balancers. HTTP/2 and Protocol Buffers do not suffer from these issues. HTTP/2 is significantly less verbose, owing largely to header compression. It also supports multiplexing multiple requests over a single connection. Protocol bytes, unlike JSON, were designed to be both compact on the wire and easy to parse by computers. As a result, gRPC can reduce resource usage, resulting in faster response times when compared to REST and JSON. This also means less network traffic and longer battery life for clients using mobile devices.
Programming Model: The gRPC programming model is simple to grasp and leads to increased developer productivity. When you define interfaces and canonical message formats in an IDL, a lot of boilerplate code is generated for you. Forget about manually configuring server handlers based on URI paths and manually marshalling paths, query string parameters, requests, and response bodies. Similarly, gone are the days of manually creating HTTP request objects with all of the associated server overhead. While there are numerous tools and libraries that can alleviate this burden for REST+JSON (including a large number of home-grown, proprietary solutions within organizations and projects), they tend to vary significantly from programming language to programming language and possibly even from project to project. And in some cases, they are insufficient: for example, one library may address one aspect (reducing boilerplate in servers) but fail to address others (common definitions of interfaces and message schemas, reducing boilerplate in clients). gRPC is comprehensive; it addresses all of these concerns. It also does so in a consistent manner across a variety of programming languages. This is especially relevant if you write code in multiple languages and/or work in a polyglot environment.
Streaming: Full-duplex bidirectional streaming is one of the "killer features" of gRPC. While the vast majority of RPCs will be simple "unary" operations (a single simple request and a single response), there may be times when something more sophisticated is required. Whether it's availability (especially for performance reasons), server-push facilities for sending notifications, or something more complicated, gRPC streams can handle it. Previously, this required the creation of a custom TCP-based protocol. This can be a good solution in the datacenter, but it is much less feasible when clients and servers are separated by a WAN or the Internet. When open-source proxies, load-balancing software, and hardware load balancers do not understand the protocol, they are less effective. Even in a datacenter with a fairly homogeneous set of microservices that can all speak the protocol, developing a custom protocol as well as client and server libraries is not trivial. Some of these sophisticated things are possible with HTTP 1.1. The most adaptable and widely used approach is to use web sockets, which allow you to create a custom TCP-based protocol and tunnel it over HTTP connections. However, there is still the cost of developing the protocol and implementing custom clients and servers.
Security: gRPC was created with safety in mind. It is possible to use HTTP/2, and thus gRPC, insecurely over plain text connections. However, when using TLS (transport-level security, also known as SSL), HTTP/2 is more stringent than HTTP 1.1. It only supports TLS 1.2 or higher; numerous cipher suites are blacklisted due to insufficient security; and compression and re-negotiation are disabled. This significantly reduces the number of TLS vulnerabilities to which HTTP/2 connections are vulnerable.
Conclusion
In this post, we defined the context of gRPC's application and gave a brief history of the field's development. After covering the groundwork for HTTP and REST, we looked at the finer points that make gRPC useful in so many contexts. A familiarity with Protocol Buffers is a prereq for working with gRPC, and we'll be covering that in the next post of this series.
Posted on February 7, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



November 12, 2024
